原文链接:https://zhuanlan.zhihu.com/p/353680367
此篇文章内容源自 Attention Is All You Need,若侵犯版权,请告知本人删帖。
原论文下载地址:
https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
主要的序列转导模型是基于复杂的递归或卷积神经网络的,这些网络包含一个编码器和一个解码器。上述模型中最佳的模型使用了注意力机制连接了编码器和解码器。作者提出一个新的简单的网络架构,即 Tranformer,仅基于注意力机制,完全摒弃了递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上具有优势,同时具有更高的可并行性,并且所需的训练时间明显更少。作者提出的模型在 WMT 2014 英语-德语 翻译任务上达到了 28.4 BLEU,比现有的最佳结果(包括集成)提高了2 BLEU 以上。在WMT 2014英语-法语翻译任务中,我们的模型在 8 个 gpu 上训练3.5天后,建立了一个新的单模型最佳的 41.0 BLEU 分数,这只相当于文献中最好模型所需训练成本的一小部分。
最具竞争力的神经序列转导模型具有编码器-解码器结构。编码器将符号表示的输入序列 映射为一个连续表示的序列
。给定
,解码器将生成一个符号表示的输出序列
,每次生成输出序列中的一个元素。在每一步模型都是自回归的,在生成下一个符号时将之前生成的所有符号作为附加输入。
Transformer 遵从以下所述的整体架构,该架构针对编码器和解码器使用了堆叠的自注意力机制、逐点计算和全连接层,编码器和解码器分别如图 1 的左右部分所示。
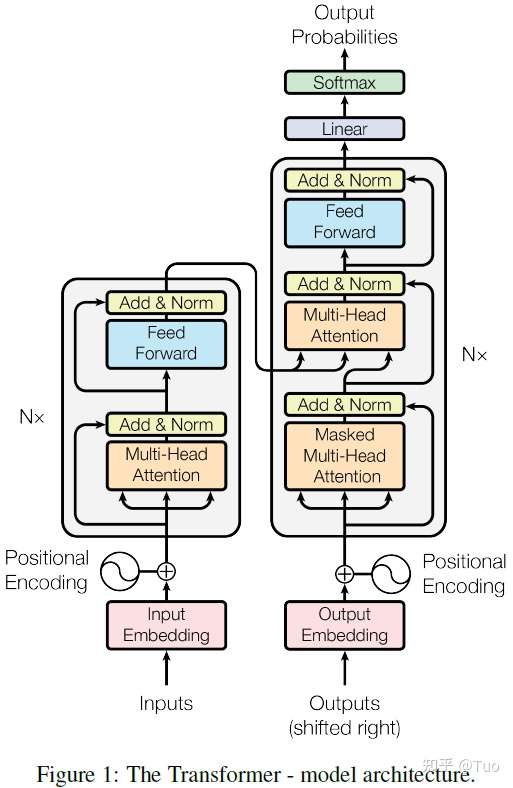 图 1 Transformer 模型架构
图 1 Transformer 模型架构
编码器由 N 个完全相同的层堆叠而成,此处 N=6。每一层都是一个双子层结构。第一个子层是一个多头部自注意力机制,第二个子层是一个简单的按位全连接的前馈网络。作者针对每个双子层结构中的各个子层使用了残差连接[1],并在残差连接后使用了层归一化[2]。层归一化是对每个子层的输出执行 ,其中
是子层自身实现的功能。为了易于残差连接,模型中的所有子层以及嵌入层均生成
维度的输出,此处
。
解码器也由 N 个完全相同的层堆叠而成,此处 N=6。基于编码器中的双子层结构,解码器插入了第三个子层,该子层针对编码器模块的输出执行多头部注意力。与编码器类似,作者也在解码器的每个子层结构的各个子层中使用了残差连接,并执行了层归一化。作者也更新了解码器模块中的自注意力子层,防止当前位置影响后续位置。这种掩码机制连同输出嵌入具有一个位置偏移的实际情况,保证了针对位置 的预测可以只依赖于位置小于
的已知输出。
注意力功能可以被描述为一个查询和键值对到一个输出的映射,其中查询、键、值和输出全部是向量。输出是值的加权和,其中分配给每个值的权重是根据查询和对应键的兼容性函数计算的。
作者称其提出的特殊注意力为“缩放点积注意力(Scaled Dot-Product Attention)”,如图 2 所示。输入由 维度的查询和键,以及
维度的值组成。计算每个查询和所有键的点积,每个查询对应的点积结果除以
,然后施加 softmax 函数来获取该值的权重。其他查询遵循此方法。
