聚类分析是根据对象的特性对其进行定量分类的一种多元统计方法。 比如:不同地区城镇居民收入和消费状况的分类研究;区域经济及社会发展水平的分析及全国区域经济综合评价.......
通常聚类分析分为Q型聚类分析和R型聚类分析。
Q型聚类分析:对样品的分类;
R型聚类分析:对变量的分类。
通常聚类之前,要首先分析样品(或变量)间的相似性。
样品相似性度量(距离):明氏距离(欧式距离、绝对值距离、切比雪夫距离)、马氏距离。
变量相似性度量(相似系数):夹角余弦、相关系数
距离越小(相似系数越大),样品(变量)相似性越大
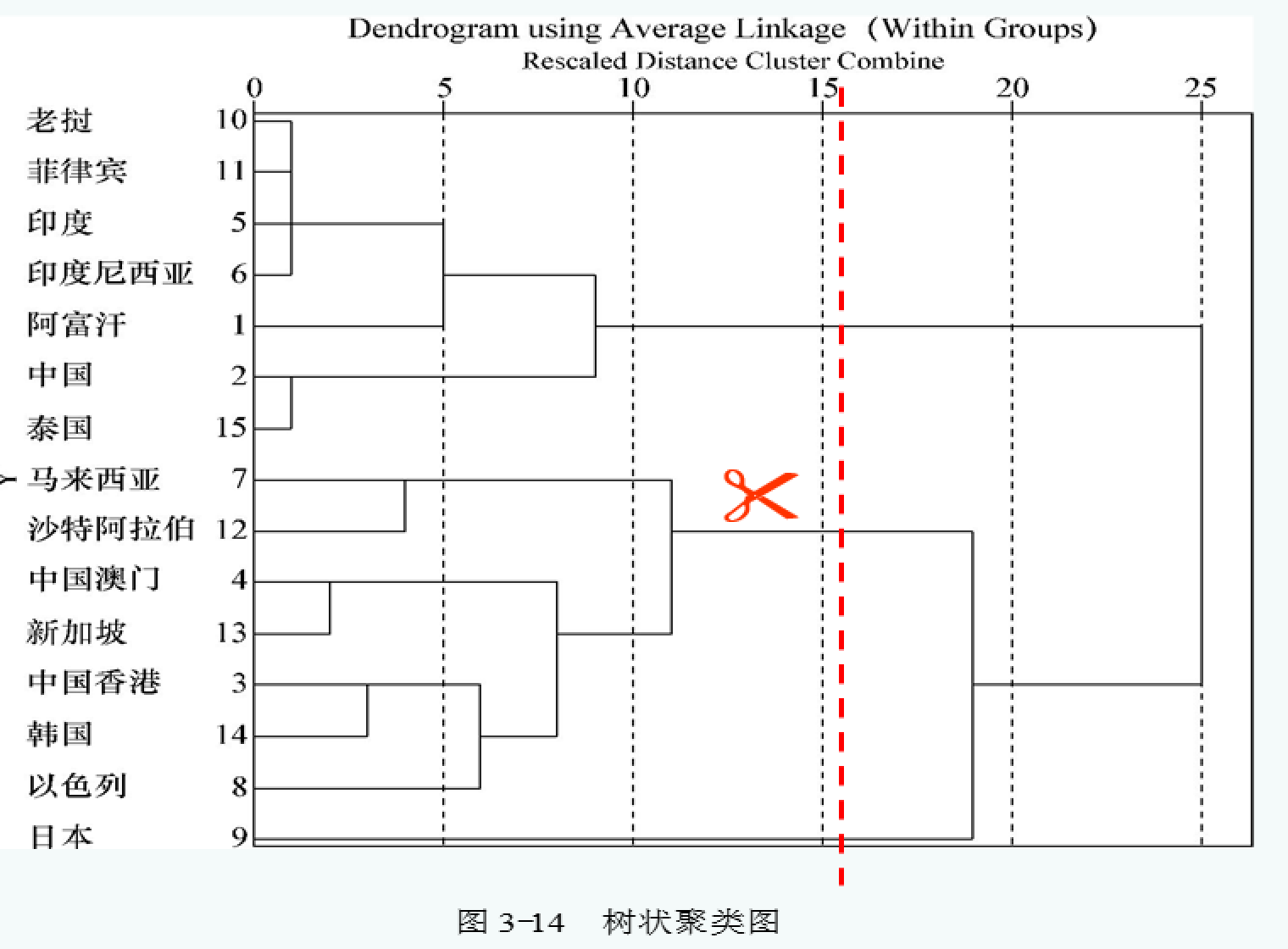
