PL/Proxy 介绍
-
一、概述
-
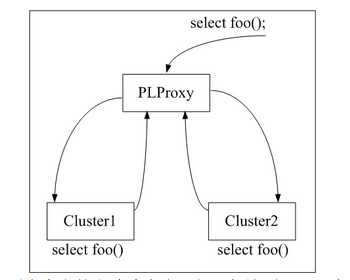
1.PL/Proxy 是一个采用PL Language语言的数据库分区系统。
- 它的理念是代理远程函数体内指定。函数调用同样标签创建的函数,所以,代理的目标信息需要在代理函数体内指定。
- plproxy是skype开发的一个数据库组件
- plproxy能够在PostgreSQL上运行的一种过程语言,能够完成对远程数据库的调用,并能够完成数据切片的功能。
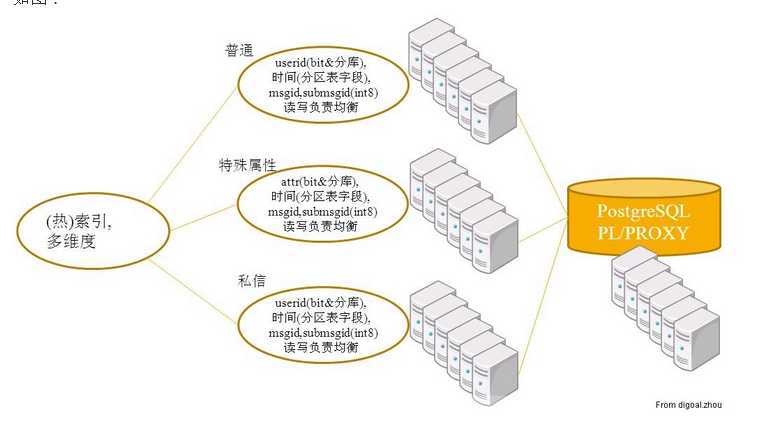
- 一个实例描述:Thinking PostgreSQL PL/Proxy Used in weibo(微博) Case
- 以三台机器的集群为例子,PostgreSQL集群的架构
- proxy节点:proxy节点实际上也是一个PostgreSQL数据库 节点,但是所有数据均不存放到proxy节点上,主要做三件事情:
- 1).接受用户的sql查询;
- 2).分析用户的sql查询并转换成集群上执行的SQL语句;
- 3).合并集群执行sql的结果,然后返回给用户。
- 说白了,就是把用户的sql语句交给database0,database1去执行,然后合并执行结果返回给用户。
- database1节点和 database2节点:就是普通的数据库节点,接收proxy节点的sql查询请求并返回结果给proxy节点,是真正存放数据的节点。
-
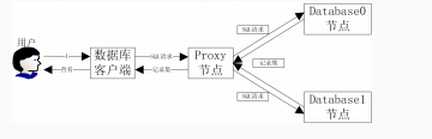
- 体系结构如上所示,案例实际配置和过程参考
-
2.特性
- 1)PL/Proxy 函数从自己的标签中检测远程函数调用
- 2)函数可以是一个,也可以是集群中的某一个
- 3)如果查询被分割, 它将并发执行
- 4)查询在远程服务器上运行在自动提交模式下
- 5)查询参数与查询体分开传送,因此避免了在两端的quoting/unquoting 开销
- 6)不包含代码连接池,如果需要,可采用外部池程序。
-
3.个人理解:pl/proxy不是一个软件,与pgbouncer和pgpool不同。只是个在PostgreSQL数据库基础之上添加一些.sql文件,通过数据库执行这些文件最后实现集群的功能,而且能实现数据插入的负载均衡,这与pgxc插入数据时有点相似,它使用一种随机算法或者轮循方式将数据插入到数据节点当中。
-
通俗的介绍:PL/Proxy方式的集群是这样的:有很多安装了PostgreSQl数据库的计算机,有台计算机是头头,我们把这个头头叫做proxy,其他的叫做database0,database1……。当然名字叫什么是无所谓的,关键是有个是头头,其他的受头头指挥。
-
二、数据流的处理过程
- 三、安装经验和实验体会
- 5.然后在代理节点中创建schema: create schema plproxy
- 6.在代理节点上初始化一些函数模板,将一些目标放到一个.sql文件里(如URTClusterInit.sql),然后在代理节点中psql -f URTClusterInit.sql -d URTCluster -h 10.0.0.1(代理节点的IP)
- 7.在各个数据库节点中创建一张表,而且是一模一样的表
- 8.然后给每个数据库节点创建一个插入数据的函数
- 9.把函数保存在 URTClusterNodesInit_1.sql文件里,并执行
- psql -f URTClusterNodesInit_1.sql -h 10.0.0.2(数据库节点1IP) -d URTCluster
- psql -f URTClusterNodesInit_1.sql -h 10.0.0.3 (数据库节点1IP)-d URTCluster
- 10.在代理节点上创建上面同样的插入数据函数,并创建一个查询函数,用于进行集群检索,将这些都保存在一个URTClusterProxyExec.sql文件里,并执行psql -f URTClusterProxyExec_1.sql -h 10.0.0.1(代理节点IP) -d URTCluster
- 11.测试
- 1)在代理节点上通过psql客户端登陆psql -d URTCluster 数据库
- 2)然后可以通过调用插入数据函数和查询数据函数对集群进行操作
- 四、一些配置文档:
PL/Proxy介绍
原文:http://www.cnblogs.com/eagle-dtq/p/4290290.html