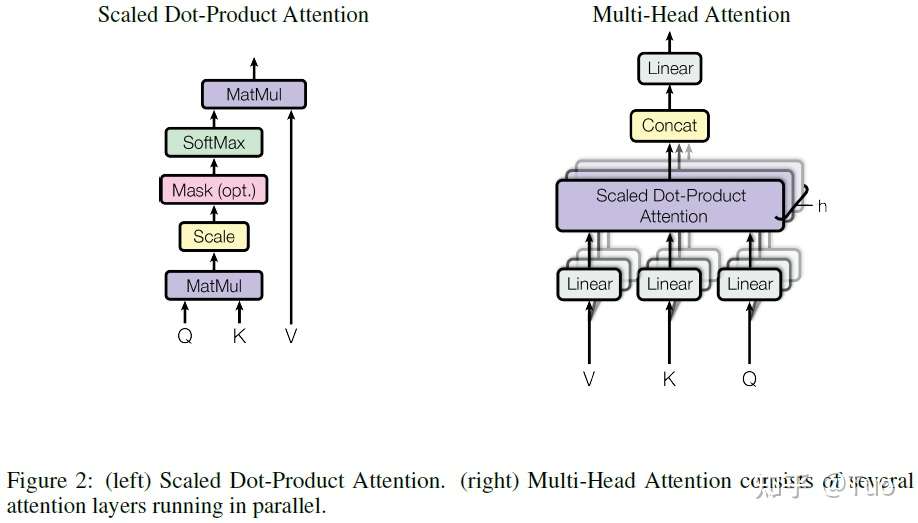 图 2 (左) 缩放点积注意力。(右) 多个并行的注意力层构成的多头部注意力。
图 2 (左) 缩放点积注意力。(右) 多个并行的注意力层构成的多头部注意力。
实际中,作者针对一个查询集合同时计算其注意力函数,查询集合拼接为矩阵 Q。键和值也拼接为矩阵 K 和 V。按照公式 (1) 计算输出矩阵。
(1)
假定有 b 个查询,那么 Q、K 的维度为,V 的维度为
。
的维度为
,softmaxt 函数的输出维度也是
两个最常用的注意力函数是加法注意力[3]和点积(乘法)注意力。除了缩放因子 ,点积注意力与作者的算法是一致的。加法注意力使用一个具有单个隐藏层的前馈网络计算兼容性函数。虽然两者在理论复杂性上相似,但是点积注意力在实际中会更快更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
尽管当 取值较小时,两种注意力机制表现相似,但是当
取值较大且不进行缩放时,加法注意力要优于点积注意力。作者猜测,当
较大值时,点积会大幅度增大,并且将 softmax 函数推入其梯度极小的区域(即其值趋于1或0)。为了缓解该影响,作者通过
缩放点积。
作者发现使用不同的可学习线性投影将查询、键、值线性投影 h 次,在每次投影时分别得到 维度的查询、键、值会有更好的效果,而不是使用
维度的键、值、查询单独执行一次注意力函数。针对投影后的每一组查询、键、值,作者并行地执行注意力函数,生成一个
维度的输出值。这些输出值被拼接在一起,然后再一次被投影,生成最终值,如图 2 所示。
多头部注意力可以使模型综合考虑来自不同位置的不同表示子空间的信息。使用单独的注意力头部,平均操作(层归一化时的操作)会抑制这一特性。
其中,投影对应的参数矩阵为 ,
,
和
。此处的 Concat 操作是各个矩阵按照列来拼接,这样可以在保证每个矩阵不变的前提下,得到一个列维度为
的矩阵。
假定有 b 个查询,那么 Q、K 、V的维度为,
和
的维度为
的维度为
的维度为
。MultiHead 的输出维度为
在本文中,作者使用了 的并行注意力层,或可以称为 8 头部注意力。其他参数为
。由于每个头部缩减了维度,整体的计算开销和维度不变时的单头部注意力类似。
本文中 Transformer 通过三种不同方式使用多头部注意力:
除了注意力子层,作者提出的编码器和解码器中的每个层都包含一个全连接前馈网络,该网络分别且独立地应用于每个位置。该网络包含两个线性变换,并且两个变换之间存在一个 ReLU 激活。如公式 (2)。
(2)
尽管不同位置上执行的线性变换操作是一致的,但是它们在各层之间使用不同的参数。另一种实现方法是使用两个卷积核尺寸为 1 的卷积。输入和输出的维度是 ,内部层的维度是
。
与其他序列转导模型相似,作者使用可学习嵌入来将输入符号和输出符号转换为维度为 的向量。作者也使用常用的可学习线性变换和 softmax 函数将编码器输出转换为下一个被预测符号的概率。在作者的模型中,作者在两个嵌入层和前一个 softmax 线性变换之间共享相同的权重矩阵,和文献[6]类似。在嵌入层,作者将这些权重乘以
。
由于作者提出的网络不包含递归和卷积,为了使模型能够利用序列的顺序信息,必须向序列中注入符号的相对位置或绝对位置信息。为此,作者在编码器和解码器底部向输入嵌入添加了“位置编码”。位置编码与嵌入具有相同的维度 ,确保了二者可以相加。现有多种可学习和固定位置编码可供选择[5]。
