假设一个场景,需要连接两个很大的数据集,例如用户日志和OLTP的用户数据。任何一个数据集都不是足够小到可以缓存在map作业的内存中。这样看来,你似乎就不能使用reduce端的连接了。尽管不是必须,你可以问问你自己一下问题:如果一个数据集中有的记录因为无法连接到另一个数据集的记录,将会被移除,还需要将整个数据集放到内存中吗?在这个例子中,在用户日志中的用户仅仅是OLTP用户数据中的用户中的很小的一部分。那么就可以从OLTP用户数据中取出存在于用户日志中的那部分用户的用户数据。这样就可以得到足够小到可以放在内存中的数据集。这样的解决方案就叫做半连接。
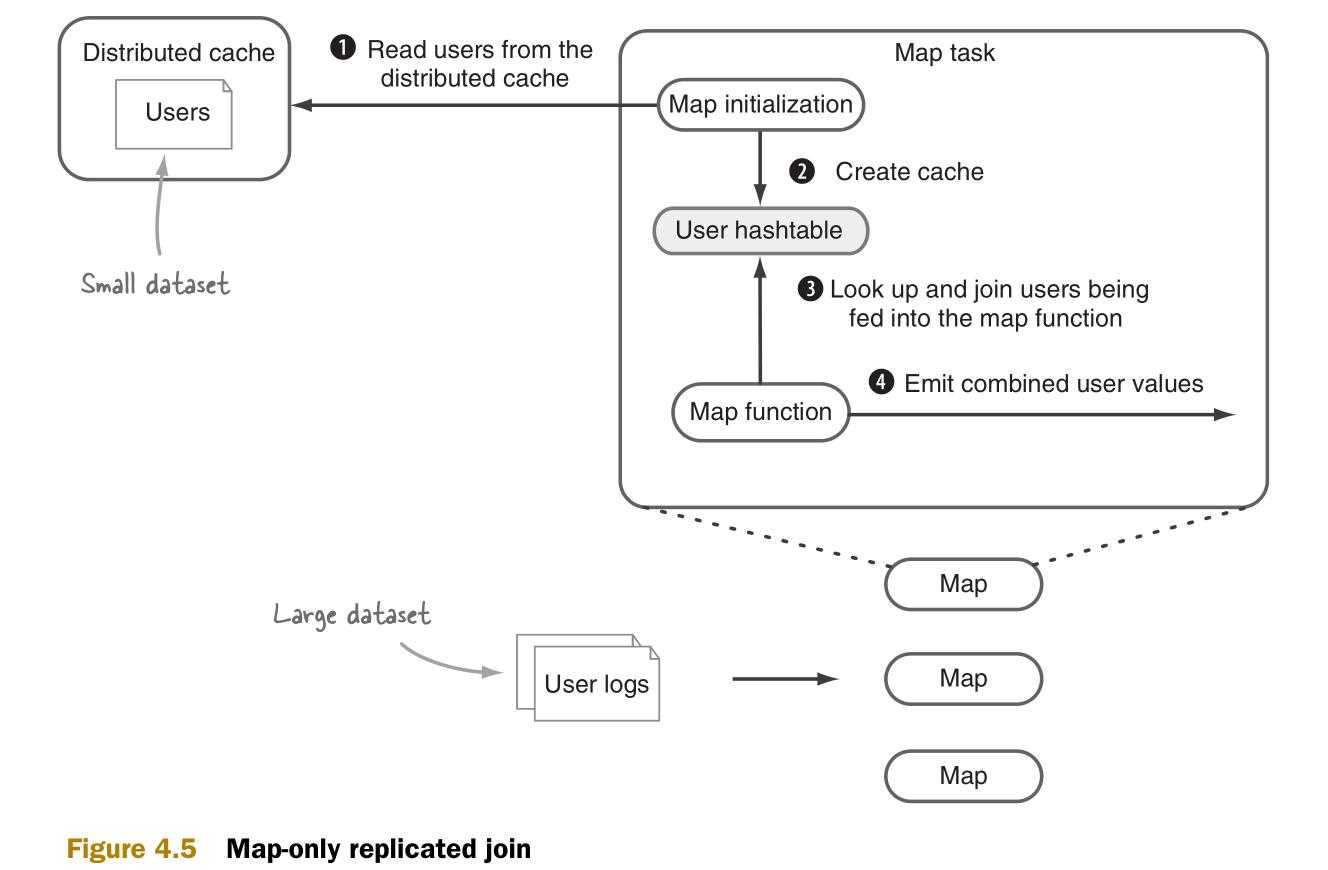
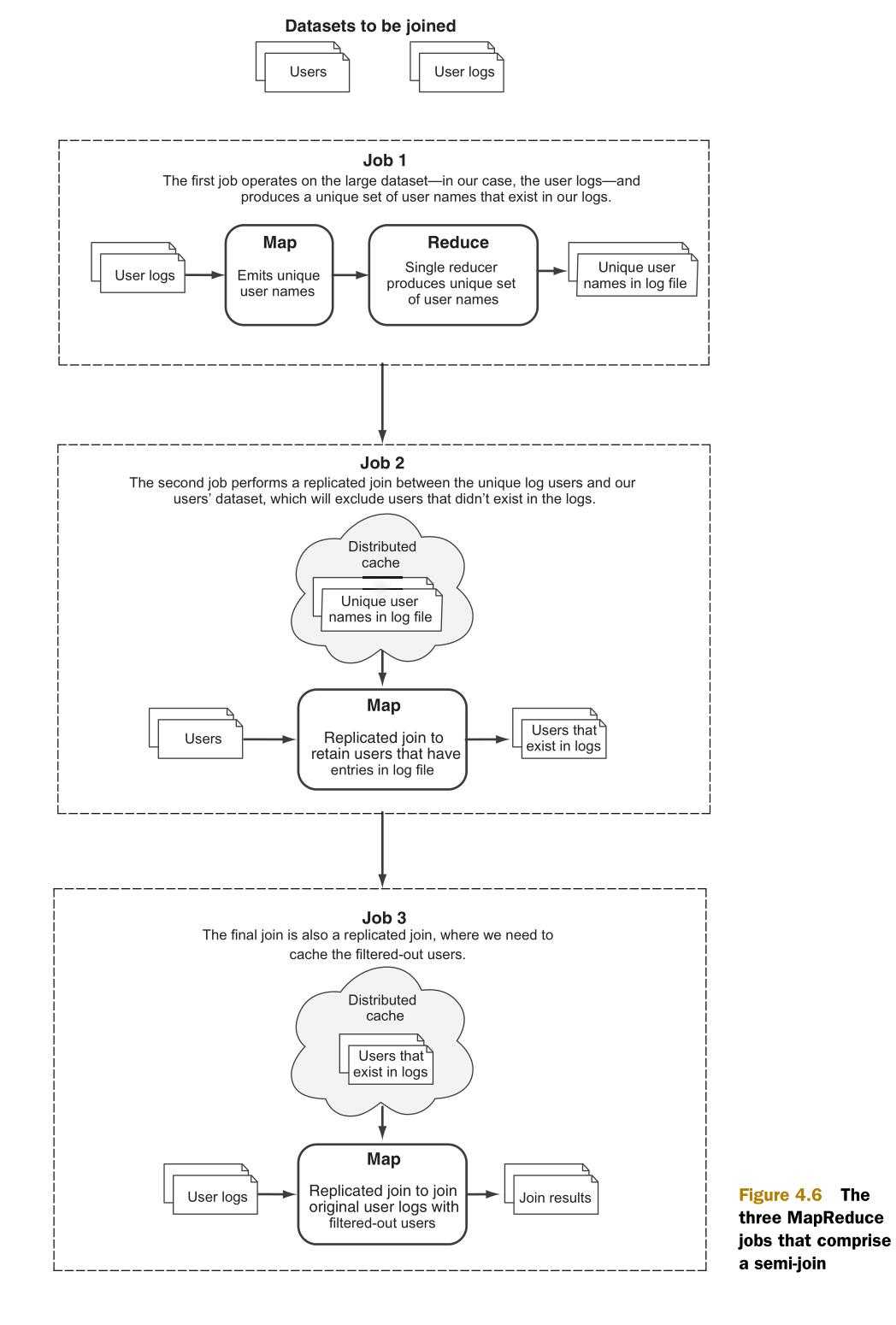
图4.6说明了在半连接中将要执行的三个MapReduce作业(Job)。
让我们看看如何实现一个半连接。
当面对连接两个大数据集的挑战时,很容易想到要用重分区连接,也就是利用了整个MapReduce框架的reduce端的连接。如果你这么想了,又不能够将其中一个数据集过滤到一个较小的尺寸以便放到map端的内存中,这将只是你一个人的想法而已。然而,如果你认为你能够将一个数据集减小到一个可管理的大小,也许就用不着使用重分区连接了。
问题:
需要连接两个大的数据集,同时减少整理和排序阶段的消耗。
解决方案:
在这个技术中,将会用到三个MapReduce作业来连接两个数据集,以此来减少reduce端连接的消耗。对于大数据集,这个技术非常有用。
讨论:
在这个技术中,将会用到附录D中的复制连接(Replicated join)的代码来实现MapReduce作业中的最后两部。同时,在图4.6中的三个作业将会被拆解。
作业1:
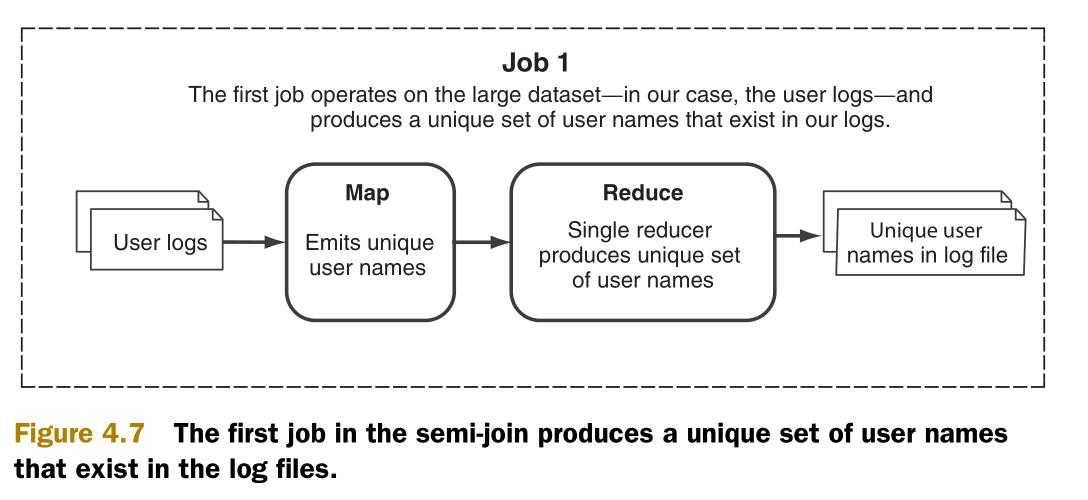
