新建最后一个 MyBatis 项目 MyBatis-09 来学习一下 MyBatis 的缓存。创建完后添加 Maven 依赖,导入核心配置文件和工具类。
什么是缓存?
缓存:存在内存中的临时数据。
执行查询操作,需要连接数据库,要消耗系统的资源;当查询操作需求十分大的时候,系统的压力也会非常大。所以可以将查询到的结果保存在缓存中,再次查询的时候,直接访问缓存,就不需要再到数据库中进行查询了。
为什么使用缓存?
什么样的数据要用到缓存?
再留下两个概念:读写分离,主从复制。
MyBatis 包含非常强大的缓存特性,可以非常方便的定制和配置缓存,从而极大地提升查询效率。
MyBatis 中默认定义了两级缓存:一级缓存和二级缓存
Cache 默认的实现有很多,如
public class FifoCache implements Cache
public class LruCache implements Cache
public class SoftCache implements Cache
public class WeakCache implements Cache
...
引用官方文档中对 cache 的介绍
这些属性可以通过 cache 元素的属性来修改。比如:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。默认的清除策略是 LRU。
这里用 user 表来进行测试,对应的 User、UserMapper、UserMapper.xml,其中方法都是测试中用到的
@Data
@AllArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
}
public interface UserMapper {
// 根据 id 查询用户,最好把注解加上(规范)
User queryUserById(@Param("id") int id);
// 修改用户,更新了数据库
int updateUser(User user);
}
<mapper namespace="com.qiyuan.dao.UserMapper">
<select id="queryUserById" resultType="User">
select * from user where id = #{id}
</select>
<update id="updateUser" parameterType="User">
update user set name = #{name}, pwd = #{pwd} where id = #{id}
</update>
</mapper>
记得在核心配置文件中把日志打开和注册对应的接口。
执行测试方法,查询两次 id 为1的用户,看看日志的输出
@Test
public void queryUserById(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 查询 id 为 1 的用户
User user = mapper.queryUserById(1);
System.out.println(user);
System.out.println("---------------");
// 再查询一次 1 号用户
User user1 = mapper.queryUserById(1);
System.out.println(user1);
System.out.println(user==user1);
sqlSession.close();
}
Opening JDBC Connection
// ...
Created connection 1342346098.
==> Preparing: select * from user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, name, pwd
<== Row: 1, 祈鸢, 123456
<== Total: 1
User(id=1, name=祈鸢, pwd=123456)
---------------
User(id=1, name=祈鸢, pwd=123456)
true
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@50029372]
Returned connection 1342346098 to pool.
可以看到,在执行第一次查询的时候打开了 JDBC 连接,从连接池中获取了一个连接,用 SQL 语句进行了查询;但第二查询的时候,直接就获得了要查询的用户;判断 user 和 user1 地址是否相等也是 true,即在内存中是同一个对象。这就是默认开启的一级缓存。
那这个一级缓存什么时候失效呢?
把测试方法修改一下,在第二次查询前增加个修改操作,再执行一下看看日志
// 查询 id 为 1 的用户
// ...
// 修改一下 2 号用户信息
mapper.updateUser(new User(2,"qiyuanc2","0723"));
System.out.println("---------------");
// 再查询一次 1 号用户
// ...
Opening JDBC Connection
// ...
Created connection 1342346098.
==> Preparing: select * from user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, name, pwd
<== Row: 1, 祈鸢, 123456
<== Total: 1
User(id=1, name=祈鸢, pwd=123456)
---------------
==> Preparing: update user set name = ?, pwd = ? where id = ?
==> Parameters: qiyuanc2(String), 0723(String), 2(Integer)
<== Updates: 1
---------------
==> Preparing: select * from user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, name, pwd
<== Row: 1, 祈鸢, 123456
<== Total: 1
User(id=1, name=祈鸢, pwd=123456)
false
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@50029372]
Returned connection 1342346098 to pool.
可以看到,虽然修改的是2号用户的信息,但查询1号用户时,也不会再从缓存中获取了。因为数据库进行增删改操作后,为了保持数据的一致性,需要刷新缓存,这就使得一开始的缓存失效了。
一级缓存失效的情况
数据库进行了增删改操作,需要刷新
缓存被手动清理了(这里就不测试了)
sqlSession.clearCache();
查询不同的东西(缓存里没有嘛)
查询不同的 Mapper.xml(都超出作用域了)
一级缓存作用域小,局限性太大,真要用还得看二级缓存!
二级缓存也叫全局缓存,一级缓存的作用域太低了,所以产生了二级缓存。二级缓存是 namespace 级别的缓存,即同一个命名空间下的 mapper 都享有相同的二级缓存(一个命名空间,对应一个二级缓存)。
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>基本上就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
如官方文档所说,通过一个标签就可以开启二级缓存,其中的配置属性是默认的。
不过在使用这个标签前,最好在核心配置文件中开启缓存
<settings>
...
