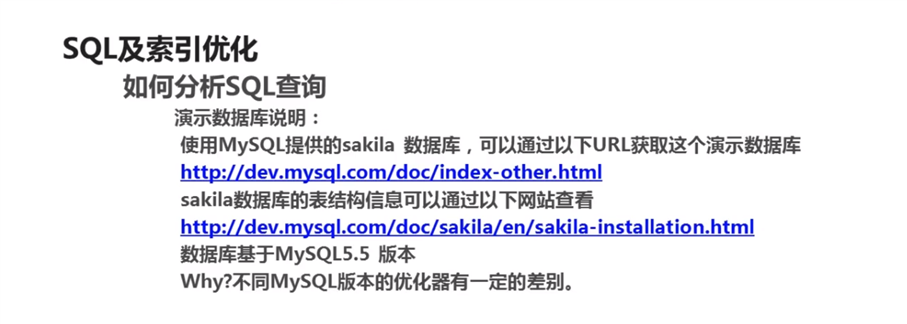
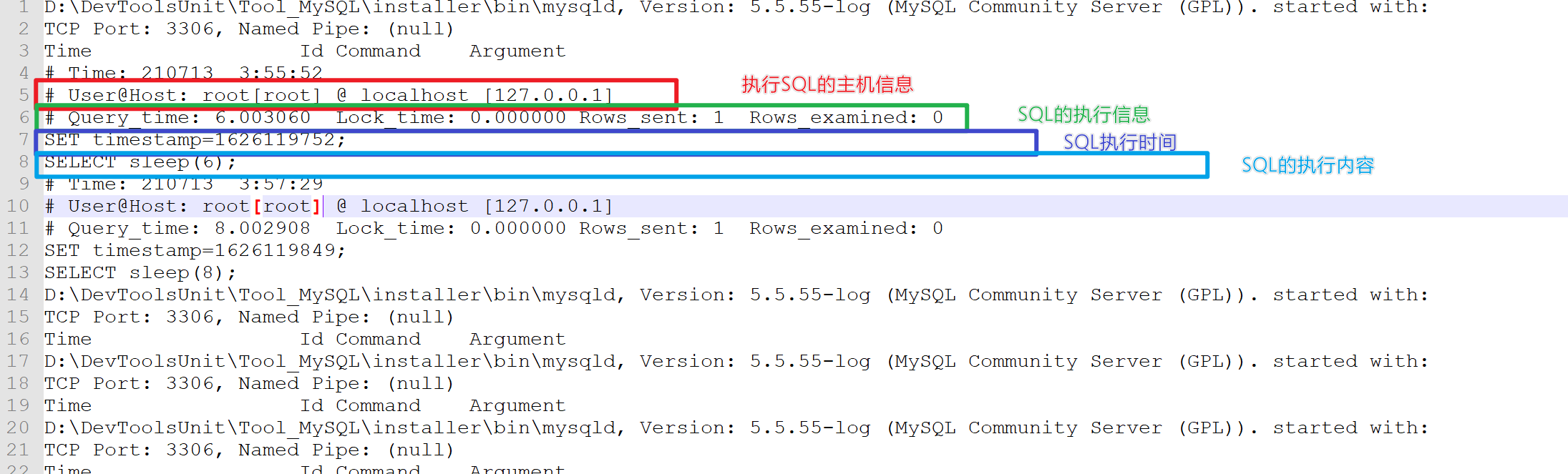
如何发现有问题的SQL 答:使用慢查询日志或EXPLAIN关键字进行语句分析

mysql> show variables like "%query_log%";
+---------------------+----------------------------------+
| Variable_name | Value |
+---------------------+----------------------------------+
| slow_query_log | ON |
| slow_query_log_file | D:/MySQL_data/slow_query_log.txt |
+---------------------+----------------------------------+
2 rows in set (0.00 sec)
mysql> show variables like "long_query_time";
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 3.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
安装连接:





mysql> use sakila;
Database changed
mysql> select max(payment_date) from payment;
+---------------------+
| max(payment_date) |
+---------------------+
| 2006-02-14 15:16:03 |
+---------------------+
1 row in set (0.12 sec)
mysql> explain select max(payment_date) from payment;
+----+-------------+---------+------+---------------+------+---------+------+-------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+-------+-------+
| 1 | SIMPLE | payment | ALL | NULL | NULL | NULL | NULL | 16451 | |
+----+-------------+---------+------+---------------+------+---------+------+-------+-------+
1 row in set (0.03 sec)
mysql> create index idx_payment_date on payment(payment_date);
Query OK, 0 rows affected (0.40 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select max(payment_date) from payment;
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
1 row in set (0.00 sec)
COUNT(*)和COUNT(1)都会将 null 统计在内
mysql> select * from tmp;
+------+
| id |
+------+
| NULL |
| 2 |
| 3 |
| 0 |
+------+
4 rows in set (0.00 sec)
mysql> select count(*) from tmp;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
mysql> select count(1) from tmp;
+----------+
| count(1) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
使用COUNT的正确案例
eg: 查出2006年电影数量
SELECT COUNT(release_year=‘2006‘ OR NULL)
FROM film;

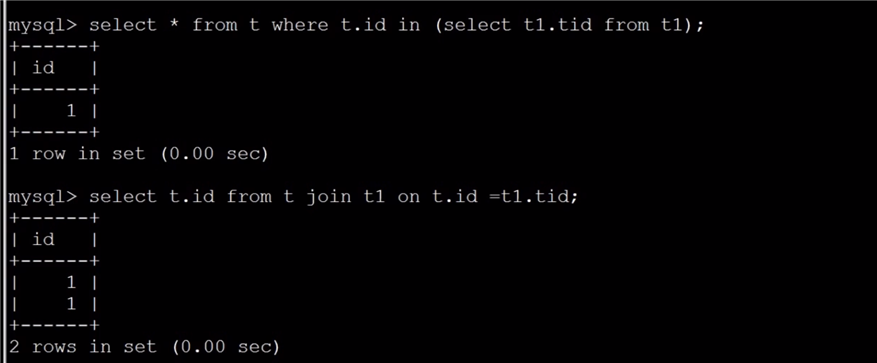


mysql> EXPLAIN select film_id, description from film order by title limit 50;
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| 1 | SIMPLE | film | ALL | NULL | NULL | NULL | NULL | 949 | Using filesort |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
1 row in set (0.00 sec)
mysql> EXPLAIN select film_id, description from film order by film_id limit 50;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| 1 | SIMPLE | film | index | NULL | PRIMARY | 2 | NULL | 50 | |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
1 row in set (0.04 sec)
mysql> EXPLAIN select film_id, description from film where film_id > 55 and film_id <= 60 order by film_id limit 1, 5;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | film | range | PRIMARY | PRIMARY | 2 | NULL | 5 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
1 row in set (0.05 sec)
避免了数据量大时扫描过多的记录(保证索引有序)

mysql> select count(distinct customer_id), count(distinct staff_id) from payment;
+-----------------------------+--------------------------+
| count(distinct customer_id) | count(distinct staff_id) |
+-----------------------------+--------------------------+
| 599 | 2 |
+-----------------------------+--------------------------+
1 row in set (0.01 sec)
customer_id的离散程度 高于 staff_id






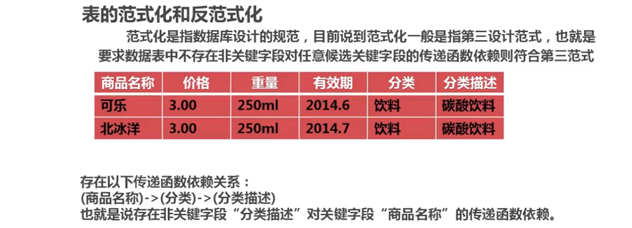
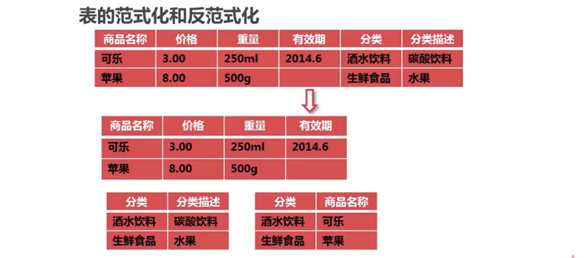
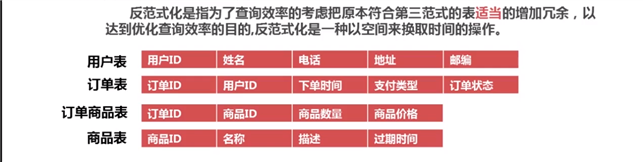
反范式优化







原文:https://www.cnblogs.com/openmind-ink/p/15139500.html