|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91 |
#include <iostream>#include <fstream>#include <string>#include<stdlib.h>using
namespace std;FILE
*fp; //读文件char
filename[20]; //文件路径及文件名int m=0;char
c[20];struct
wordcount //存放单词及其个数 { int
key; char
a[20]; };struct
wordcount list[300];void
readfile(char
filename[]) //读文件{ char
ch; int
flag=0; int
k,n=0,j=0; for(m=0;m<200;m++) //将list全部初始化为0 list[m].key=0; if((fp=fopen(filename,"rt"))==NULL) printf("cannot open the file!"); else while(!feof(fp)) { for(k=0;k<20;k++) c[k]=‘\0‘; int
i=0; ch=fgetc(fp); while(((ch>‘A‘&&ch<‘Z‘)||(ch>‘a‘&&ch<‘z‘))&&!feof(fp)) { if(ch>‘A‘&&ch<‘Z‘) ch=ch+32; c[i]=ch; ch=fgetc(fp); i++; } c[i]=‘\0‘; for(j=0;list[j].key!=0;j++) { if(strcmp(list[j].a,c)==0) { list[j].key=list[j].key+1; flag=1; break; } } if(flag==0) { list[j].key=1; strcpy(list[j].a,c); } flag=0; } }void
sort() //排序{ int
i,j,max; int
n=100; char
ch2[20]; for(i=0;i<10;i++) { max=list[i].key; for(j=i+1;j<n;j++) if(list[j].key>max) { max=list[j].key; list[j].key=list[i].key; list[i].key=max; strcpy(ch2,list[j].a); strcpy(list[j].a,list[i].a); strcpy(list[i].a,ch2); } cout<<list[i].a<<‘\t‘<<list[i].key<<‘\t‘<<endl; }}void
main(){ int
i; cout<<"请输入文件路径及文件名 :"; scanf("%s",filename); readfile(filename); cout<<"频率最高的前十个词是:"<<endl; sort(); } |
本程序总共分为三部分读文件readfile()、单词统计、排序找出频率最高的前十个单词;
一、在统计单词频率的程序中,首先第一步是读文件,
if((fp=fopen(filename,"rt"))==NULL)
printf("cannot open the
file!");
else
while(!feof(fp)){}
这几行代码是读文件,其中要注意的是定义fp,FILE *fp,不要忘记*;
二、单词统计部分是重要部分之一,本程序利用结构体、链表来记录单词及单词的个数
while(((ch>‘A‘&&ch<‘Z‘)||(ch>‘a‘&&ch<‘z‘))&&!feof(fp))
{
if(ch>‘A‘&&ch<‘Z‘)
ch=ch+32;
c[i]=ch;
ch=fgetc(fp);
i++;
}
c[i]=‘\0‘;利用ch=ch+32将大写转换成小写,实现单词的识别,
for(j=0;list[j].key!=0;j++)
{
if(strcmp(list[j].a,c)==0)
{
list[j].key=list[j].key+1;
flag=1;
break;
}
}
当遇到空格一个单词结束,进行单词之间的比较,个数累加
for(i=0;i<10;i++)
{
max=list[i].key;
for(j=i+1;j<n;j++)
if(list[j].key>max)
{
max=list[j].key;
list[j].key=list[i].key;
list[i].key=max;
strcpy(ch2,list[j].a);
strcpy(list[j].a,list[i].a);
strcpy(list[i].a,ch2);
}
cout<<list[i].a<<‘\t‘<<list[i].key<<‘\t‘<<endl;
}
将第一个看做单词数最多的,和其他单词比较,最后把数量最多的单词换在第一位输出,依次类推输出出现频率最多的前十个单词;
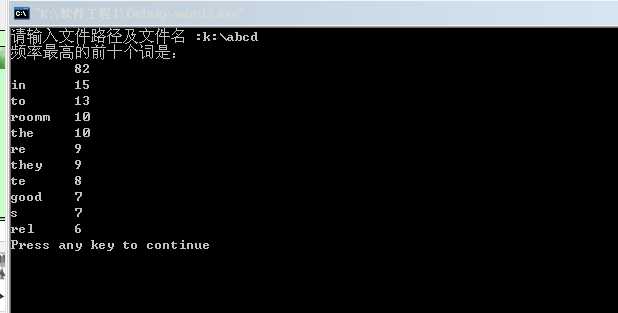
原文:http://www.cnblogs.com/guolili/p/3577336.html