第一个MapReduce作业的功能是从日志文件中提取出用户名,用这些用户名生成一个用户名唯一的集合(Set)。这通过让map函数执行了用户名的投影(projection)操作。然后用reducer输出用户名。为了减少在map阶段和reduce简短之间传输的数据量,就在map任务中采用哈希集(HashSet)来保存用户名,在cleanup方法中输出哈希集的值。图4.7说明了这个作业的流程。
这个MapReduce作业中的代码如下:

1 public static class Map extends Mapper<Text, Text, Text, NullWritable> { 2 3 private Set<String> keys = new HashSet<String>(); 4 5 @Override 6 protected void map(Text key, Text value, Context context) 7 throws IOException, InterruptedException { 8 keys.add(key.toString()); 9 } 10 11 @Override 12 protected void cleanup(Context context) 13 throws IOException, InterruptedException { 14 15 Text outputKey = new Text(); 16 17 for(String key: keys) { 18 outputKey.set(key); 19 context.write(outputKey, NullWritable.get()); 20 } 21 22 } 23 24 } 25 26 public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> { 27 28 @Override 29 protected void reduce(Text key, Iterable<NullWritable> values, Context context) 30 throws IOException, InterruptedException { 31 context.write(key, NullWritable.get()); 32 } 33 34 }
