以前有个学科叫数据挖掘,用于对规律不明确的数据做分析,聚类正是这门学科的基础。
我们普通人对一组数据做分析的时候,往往会大概的对数据画个范围,比如统计1-50,50-100,100-200分别有多少记录之类,
而聚类则是用于替代人手工做这个工作。
比如有一组数据,聚类则可以通过算法分析出这组数据的分段和每段的记录统计。
而对这组数据的规律的研究方式,可以分为划分方法,层次方法,基于密度的方法,基于网格的方法,基于模型的方法
我现在随意写个基于划分的方法的聚类模板
大家玩耍下
def censusdata(key, census, weight=lambda e : e):
if census.has_key(key):
return census[key]
data_len = len(census[‘data‘])
census[‘data‘].sort(key=lambda e : e[key])
max = census[‘data‘][-1][key]
min = census[‘data‘][0][key]
prev = None
span_list = []
for i in xrange(data_len):
if prev is not None:
span_prev = float((weight(census[‘data‘][i][key]) - prev))/prev
span_next = float((weight(census[‘data‘][i][key]) - prev))/weight(census[‘data‘][i][key])
span_list.append(math.sqrt(pow(span_prev,2)+pow(span_next, 2)))
prev = weight(census[‘data‘][i][key])
average_diff = 0
count = 0
for i in xrange(len(span_list)):
if span_list[i] > 0:
average_diff = average_diff + span_list[i]
count += 1
average_diff = average_diff/count
cut_off_point = []
for i in xrange(len(span_list)):
if average_diff < span_list[i]:
cut_off_point.append((census[‘data‘][i][key], census[‘data‘][i+1][key]))
span_list[i] = None
cut_off_point.sort(key=lambda e : e[0])
refer_separation = [{"min":min, "max":cut_off_point[0][0], "data":[]}]
for i in xrange(len(cut_off_point)-1):
refer_separation.append({"min":cut_off_point[i][1], "max":cut_off_point[i+1][0], "data":[]})
refer_separation.append({"min":cut_off_point[-1][1], "max":max, "data":[]})
for cut in refer_separation:
for i in xrange(data_len):
if cut[‘min‘] <= census[‘data‘][i][key] and cut[‘max‘] >= census[‘data‘][i][key]:
cut[‘data‘].append(census[‘data‘][i])
census[key] = refer_separation
return census
这段算法,在对数据做排序之后,简单的计算了(对比前2个数据)当前数据和前一个数据之间变化的幅度,然后以这个幅度变化大小做为关键值对排好序的数据做分段,
编辑一组简单的数据做个测试如下:
censuss = {‘data‘:[{"key":10000}, {"key":9000}, {"key":8000},{"key":8000},{"key":8000},{"key":8000},{"key":8000},{"key":8000},{"key":8000},{"key":8000}, {"key":7000},
{"key":1000}, {"key":900}, {"key":800},{"key":800},{"key":800},{"key":800},{"key":800},{"key":800},{"key":800},{"key":800}, {"key":700},
{"key":300},{"key":300},{"key":300},{"key":300},{"key":300},{"key":300}, {"key":310},{"key":320},{"key":309},{"key":301},{"key":400},{"key":500},
{"key":100}, {"key":100},{"key":100},{"key":100},{"key":100},{"key":100},{"key":60},{"key":80},{"key":50},{"key":40},{"key":30},
{"key":3},{"key":3},{"key":3},{"key":3},{"key":3},{"key":3},{"key":3},{"key":3}]}
censusdata(‘key‘, censuss)
for e in censuss[‘key‘]:
print e
censusdata(‘key‘, censuss[‘key‘][1])
for e in censuss[‘key‘][1][‘key‘]:
print e
执行之后结果如下:
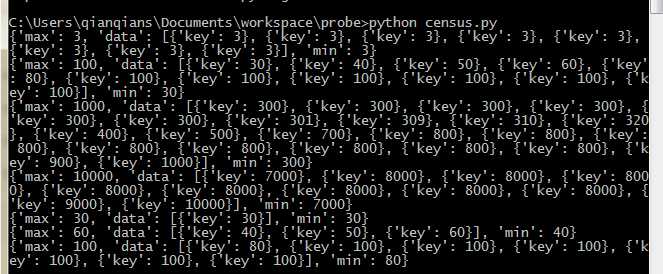
数据已经被合理的分段,并且统计出当前段的最大值,和最小值,以及段内的记录。
原文:http://www.cnblogs.com/qianqians/p/4529484.html