什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。同时,这个语言也允许熟悉 MapReduce? 开发者的开发自定义的 mapper? 和 reducer? 来处理内建的 mapper 和 reducer? 无法完成的复杂的分析工作。
为什么使用Hive
学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive 系统架构

?
用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行
JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问 Hive
Metastore(Hive的元数据)
元数据包含了Hive包表的表名、字段分区属性等表的属性信息
默认使用Derby数据库作为默认的元数据仓库(嵌入式,只支持单session回话)
?
Hive与传统数据的对比
| ? |
Hive |
RDBMS |
|
查询语言 |
HQL |
SQL |
|
数据存储 |
HDFS |
Raw Device or Local FS |
|
执行 |
MapReduce |
Excutor |
|
执行延迟 |
高 |
低 |
|
处理数据规模 |
大 |
小 |
|
索引 |
0.8版本后加入位图索引 |
有复杂的索引 |
?
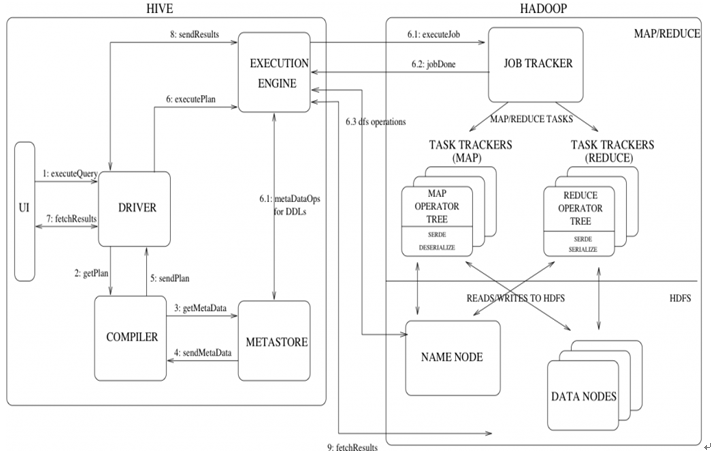
Hive与hadoop 的调用关系
Hive安装
1.???? 下载hive源文件
2.???? 解压hive文件
3.???? 进入$HIVE_HOME/conf/修改文件
a)???? cp? hive-env.sh.template? hive-env.sh
b)???? cp? hive-default.xml.template? hive-site.xml
4.???? 修改$HIVE_HOME/bin的hive-env.sh,增加以下三行
a)???? export JAVA_HOME=/usr/local/jdk1.7.0_45
b)???? export HIVE_HOME=/usr/local/hive-0.14.0
c)???? export HADOOP_HOME=/usr/local/hadoop-2.6.0
5.???? 伪分布模式使用默认的Derby就可以直接启动Hive控制台了,但一般都会修改为MySQL
修改$HIVE_HOME/conf/hive-site.xml
<property>
????? <name>javax.jdo.option.ConnectionURL</name>
????? <value>jdbc:mysql://192.168.1.100:3306/crxy_job?
?????????? ??? createDatabaseIfNotExist=true</value>
</property>
<property>
????? <name>javax.jdo.option.ConnectionDriverName</name>
????? <value>com.mysql.jdbc.Driver</value>
</property>
<property>
????? <name>javax.jdo.option.ConnectionUserName</name>
????? <value>root</value>
</property>
<property>
????? <name>javax.jdo.option.ConnectionPassword</name>
????? <value>admin</value>
</property>
将MySQL的驱动包jar文件存放在HIVE_HOME/lib下
启动Hive,现在就可以执行Sql语句创建表了!
?
?更多精彩内容请关注:http://bbs.superwu.cn
关注超人学院微信二维码:
原文:http://crxy2016.iteye.com/blog/2210179