第一个作业的结果就是来自于日志文件中的所有用户的集合。集合中的用户名是唯一的。
作业2:
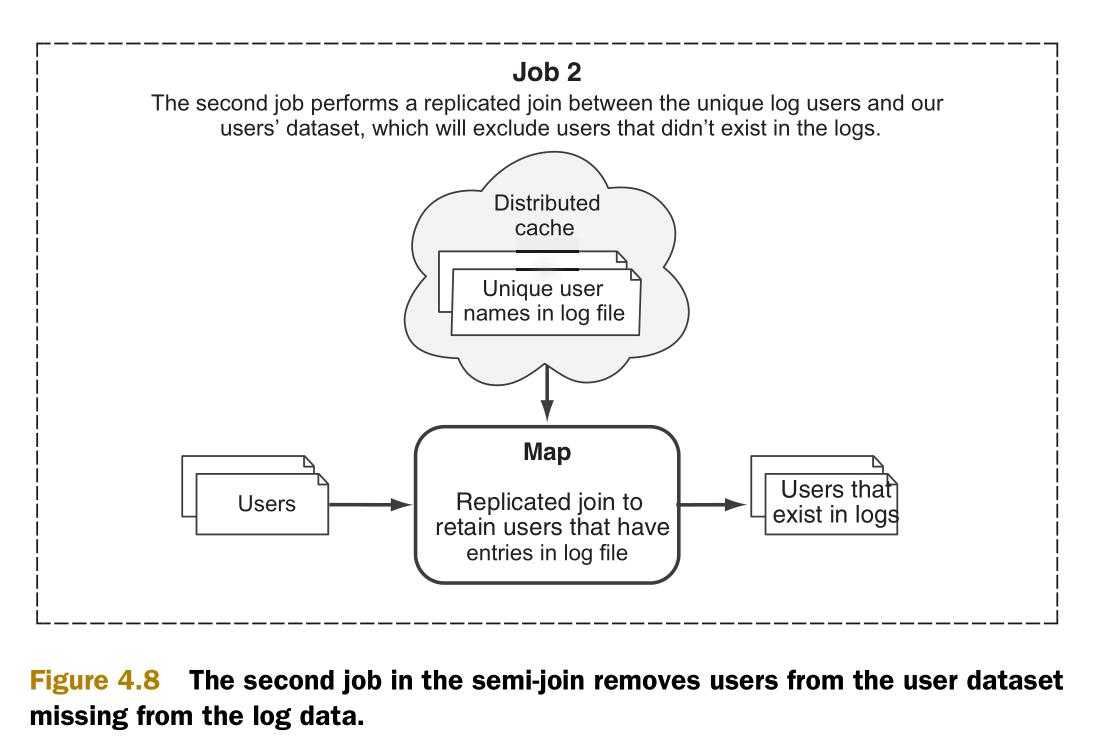
第二步是一个复杂过滤的MapReduce作业。目标是从全体用户的用户数据集中移除不存在于日志文件中的用户。这是一个只包含map的作业。它用到了复制连接来缓存出现在日志文件中的用户名,并把他们和全体用户的数据集连接。来自于作业1的用户唯一的数据集要远远小于全体用户的数据集。很自然的就把小的那个数据集放到缓存中了。图4.8说明了这个作业的流程。
如果你还对附录D中的复制连接框架还不熟悉,那现在快速浏览一下刚刚好。这个框架对 KeyValueTextInputFormat 和 TextOutputFormat 提供了内置支持,并假设 KeyValueTextInputFormat 生成的键是连接键。如此,这也就是数据被展开的过程。图4.9时这个框架的类图。
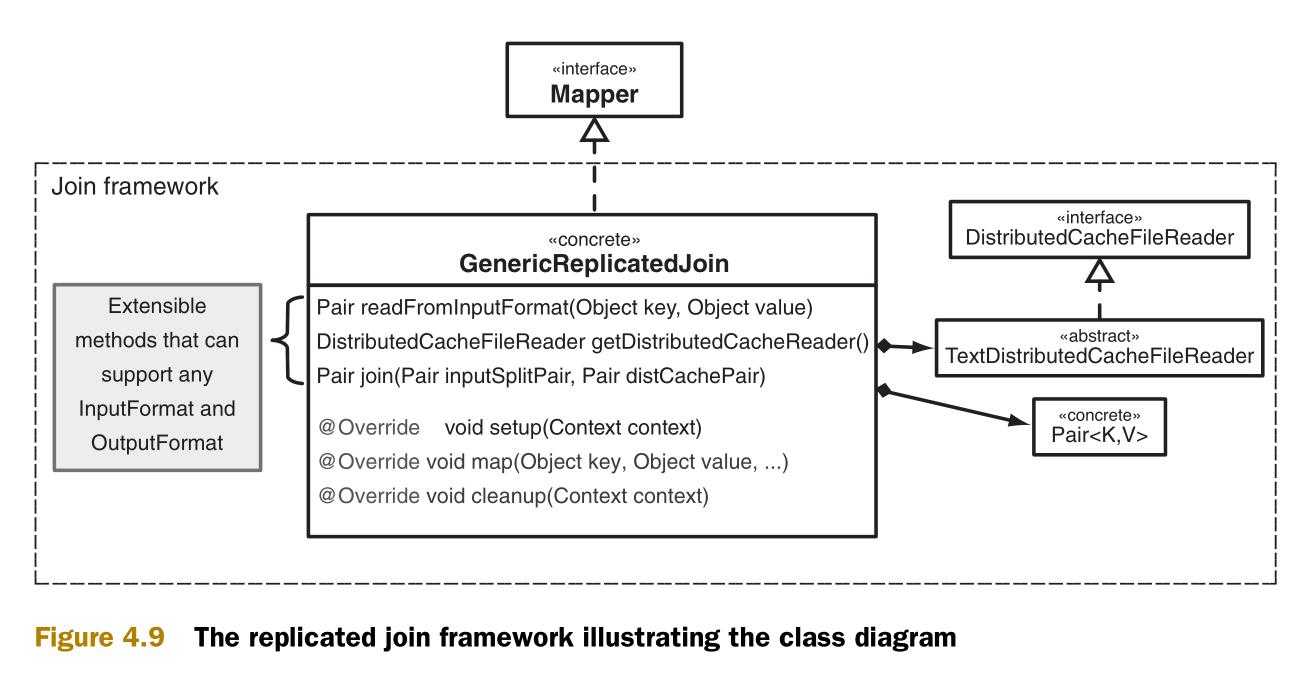
GenericReplicatedJoin 类是执行连接的类。如图4.9中所示,在 GenericReplicatedJoin 的类列表中前三个类是可扩展的,相对应的复制链接的行为也是可定制的。readFromInputFormat 方法可以用于任意的输入类型(InputFormat)。getDistributedCacheReader 方法可以被重载来支持来自于分布式缓存(distributed cache)的任意文件类型。在这一步中的核心是join方法。join方法将会生成作业的输出键和输出值。在默认的实现中,两个数据集的值将会被合并以生成最终的输出值。你可以改变这个行为,变成值输入来自于用户表的数据,如下所示:
