前言
WHY 云:为什么我们须要云。大数据时代我们面对两个问题,一个是大数据的存储。一个是大数据的计算。
由于数据量过大,在单个终端上运行效率过差,所以人们用云来解决这两个问题。
WHAT IS 云:云得益于分布式计算的思想。举个简单的样例。运行一千万个数据每一个数据都乘以10并输出,在个人pc上须要大概20分钟。假设是100台电脑做这个工作。可能仅仅用几十秒就能够完毕。云就是我们将复杂的工作通过一定的算法分配给云端的n个server,这样能够大大提高运算效率。
How 云:云的实现也就是分步式计算的过程。分布式的思想起源于MapReduce,是google最先发表的一篇论文中提到的。如今非常多的分布式计算方法都是从中演变过来的。大体的思路是。将任务通过map分离——计算——合并——reduce——输出。
云的价值不光是存储数据。更是用来分析和处理数据,得益于云。很多其它的算法能够快捷的实现。所以说云计算和大数据倔是不可切割的,可能大家在平时的学习过程中还没有机会在云端接触大数据运算。以下就分享一下本人的一次云计算的经历。
1.背景
这是博主第一次大数据实战的经历,之前都是自己写一些算法然后測试非常小的数量级。这次是真正接触到TB集的数据。并且全然是在云端处理。以下就把这次的经历简单分享一下。
首先简介一下这次比赛的环境吧:
1.云:採用的是阿里云
2.数据:从四月十五号到八月十五号期间,用户两千多万的购买行为(包含时间。购买、收藏、购物车的次数)
3.工具:阿里提供的xlab(里面有非常多算法。随机森林、逻辑回归、knn等)、odps(也就是sql数据库)、mapreduce环境(java分布式计算)、udf(主要是提供sql的一些function功能)。
4.目的:预測八月十五号之后的用户行为。
2.工具的简单说明
(1)odps
这个主要是sql数据库的一些简单操作。sql玩的溜的大神们都能够用sql语句实现非常多的算法,当然博主仅仅能用sql合并表、简单查询之类的。比方我们实现一个简单的查询去重的功能,odps能够通过分布式计算将任务量分不给非常多云端server,然后高速的运行大数据的查询工作。差点儿相同三百多万的数据查询仅仅用一分钟就解决的,假设要是离线測试,预计得几十分钟。这就是云的魅力。
select distinct * from table_name;

(2)mapreduce
mapreduce简称mr,主要是实现一些复杂的逻辑的时候使用。比方说像是一些算法。我们使用mr实现算法,能够通过配置文件设置一些分布式的规则,然后将jar文件post到云端就实现了云计算。
上一张mr的图片。
3.TRY
由于这次比赛的奖金非常高。阿里组织的也非常靠谱,所以參赛的队伍实力都非常强的。看眼排行榜就知道了。博主码农大学(北邮)还在两百多名徘徊
(1)第一次尝试-尿布与啤酒的幻想破灭
做推荐系统的应该都知道尿布与啤酒的故事。这是一个协同过滤的问题。非常多大的电商站点都是通过icf也就是关于商品的协同过滤来进行推荐的。博主最早也是通过聚类算法。找出了一些志趣相投的人(买同样品牌的商品的人),详细的实现是通过xlab里的聚类算发还有udf实现的。结果是准确率不到百分之中的一个。不知道是我的方法不正确还是本来这样的数据集不适合用cf。
(2)利用规则
由于博主是金牌买家。所以将心比心。我们能够轻易的得出几个规则可能准确率比較高。
规则一:用户每一个月都会购买的商品
规则二:用户最后一个月点击n次的商品
规则三:用户购买次数超过k的商品
利用这些规则推荐,尽管也能取得一个相对不错的结果,可是想更进一步就要通过算法了。 (3)算法:随机森林
什么是随机森林。就是用非常对决策树来实现的数据集的分类预測,详细的算法例如以下。
算法的主要思想就是将数据集依照特征对目标指数的影响由高到低排列。行成一个二叉树序列,进行分类。如今的问题关键就是,当我们有非常多特征值时。哪些特征值作为父类写在二叉树的上面的节点,哪下写在以下。我们能够直观的看出上面的特征值节点应该是对目标指数影响较大的一些特征值。那么怎样来比較哪些特征值对目标指数影响较大呢。这里引出一个概念,就是信息熵。
信息理论的鼻祖之中的一个Claude E. Shannon把信息(熵)定义为离散随机事件的出现概率。说白了就是信息熵的值越大就表明这个信息集越混乱。
信息熵的计算公式,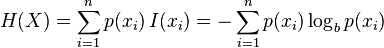 (建议去wiki学习一下)
(建议去wiki学习一下)
这里我们通过计算目标指数的熵和特征值得熵的差。也就是熵的增益来确定哪些特征值对于目标指数的影响最大。
第一部分-计算熵:函数主要是找出有几种目标指数。依据他们出现的频率计算其信息熵。
- def calcShannonEnt(dataSet):
- numEntries=len(dataSet)
-
- labelCounts={}
-
- for featVec in dataSet:
- currentLabel=featVec[-1]
-
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel]=0
- labelCounts[currentLabel]+=1
- shannonEnt=0.0
