【原创】这次更新比较慢,译码过程比想象中复杂一些,更主要是译出来的DCT系数无法确定是否正确,要想验证就需要再进行正向压缩编码,再次形成jpeg图像验证正确,后续工作正在开展,这里就说一说译码的主要思路和过程。
说到译码过程,首先要了解jpeg图像数据流的组成:
数据流是以MCU(最小编码单元)为基本单位的,一个MCU又由若干个Y,Cr,Cb颜色分量单元组成,这里的颜色分量单元可以看作是一个8*8的矩阵,也就是译码过程中的最小单元了,可能读者对于这些结构的关系还不是很了解,OK,我们来看看下面这个图(word绘制,简洁易懂~)
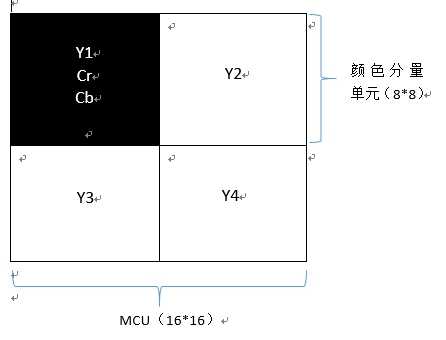
一个MCU中的颜色分量单元个数由jpeg文件头中SOF0段中定义,SOF0段中有定义每个颜色分量的水平和垂直采样因子,这里假设水平,垂直采样因子分别为2:1:1,2:1:1。这个采样因子是什么意思呢,我们来看看上图。假设上图是一个16*16(像素)的图片,可以分成四个8*8的小矩阵,每个8*8小矩阵都是一个颜色分量单元,Y分量的水平采样因子为2则说明在一个MCU的水平方向上采样两次,垂直采样因子同理,因此在本例中一个MCU会有4个Y颜色分量单元,1个Cr颜色分量单元,1个Cb颜色分量单元。从这里我们也能得知一个MCU的大小是由水平、垂直采样因子的最大值决定的,假设分别为V_max和H_max,则MCU的大小为(V_max*8)*(H_max*8)。这些结构的关系如下:
颜色分量单元组成MCU,MCU组成数据流
现在再来看看图片中含有多个MCU的情况,假设有四个,允许我再盗用一下上面的图哈,
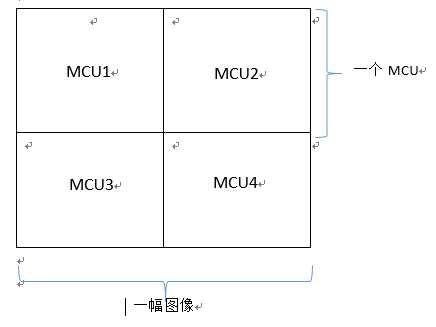
可以看到,一幅图像里MCU是按行排列的,在数据流中保存的顺序就是MCU1、MCU2、MCU3、MCU4。。。。每个MCU中的顺序为Y1、Y2、Y3、Y4、Cr、Cb(这里是按采样因子4:1:1,其他也类似,总之就是按Y、Cr、Cb的顺序)。
了解了数据流的组成,下面就要开始译码工作了,这也是个烦杂的过程。。。。
在JPEG压缩过程中,不仅使用了哈夫曼编码,还使用了RLE行程编码和差分编码,真是极尽压缩啊。。。这三种编码在JPEG中是综合运用的,可以达到很好的压缩效果。本人这里就从解码的角度来进行介绍了,个人觉得从解码角度来理解更为方便~
首先,JPEG中直流和交流系数是分开进行编码的,也就是说译码的过程有些许不同,而且采用的哈夫曼树也是不同的,其次,JPEG中的每个颜色分量也是分开进行编码的,不同颜色分量采用的哈夫曼树也是不同的,具体的每个颜色分量的交直流系数采用的哈夫曼树ID可以从文件头的SOF0段中得知,SOF0段的内容可以看我的另一篇博文
http://www.cnblogs.com/gungnir2011/p/3615273.html
在数据流中是以bit为单位存储信息的,每个DCT系数(8*8)矩阵都有1个直流分量和63个交流分量,每个矩阵的译码都先译直流分量,再译交流分量,具体的步骤如下:
1.按bit读取,对直流哈夫曼树进行搜索,直到搜索到叶子节点,说明这时命中了一个编码,哈夫曼树的权值代表还需继续读取多少bit,比如权值为0x04,则说明继续读取4bit,这4bit的值根据译码表(后面会给出)获取的值就是直流DCT系数。
2.继续按bit读取,这时是对交流哈夫曼树进行搜索,直到叶子节点,这里的权值和直流不一样,权值的高四位代表即将译出的交流DCT系数前面有多少个0,这里是行程编码,低四位代表还需继续读取多少bit,之后获得系数和直流一样。
3.不断重复步骤2,直到满足结束条件:
译码表:
| 编码数值 | 实际数值 |
| 0,1 | -1,1 |
| 00,01,10,11 | -3,-2,2,3 |
| 000,001,010,011,100,101,110,111 | -7,-6,-5,-4,4,5,6,7 |
| ................. | ...................... |
之后就是译完一个矩阵译下一个,译完一个颜色分量译下一个,直到所有译完~~
当然这只是理论,在实践过程中会遇到各种奇葩问题,下次更新中会详细说说我遇到的各种奇葩错误,现在还未完全写完译码部分,为了进度现在直接在研究libjpeg开源库,之后可能会找个时间把译码做完,未完待续~~
JPEG图像密写研究(三) 数据流译码,布布扣,bubuko.com
原文:http://www.cnblogs.com/gungnir2011/p/3624715.html