数据来源: 应用宝
开发环境:win10、python3.7
开发工具:pycharm、Chrome
明确需要采集的数据:
提取到页面的分类标签
获取到a标签的href属性
用于之后拼接动态地址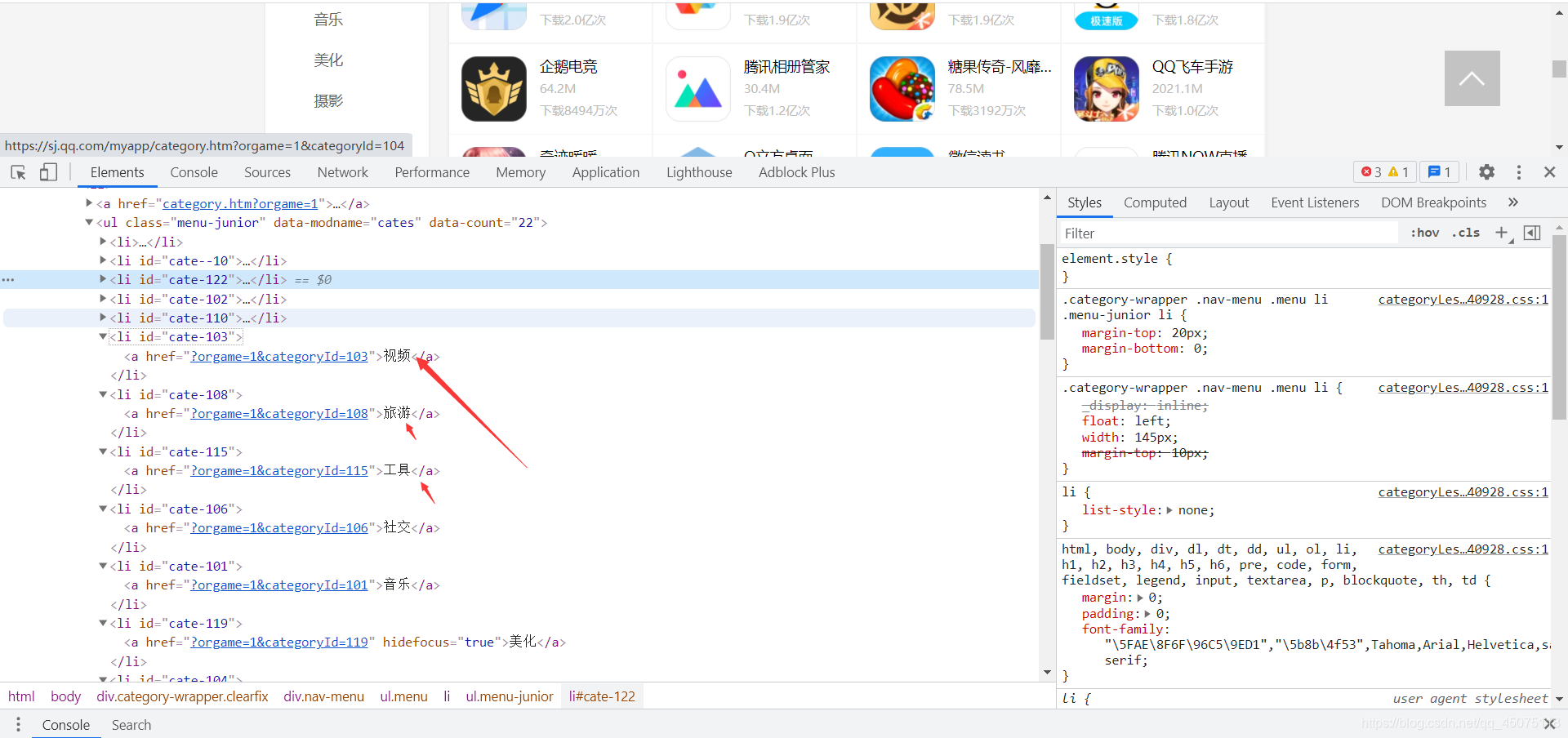
找到动态加载的app数据加载地址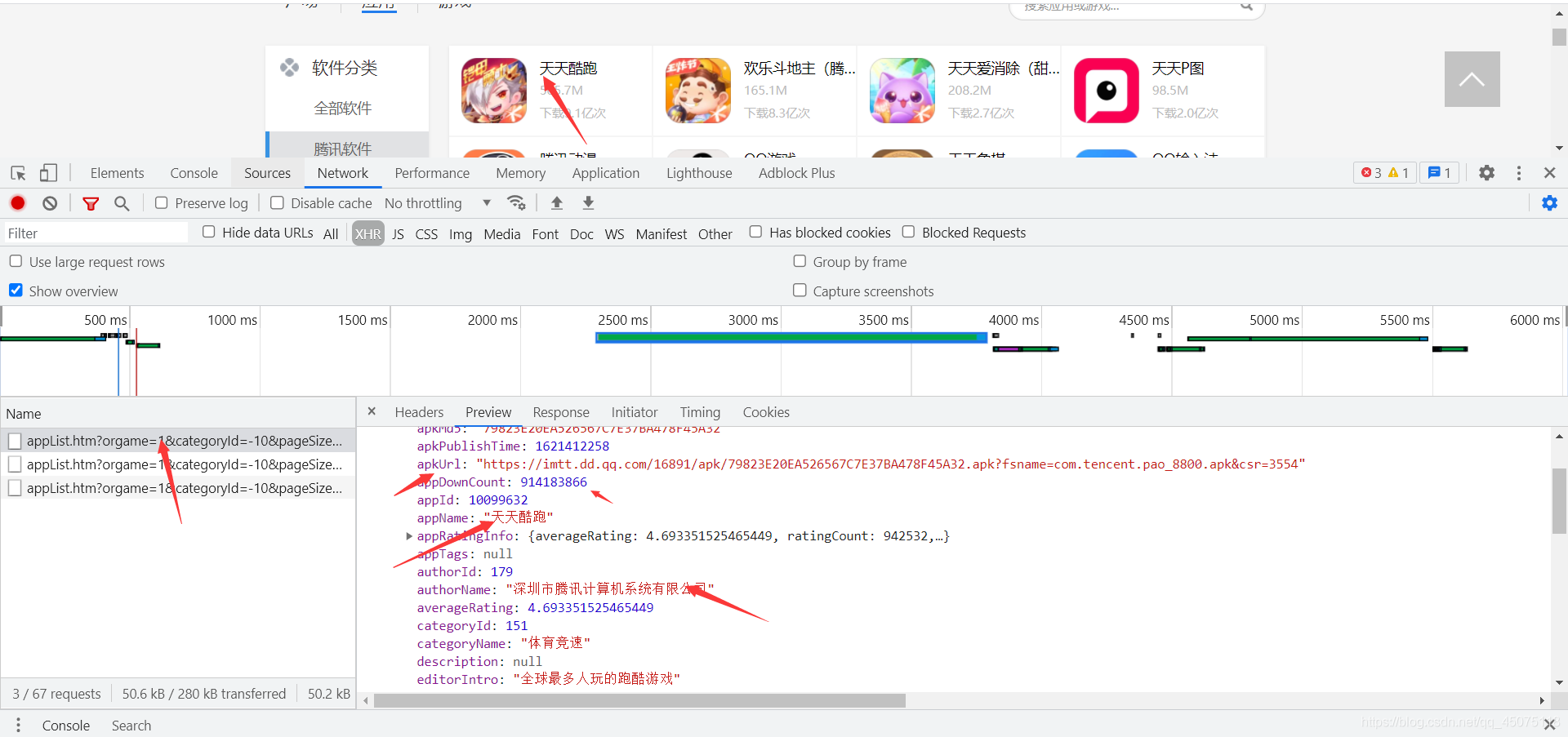
url的值是每个分类标签的值
https://sj.qq.com/myapp/cate/appList.htm?orgame=1&categoryId=-10&pageSize=20&pageContext=undefined
拼接新的url值发送请求
import requests # 工具包发送网络请求
from lxml import etree # 转换成对象
import csv # 处理表格数据
url = "https://sj.qq.com/myapp/category.htm?orgame=1"
response = requests.get(url)
html_data = etree.HTML(response.text)
li_list = html_data.xpath(‘//ul[@data-modname="cates"][position()>1]/a/@href‘)
del(li_list[-1])
for url1 in li_list:
for i in range(10):
new_url = "https://sj.qq.com/myapp/cate/appList.htm" + url1 + "&pageSize=20&pageContext={}".format(i*20)
res = requests.get(new_url).json()
if res["count"] == 0:
break
with open("应用宝.csv", "a", newline="", encoding="utf-8")as f:
csv_data = csv.DictWriter(f, fieldnames=["appName", ‘authorName‘, "apkUrl"])
for info in res["obj"]:
appName = info[‘appName‘]
authorName = info[‘authorName‘]
apkUrl = info[‘apkUrl‘]
print({"appName": appName, "authorName": authorName, "apkUrl": apkUrl})
csv_data.writerow({"appName": appName, "authorName": authorName, "apkUrl": apkUrl})
原文:https://www.cnblogs.com/ai19970205/p/15311809.html