系统聚类法的过程是:假设总共有n个样品(或变量),第一步将每个样品(或变量)独自聚成一类,共有n类;第二步根据所确定的样品(或变量)“距离”公式,把距离较近的两个样品(或变量)聚合为一类,其它的样品(或变量)仍各自聚为一类,共聚成n ?1类;第三步将“距离”最近的两个类进一步聚成一类,共聚成n ?2类;……,以上步骤一直进行下去;最后将所有的样品(或变量)全聚成一类。为了直观反映系统聚类过程,可以将整个聚类过程绘制一张图,图称为谱系图或树状结构图。 常用的系统聚类法:最短距离法、最长距离法、组间类平均法、组内类平均法、重心法、中间法、Ward法
系统聚类法是一种比较成功的聚类方法。然而当样本点数量十分庞大时,则是一件非常繁重的工作,且聚类的计算速度也比较慢。此时K-均值聚类就会显得方便,适用。 K均值法是麦奎因(MacQueen,1967)提出的,这种算法的基本思想是将每一个样品分配给最近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.确定类别数目k 2.将所有的样品分成K个初始类; 3.通过欧氏距离将某个样品划入离中心最近的类中,并对获得样品 与失去样品的类,重新计算中心坐标; 4.重复步骤2,直到所有的样品都不能再分配时为止。
例:
系统聚类:
快速聚类
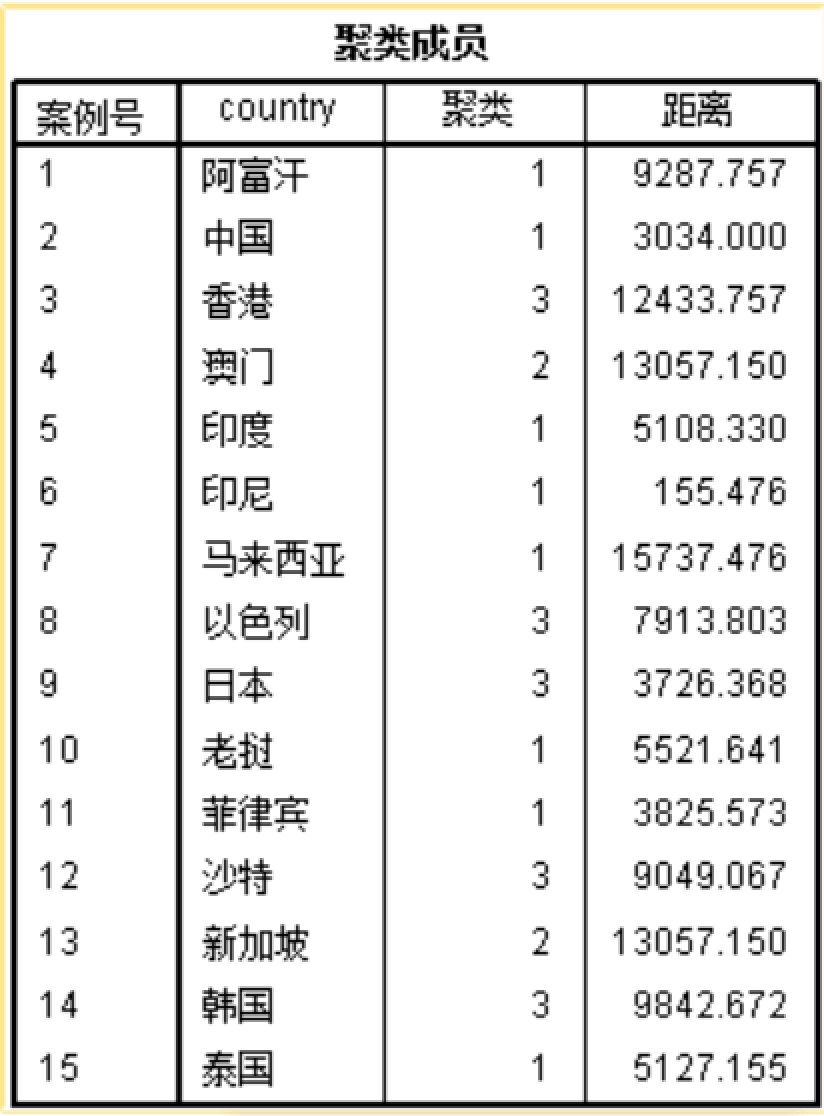
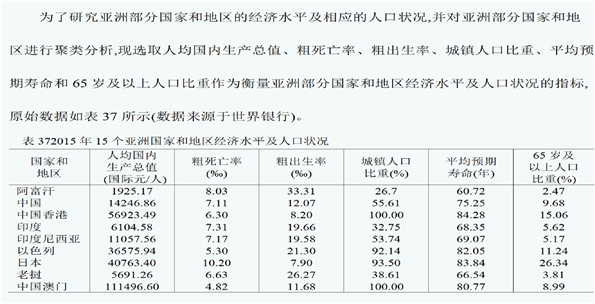