1 public class ReplicatedFilterJob extends GenericReplicatedJoin { 2 3 @Override 4 public Pair join(Pair inputSplitPair, Pair distCachePair) { 5 return inputSplitPair; 6 } 7 8 }
你还需要把来自于作业1的文件放到分布式缓存中:
1 for(FileStatus f: fs.listStatus(uniqueUserStatus)) { 2 if(f.getPath().getName().startsWith("part")) { 3 DistributedCache.addCacheFile(f.getPath().toUri(), conf); 4 } 5 }
然后,再驱动(driver)代码中,调用 GenericReplicatedJoin 类:
1 public class ReplicatedFilterJob extends GenericReplicatedJoin { 2 3 public static void runJob(Path usersPath, 4 Path uniqueUsersPath, 5 Path outputPath) 6 throws Exception { 7 8 Configuration conf = new Configuration(); 9 10 for(FileStatus f: fs.listStatus(uniqueUsersPath)) { 11 if(f.getPath().getName().startsWith("part")) { 12 DistributedCache.addCacheFile(f.getPath().toUri(), conf); 13 } 14 } 15 16 Job job = new Job(conf); 17 job.setJarByClass(ReplicatedFilterJob.class); 18 job.setMapperClass(ReplicatedFilterJob.class); 19 job.setNumReduceTasks(0); 20 job.setInputFormatClass(KeyValueTextInputFormat.class); 21 outputPath.getFileSystem(conf).delete(outputPath, true); 22 FileInputFormat.setInputPaths(job, usersPath); 23 FileOutputFormat.setOutputPath(job, outputPath); 24 25 if(!job.waitForCompletion(true)) { 26 throw new Exception("Job failed"); 27 } 28 29 } 30 31 @Override 32 public Pair join(Pair inputSplitPair, Pair distCachePair) { 33 return inputSplitPair; 34 } 35 36 }
作业2的输出就是已被用户日志数据集的用户过滤过的用户集了。
作业3:
在最后一步中,需要将作业2生成的已过滤的用户集和原始的用户日志和并了。表面上,已过滤的用户集是足够小到可以放到内存中,同样也可以放到分布式缓存中。图4.10说明了这个作业的流程。
1 FileStatus usersStatus = fs.getFileStatus(usersPath); 2 3 for(FileStatus f: fs.listStatus(usersPath)) { 4 5 if(f.getPath().getName().startsWith("part")) { 6 DistributedCache.addCacheFile(f.getPath().toUri(), conf); 7 } 8 9 ...