<!--显式地开启缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
其中 cacheEnabled 为 “全局性地开启或关闭所有映射器配置文件中已配置的任何缓存”,有效值为 true 和false,默认值为 true,但最好还是配置一下以显式地开启缓存。
这些属性可以通过 cache 元素的属性来修改。比如:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。默认的清除策略是 LRU。
提示 二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache = true 的 insert/delete/update 语句时,缓存会获得更新。
在要开启二级缓存的 mapper 中添加 cache 标签,这里使用有参数的标签,更好理解;在查询标签中也可以单独设置是否开启缓存,useCache 默认为 true,即缓存是打开的
<!-- UserMapper.xml 中-->
<mapper namespace="com.qiyuan.dao.UserMapper">
<cache eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
<select id="queryUserById" resultType="User" useCache="true">
select * from user where id = #{id}
</select>
...
</mapper>
开启完后在测试方法中测试一下
@Test
public void queryUserById2(){
// 创建两个 sqlSession 对应两个会话
SqlSession sqlSession1 = MyBatisUtils.getSqlSession();
SqlSession sqlSession2 = MyBatisUtils.getSqlSession();
// 用不同的 sqlSession 实例化接口
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
// sqlSession1 查询 id 为 1 的用户
User user1 = mapper1.queryUserById(1);
System.out.println(user1);
// 二级缓存是事务性的!若此处不关闭 1 则其中的一级缓存不会更新到二级缓存中
sqlSession1.close();
System.out.println("---------------");
// sqlSession2 查询 id 为 1 的用户
User user2 = mapper2.queryUserById(1);
System.out.println(user2);
sqlSession2.close();
// 再比较一下
System.out.println(user1==user2);
}
日志和结果的输出
Opening JDBC Connection
// ...
Created connection 1948810915.
==> Preparing: select * from user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, name, pwd
<== Row: 1, 祈鸢, 123456
<== Total: 1
User(id=1, name=祈鸢, pwd=123456)
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@74287ea3]
Returned connection 1948810915 to pool.
---------------
Cache Hit Ratio [com.qiyuan.dao.UserMapper]: 0.5
User(id=1, name=祈鸢, pwd=123456)
true
可以看到,SQL 语句只执行了一次。至于为什么 sqlSession2 没有关闭,都能从缓存里获得数据了,相当于这个连接没开启(这也是为什么效率高),没开启当然不用关闭了。
Cache Hit Ratio 是缓存命中率,可以用于选择哪种缓存策略(看到命中率就害怕)。
之前没发现这个问题。如果开启缓存时只使用 cache 标签
<mapper namespace="com.qiyuan.dao.UserMapper">
<cache/>
...
</mapper>
则运行上面的测试方法会报错
org.apache.ibatis.cache.CacheException: Error serializing object.
Cause: java.io.NotSerializableException: com.qiyuan.entity.User
这是未序列化错误,那什么是序列化,为什么要序列化呢?
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。 意思就是
默认 readOnly = false,所以要求缓存对象必须支持序列化。
也就是说如果为开启缓存只读,则缓存对象必须支持序列化。
让缓存对象支持序列化:实现序列化接口 Serializable
@Data
@AllArgsConstructor
public class User implements Serializable {
private int id;
private String name;
private String pwd;
}
这样就正常了。
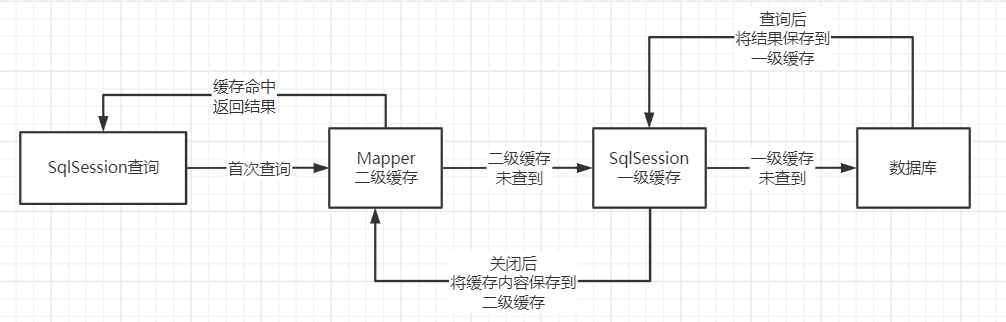
一级缓存:一级缓存是默认开启的,只在一次 SqlSession 中有效,即 SqlSession 开启到关闭的这个区间!因为每个用户查询的时候都对应一个 SqlSession(连接不能共享),所以一级缓存别的用户也是获取不到的,没什么用啊!
二级缓存:只要开启了二级缓存,在同一个 Mapper 下都有效;缓存数据会先放在一级缓存中,当会话关闭或提交,才会提交到二级缓存中!即二级缓存是事务性的!
还有一个自定义缓存使用 ehcache 的,了解了一下,反正后面也得用 redis。
这样 MyBatis 的学习就结束啦(其实还差点练习没写),不过,下一个,Spring??!
原文:https://www.cnblogs.com/qiyuanc/p/mybatis_cache.html