1、基于storm的爬虫系统:
大体框架:
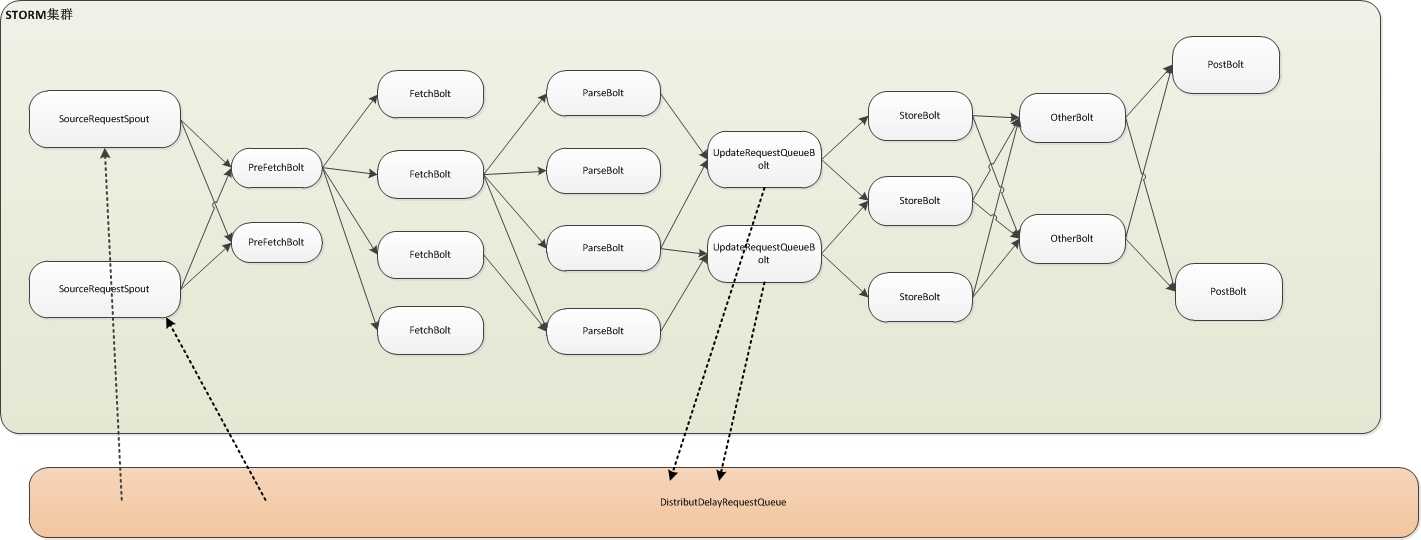
众所周知,爬虫系统里几个必不可少的模块,像下载、解析、回写待爬资源、存储等,本质上他们像是一个责任链,但后一个module又基于前一个module,所以可以理解为一种流处理模型,从我们拿到待爬URL一直到处理完毕存储数据,这是一个完整的过程。如您看到的这张图,如果我们实现了storm化,那么基于storm强大的功能,我们的爬虫可以完美运行在storm集群上,并且每类处理器我们都可以非常灵活的分配其线程数,耗时的处理我们多开几个线程,可以实现资源合理利用,当然既然是集群,你的某个任务具体运行在哪里,storm已经帮您分配好了,并且帮我们实现了节点失效等处理。
最后如果bolt间传输的消息量比较大,有可能网络是个瓶颈。
参考链接:
原文:http://www.cnblogs.com/xymqx/p/4372533.html