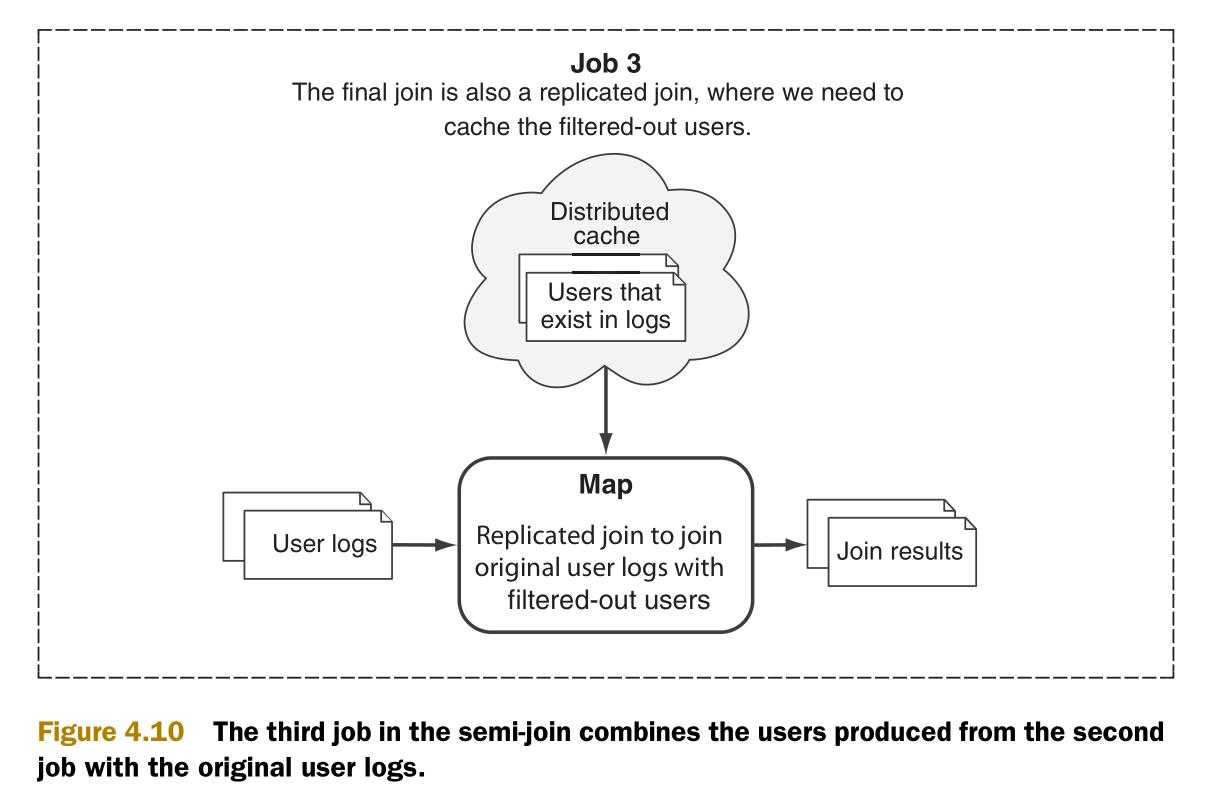
这里要再次用到复制连接框架来执行连接。但这次不用调节join方法的行为,因为两个数据集中的数据都要出现在最后的输出中。
执行这个代码,观察前述步骤生成的输出。
$ bin/run.sh com.manning.hip.ch4.joins.semijoin.Main users.txt user-logs.txt output $ hadoop fs -ls output /user/aholmes/output/filtered /user/aholmes/output/result /user/aholmes/output/unique $ hadoop fs -cat output/unique/part* bob jim marie mike $ hadoop fs -cat output/filtered/part* mike 69 VA marie 27 OR jim 21 OR bob 71 CA $ hadoop fs -cat output/result/part* jim logout 93.24.237.12 21 OR mike new_tweet 87.124.79.252 69 VA bob new_tweet 58.133.120.100 71 CA mike logout 55.237.104.36 69 VA jim new_tweet 93.24.237.12 21 OR marie view_user 122.158.130.90 27 OR jim login 198.184.237.49 21 OR marie login 58.133.120.100 27 OR
这些输出说明了在半连接的作业的逻辑进程和最终连接的输出。
小结:
在这个技术中说明了如何使用半连接来合并两个数据集。半连接的构建包括了比其他连接类型更多的步骤。但他确实是一个处理大的数据集的map端连接的强大的工具。当然,这些大的数据集要能够被减小到能够放到内存中。
复制连接是map端连接,得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点。复制连接的实现非常直接明了。更具体的内容可以参考Chunk Lam的《Hadoop in Action》。
这个部分的目标是:创建一个可以支持任意类型的数据集的通用的复制连接框架。这个框架中同样提供了一个优化的小功能:动态监测分布式缓存内容和输入块的大小,并判断哪个更大。如果输入块较小,那么你就需要将map的输入块放到内存缓冲中,然后在mapper的cleanup方法中执行连接操作了。
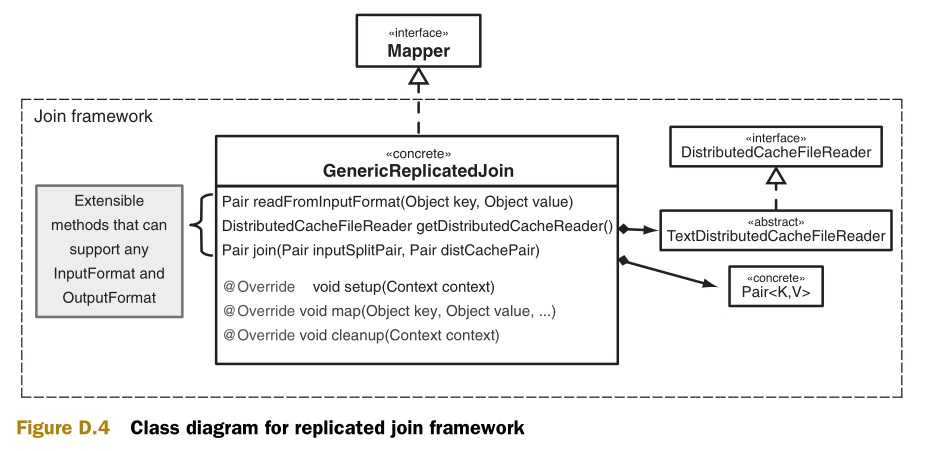
图D.4是这个框架的类图,这里我提供了连接类( GenericReplicatedJoin)的具体实现,而不仅仅是一个抽象类。在这个框架外,这个类将和KeyValueTextInputFormat及 TextOutputFormat协作。这里有一个假设前提:每个数据文件的第一个标记是连接键。此外,连接类也可以被继承扩展来和任意类型的输入和输出。
图D.5是连接框架的算法。Mapper的setup方法判断在map的输入块和分布式缓存的内容中哪个大。如果分布式缓存的内容比较小,那么它将被装载到内存缓存中。Map函数开始连接操作。如果输入块比较小,map函数将输入块的键\值对装载到内存缓存中。Map的cleanup方法将从分布式缓存中读取记录,逐条记录和在内存缓存中的键\值对进行连接操作。

以下代码的GenericReplicatedJoin中的setup方法是在map的初始化阶段调用的。这个方法判断分布式缓存中的文件和输入块哪个大。如果文件比较小,则将文件装载到HashMap中。
