1、在配置文件schema.xml(位置{SOLR_HOME}/config/下),配置信息如下:
<!-- IKAnalyzer 中文分词-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
2、在IKAnalyzer相关的jar包(IKAnalyzer2012_u6.jar 本博客不提供下载)放在{SOLR_HOME}/lib下。
3、测试IKAnalyzer中文分词 效果:
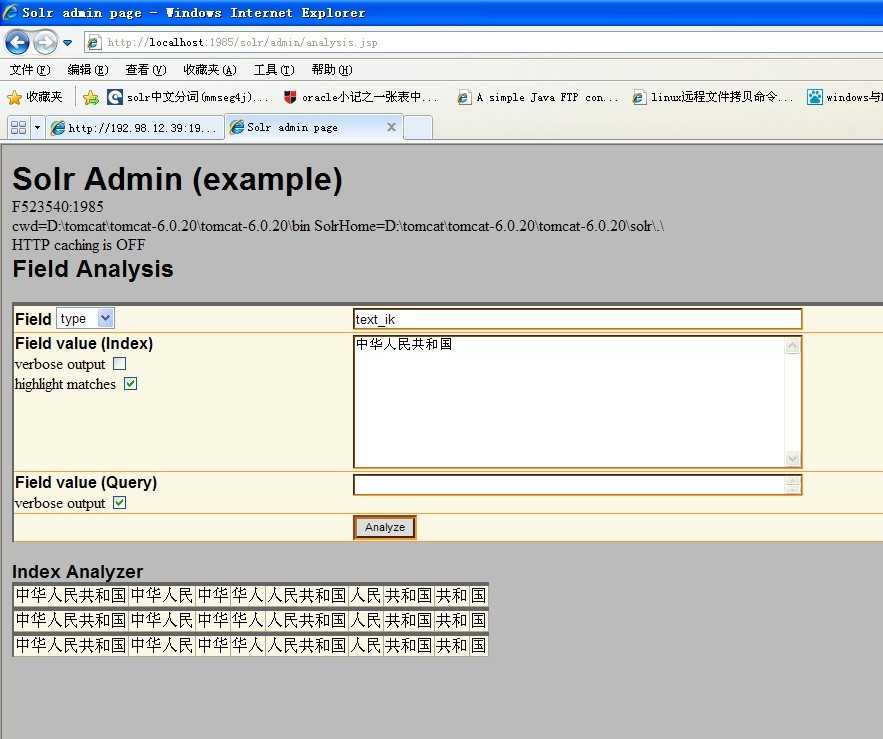
ikanlyzer分词效果还是不错的 ,通过配置可以扩展个人词典、自定义停顿词等。配置信息如下:
IKAnalyzer.cfg.xml配置文件
把stopword.dic和IKAnalyzer.cfg.xml复制到class根目录就可以启用停用词功能和扩展自己的词典
<?xmlversion="1.0"encoding="UTF-8"?>
<!DOCTYPEpropertiesSYSTEM"http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entrykey="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entrykey="ext_stopwords">stopword.dic;</entry>
</properties>
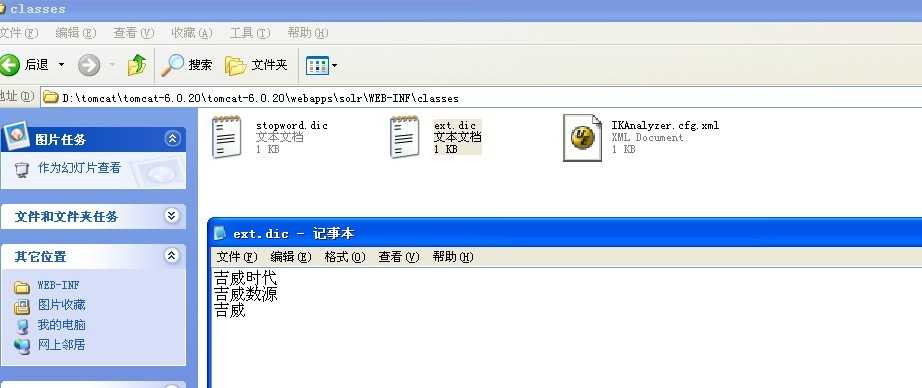
如果想在solr中使用IK来加载扩展词典,需要将以上的配置文件和词典扩展文件放在tomcat/webapps/solr/WEB-INF/classes下。同时,比如我的ext.dic中有以下内容:
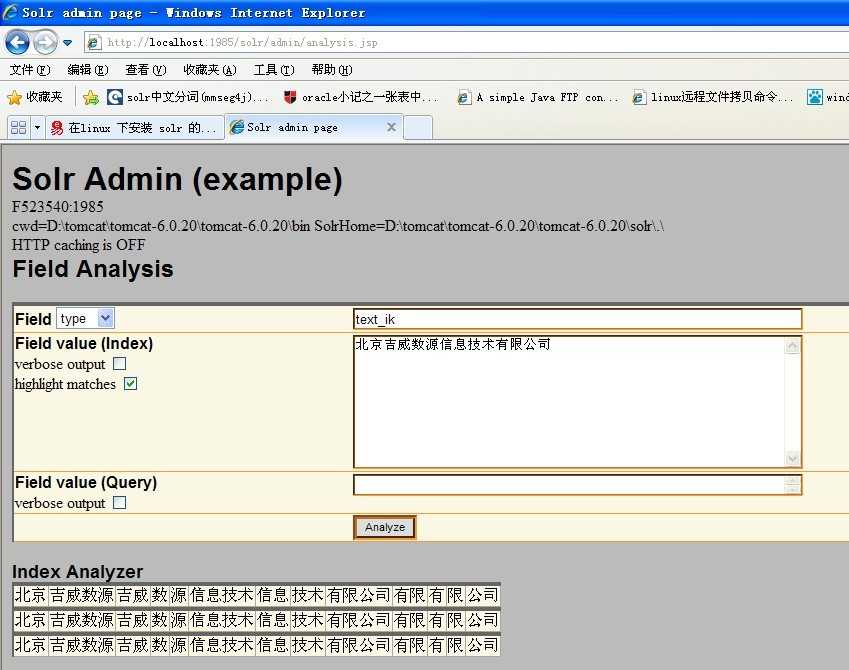
那么在solr中分词效果便是:
原文:http://www.cnblogs.com/lvfeilong/p/234ddfg.html