-
- for key in labelCounts:
-
- prob =float(labelCounts[key])/numEntries
- shannonEnt-=prob*math.log(prob,2)
-
- return shannonEnt
第二部分-切割数据 由于要每一个特征值都计算对应的信息熵,所以要对数据集切割。将所计算的特征值单独拿出来。
- def splitDataSet(dataSet, axis, value):
- retDataSet = []
- for featVec in dataSet:
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis]
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
第三部分-找出信息熵增益最大的特征值
- def chooseBestFeatureToSplit(dataSet):
- numFeatures = len(dataSet[0]) - 1
- baseEntropy = calcShannonEnt(dataSet)
- bestInfoGain = 0.0; bestFeature = -1
- for i in range(numFeatures):
- featList = [example[i] for example in dataSet]
-
- uniqueVals = set(featList)
-
- newEntropy = 0.0
- for value in uniqueVals:
- subDataSet = splitDataSet(dataSet, i, value)
- prob = len(subDataSet)/float(len(dataSet))
- newEntropy += prob * calcShannonEnt(subDataSet)
- infoGain = baseEntropy - newEntropy
-
- if (infoGain > bestInfoGain):
- bestInfoGain = infoGain
- bestFeature = i
- return bestFeature
- def createTree(dataSet,labels):
-
- classList = [example[-1] for example in dataSet]
-
- if classList.count(classList[0]) == len(classList):
- return classList[0]
- if len(dataSet[0]) == 1:
- return majorityCnt(classList)
-
- bestFeat = chooseBestFeatureToSplit(dataSet)
- bestFeatLabel = labels[bestFeat]
-
- myTree = {bestFeatLabel:{}}
-
- del(labels[bestFeat])
- featValues = [example[bestFeat] for example in dataSet]
- uniqueVals = set(featValues)
-
- for value in uniqueVals:
- subLabels = labels[:]
-
- myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
- return myTree
4.详细实现
以上是用python写的决策树算法,在比赛中xlab工具已经提供这些底层的算法,基本的工作是要特征值选择和调试參数。
除了数据集提供的基本的几个參数以外,主要是通过一些特征间的组合又找出了十个左右的特征。
(1)特征提取
我的经验是在特征组合的时候,假设某个值的区间特别大。我们能够使用log函数来处理。比方说data的数值是1-100。而click的数值是0-3。假设这个时候我们直接提取特征data_click=click/data的话,可能会造成曲线波动比較大。这个时候能够用log函数。data_click=ln(1+data)来提取特征,会使曲线变得更加平滑。 特征值得平方是个不错的选择。由于y=x+1是一条直线。而假设是 ,就会变为一条曲线。更easy实现拟合。
,就会变为一条曲线。更easy实现拟合。
(2)随机森林參数调试
主要是设置树的数量和深度。数量就是使用决策树的数量,这个一般来讲数量较大效果比較好,我是用了100棵。深度是指每棵决策树的深度,这个特征值假设多就多设置一些。我是有15个特征值,深度设为4。秀一下我的决策树:
5.总结
有一本书叫机器学习与实战,感觉挺不错的。自己用代码实现算法会加深理解。
也能够訪问我的github (github.com/jimenbian,里面有非常多算法的实现。
(github.com/jimenbian,里面有非常多算法的实现。 斯坦福的机器学习公开课也非常好。
版权声明:本文博客原创文章,博客,未经同意,不得转载。