1 @Override 2 protected void setup(Context context) 3 throws IOException, InterruptedException { 4 5 distributedCacheFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration()); 6 int distCacheSizes = 0; 7 8 for (Path distFile : distributedCacheFiles) { 9 File distributedCacheFile = new File(distFile.toString()); 10 distCacheSizes += distributedCacheFile.length(); 11 } 12 13 if(context.getInputSplit() instanceof FileSplit) { 14 FileSplit split = (FileSplit) context.getInputSplit(); 15 long inputSplitSize = split.getLength(); 16 distributedCacheIsSmaller = (distCacheSizes < inputSplitSize); 17 } else { 18 distributedCacheIsSmaller = true; 19 } 20 21 if (distributedCacheIsSmaller) { 22 for (Path distFile : distributedCacheFiles) { 23 File distributedCacheFile = new File(distFile.toString()); 24 DistributedCacheFileReader reader = getDistributedCacheReader(); 25 reader.init(distributedCacheFile); 26 27 for (Pair p : (Iterable<Pair>) reader) { 28 addToCache(p); 29 } 30 31 reader.close(); 32 } 33 } 34 }
Map方法将会根据setup方法是否将了分布式缓存的内容装载到内存的缓存中来选择行为。如果分布式缓存的内容被装载到内存中,那么map方法就将输入块的记录和内存中的缓存做连接操作。如果分布式缓存的内容没有被装载到内存中,那么map方法就将输入块的记录装载到内存中,然后在cleanup方法中使用。
1 @Override 2 protected void map(Object key, Object value, Context context) 3 throws IOException, InterruptedException { 4 Pair pair = readFromInputFormat(key, value); 5 6 if (distributedCacheIsSmaller) { 7 joinAndCollect(pair, context); 8 } else { 9 addToCache(pair); 10 } 11 } 12 13 public void joinAndCollect(Pair p, Context context) 14 throws IOException, InterruptedException { 15 List<Pair> cached = cachedRecords.get(p.getKey()); 16 17 if (cached != null) { 18 for (Pair cp : cached) { 19 Pair result; 20 21 if (distributedCacheIsSmaller) { 22 result = join(p, cp); 23 } else { 24 result = join(cp, p); 25 } 26 27 if (result != null) { 28 context.write(result.getKey(), result.getData()); 29 } 30 } 31 } 32 } 33 34 public Pair join(Pair inputSplitPair, Pair distCachePair) { 35 StringBuilder sb = new StringBuilder(); 36 37 if (inputSplitPair.getData() != null) { 38 sb.append(inputSplitPair.getData()); 39 } 40 41 sb.append("\t"); 42 43 if (distCachePair.getData() != null) { 44 sb.append(distCachePair.getData()); 45 } 46 47 return new Pair<Text, Text>( 48 new Text(inputSplitPair.getKey().toString()), 49 new Text(sb.toString())); 50 }