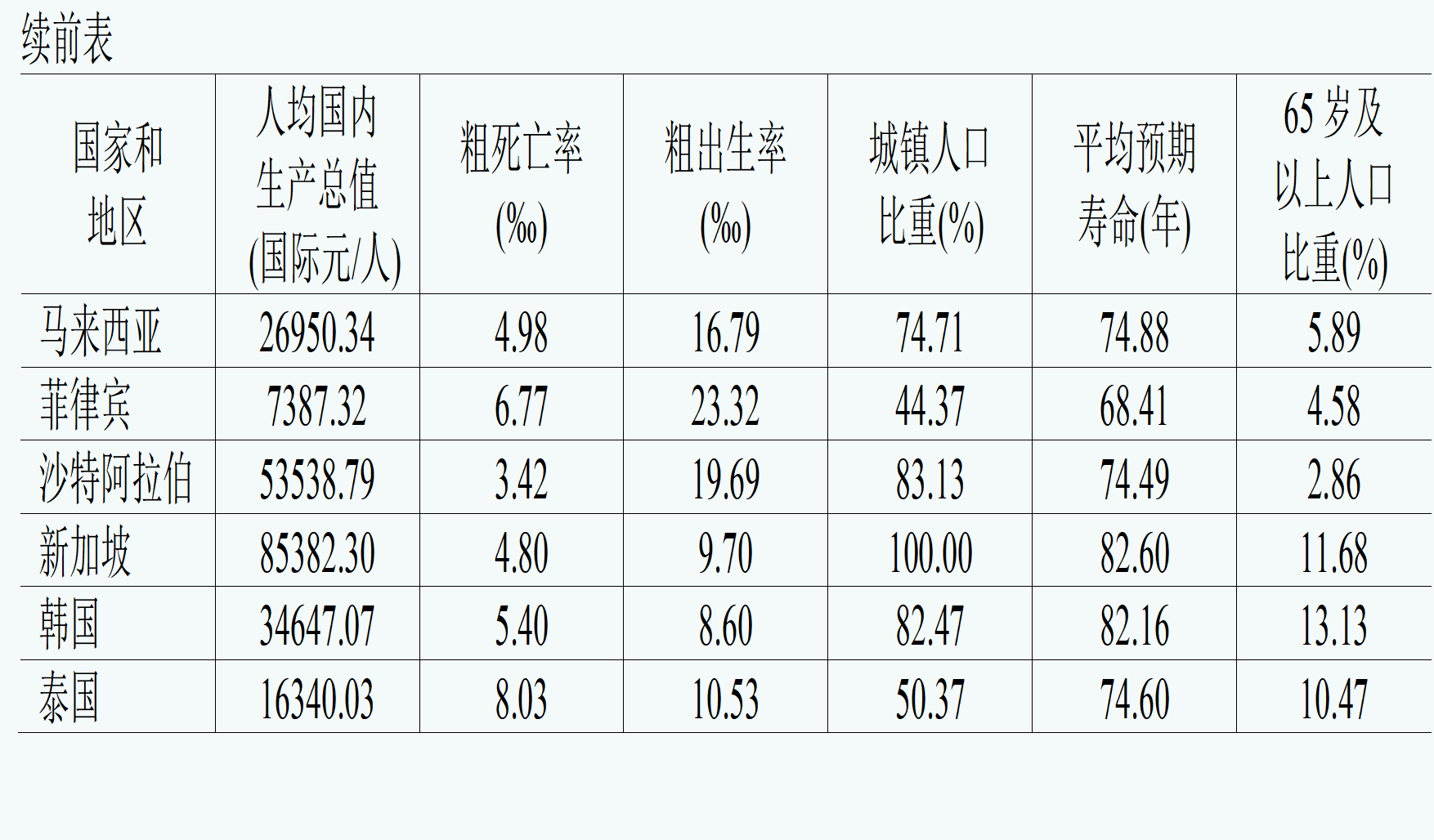
分类情况如下: 第一类:阿富汗、中国、印度、印度尼西亚、马来西亚、老挝、菲律宾、泰国 第二类:澳门、新加坡 第三类:香港、以色列、日本、沙特、韩国
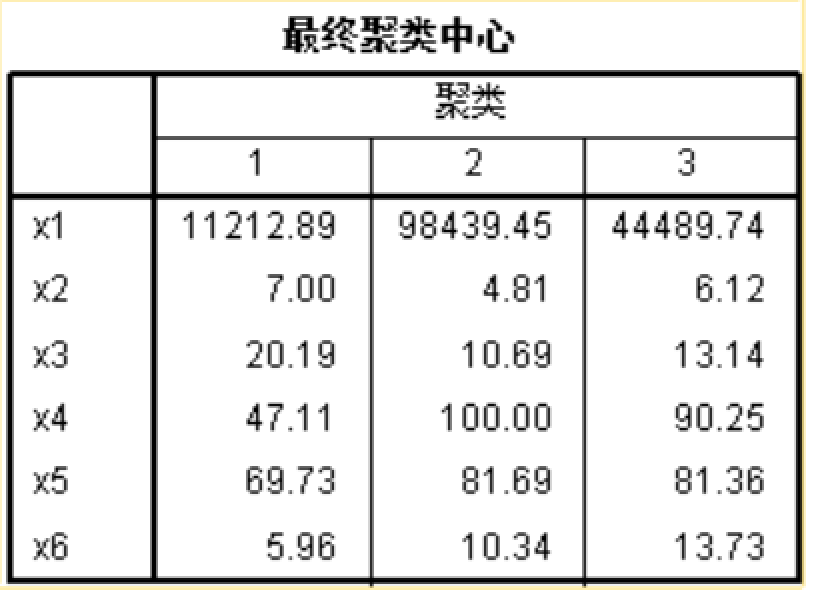
由上表可知:第一类国家和地区的经济水平相对较低,人口老龄化程度也相对较轻。第二类国家和地区的经济水平较高,同时人口老龄化程度严重。第三类国家和地区的经济水平居中,人口老龄化程度较重。
原文:https://www.cnblogs.com/huakaihualuoyi/p/15169640.html