在本文中,作者选用了不同频率的 sine 和 cosine 函数:
其中 pos 表示位置,i 表示维度。也就是说,位置编码的每个维度对应一个正弦信号。波长构成了 至
的几何级数。作者选择该函数是因为猜测其会使模型易于学会如何参考相对位置,因为对于任何固定偏移 k,
可以认为是
的线性函数。
作者也试验了用可学习位置嵌入[5]替代正弦信号编码,发现二者产生的结果几乎相同(表 3 E 行)。作者选择正弦信号编码因为其可能会使模型推断出比训练过程中遇到的序列长度更长的序列。
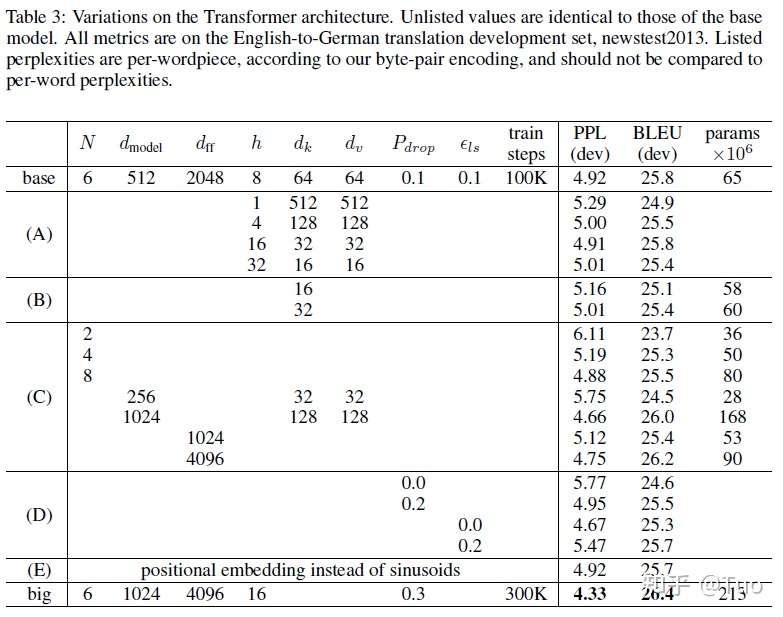 表 3
表 3
表 3 A 行验证了不同的注意力头部、注意力键维度、注意力值维度的数目,在保持总计算量不变(如“2.2 多头部注意力”所述)的前提下模型的性能。尽管单头部注意力比最佳设置低了 0.9 BLEU,但是过多的头部也会降低模型性能。
表 3 B 行说明了,降低注意力的键的大小 会损伤模型质量。这表明确定兼容性并不容易,并且比点乘积更复杂的兼容性功能可能会有所帮助。作者进一步在 C 行和 D 行发现,正如所期待的,模型越大性能越好,dropout 能有效地避免过拟合。在 E 行,作者将正弦位置编码替换为可学习位置嵌入[5],其结果与基线模型几乎相同。
这一部分作者从多个角度比较了自注意力层和常用于将变长的符号表示序列 映射为另一个等长序列
的递归层、卷积层,其中
,例如典型的序列转换编码器或解码器中的隐藏层。以下三个需求促使作者使用了自注意力。
第一个是每层的总计算复杂度。第二个是可以并行的计算量,与顺序操作所需的最小数目一致。
第三个是网络中远程依赖关系之间的路径长度。学习远程依赖是许多序列转导模型的一个主要挑战。影响学习这种依赖的一个重要因素是网络中前馈信号和后馈信号必须遍历的路径长度。输入序列和输出序列中任一位置组合之间的路径越短,越易于学习远程依赖[7]。因此,作者也比较了由不同类型的层构成的网络中,任意两个输入输出位置之间的最大路径长度。
如表 1 所示,一个自注意力层通过常量级的顺序执行操作连接了所有位置,而一个递归层需要 个顺序操作。就计算复杂度来说,当序列长度 n 比表示维度 d 小时,自注意力层比递归层快,而这种情况在机器翻译领域的 SOTA 模型中使用的句子表征中很常见,例如词片[4]和字节对[8]表示。为了提高涉及到特别长的序列的任务的计算性能,自注意力可以限制为只考虑以与输出位置相对应的输入位置为中心,输入序列中大小为 r 的邻域。这将增加最大路径长度至
。作者计划在未来的工作中进一步研究这种方法。
 表 1
表 1
一个单独的卷积核宽度 的卷积层无法连接所有输入输出位置对。为了连接所有输入输出位置对,在连续卷积的情况下,需要
个卷积层堆叠在一起,在离散卷积[9]的情况下需要
个卷积层,这就增加了网络中任一两个位置间的最长路径的长度。卷积层的开销通常是递归层的 k 倍。可分离卷积[10]极大地降低了复杂度至
。然而,即使 k = n 时,可分离卷积的复杂度和一个自注意力层与一个逐点前馈层的组合的复杂度一致,即作者在模型中使用的方法。
作为附带好处,自注意力可以生成更具解释性的模型。作者从模型中检查注意力分布,并在附录中介绍和讨论示例。各个注意力头部不仅清楚地学会执行不同任务,许多注意力头部还似乎表现出与句子的句法和语义结构相关的行为。
原文:https://www.cnblogs.com/sddai/p/15146897.html