当所有的记录都被传输给map方法,MapReduce将会调用cleanup方法。如果分布式缓存的内容比输入块大,连接将会在cleanup中进行。连接的对象是map函数的缓存中的输入块的记录和分布式缓存中的记录。
1 @Override 2 protected void cleanup(Context context) 3 throws IOException, InterruptedException { 4 5 if (!distributedCacheIsSmaller) { 6 7 for (Path distFile : distributedCacheFiles) { 8 File distributedCacheFile = new File(distFile.toString()); 9 DistributedCacheFileReader reader = getDistributedCacheReader(); 10 reader.init(distributedCacheFile); 11 12 for (Pair p : (Iterable<Pair>) reader) { 13 joinAndCollect(p, context); 14 } 15 16 reader.close(); 17 } 18 } 19 }
最后,任务的驱动代码必须指定需要装载到分布式缓存中的文件。以下的代码可以处理一个文件,也可以处理MapReduce输入结果的一个目录。
1 Configuration conf = new Configuration(); 2 3 FileSystem fs = smallFilePath.getFileSystem(conf); 4 FileStatus smallFilePathStatus = fs.getFileStatus(smallFilePath); 5 6 if(smallFilePathStatus.isDir()) { 7 for(FileStatus f: fs.listStatus(smallFilePath)) { 8 if(f.getPath().getName().startsWith("part")) { 9 DistributedCache.addCacheFile(f.getPath().toUri(), conf); 10 } 11 } 12 } else { 13 DistributedCache.addCacheFile(smallFilePath.toUri(), conf); 14 }
这个框架假设分布式缓存的内容和输入块的内容都可以被装载到内存中。这个框架的优点在于它只会将两者之中较小的装载到内存中。
在论文《A Comparison of Join Algorithms for Log Processing in MapReduce》中,你可以看到这个方法对于分布式缓存内容较大时的更进一步的优化。在他们的优化中,他们将分布式缓存分成N个分区,并将输入块放入N个哈希表。这样在cleanup方法中的优化就更加高效。
在map端的复制连接的问题在于,map任务必须在启动时读取分布式缓存。上述论文提到的另一个优化方案是重载FileInputFormat的splitting。将存在于同一个主机上的输入块合并成一个块。然后就可以减少需要装载分布式缓存的map任务的个数了。
最后一个说明,Hadoop在org.apache.hadoop.mapred.join包中自带了map端的连接。但是它需要有序的待连接的数据集的输入文件,并要求将其分发到相同的分区中。这样就造成了繁重的预处理工作。
[大牛翻译系列]Hadoop Mapreduce 连接(Join)之三:半连接(Semi-join),布布扣,bubuko.com
[大牛翻译系列]Hadoop Mapreduce 连接(Join)之三:半连接(Semi-join)
原文:http://www.cnblogs.com/datacloud/p/3579975.html