不写,默认是下面的转换类
job.setInputFormatClass(TextInputFormat.class)
List<InputSplit> InputFormat.getSplits首先对输入的数据做切分,切分后的split书面决定map的任务数;
RecordReader<K,V> InputFormat.createRecordReader(InputSplit split, ...)传入切分的数据,处理成key、value,然后把keyvalue值送给map执行,每一对key、value对都会调用一次map;
FileInputFormat<K, V> extends InputFormat<K, V>
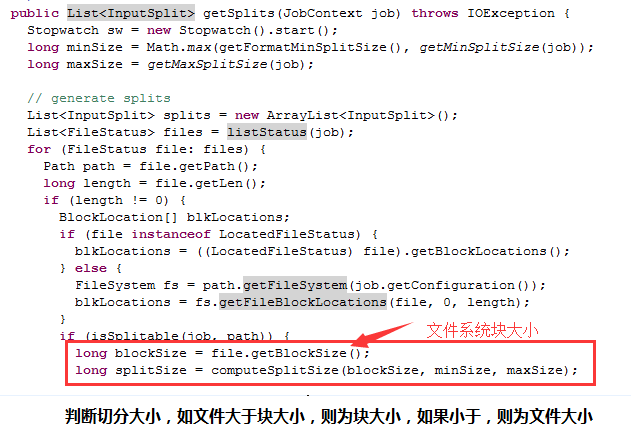
List<InputSplit> FileInputFormat.getSplits
TextInputFormat extends FileInputFormat<LongWritable, Text>

原文:http://my.oschina.net/sniperLi/blog/359081