基于用户的协同过滤,基于的假设是:喜欢相同物品的用户具有相似性。
相同物品越多,用户相似性越大。(有点基于统计的意思)
基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
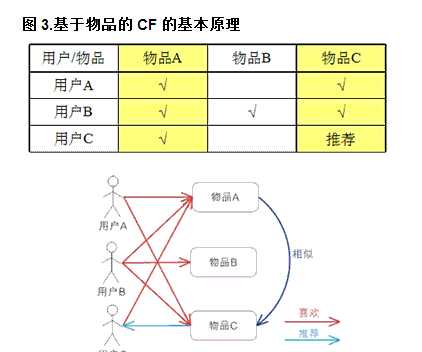
基于项目的协同过滤,基于的假设是:同一个人喜欢的几个物品具有相似性。
userA喜欢A C
userB喜欢A C
》》则A C具有相似性,同时喜欢的用户越多,说明A C相似性越大。(有点基于统计的意思)
参考:IBM 深入推荐引擎相关算法 - 协同过滤
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
推荐系统协同过滤基于的两种假设
原文:http://www.cnblogs.com/jxhuang/p/4508358.html