最近复习到redis底层编码的时候突然想到这个问题,为什么hash比string做缓存更节省内存与效率更高?一时间没想明白,百度一大堆一个关键点都没有答上的,全是介绍什么ziplist、sds编码就没了,至于问题关键在哪也没说明白,最烦这种人了,把博客生态都搞得乱七八糟的,这里我把自己的想法分享给大家,不对的话请指教。 ps:我都是写有道云笔记的。
首先看到我的答案前提下需要先了解hash的ziplist跟string的sds编码,这个我就不说了,还是很好查到资料的
我也简单说明一点吧:
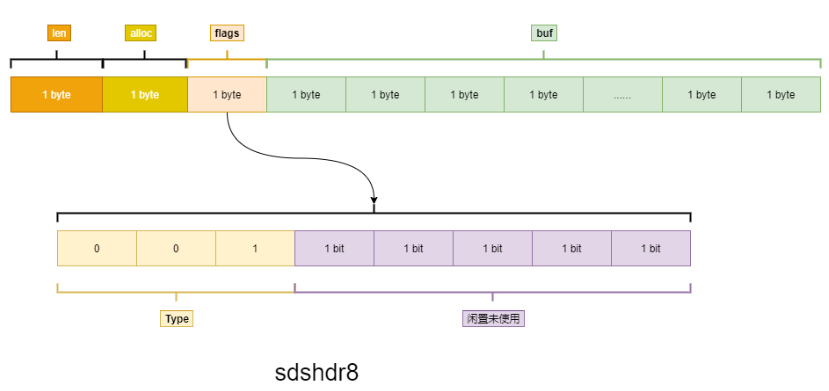
string底层采用sds编码(在不是数据的情况下),在redis3.2版本后会根据string的大小来采用不同的位数的sds编码,下面是不同的sds中c语言源码跟sdshdr8格式结构图:
1 typedef char *sds; 2 struct __attribute__ ((__packed__)) sdshdr5 { 3 unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ 4 char buf[]; 5 }; 6 struct __attribute__ ((__packed__)) sdshdr8 { 7 uint8_t len; //已用 8 uint8_t alloc; //buf[]总共分配的长度 9 unsigned char flags; //用于内存对齐放在前面的标识位,char类型占一个字节(8位) 10 char buf[]; 11 }; 12 struct __attribute__ ((__packed__)) sdshdr16 { 13 uint16_t len; /* used */ 14 uint16_t alloc; /* excluding the header and null terminator */ 15 unsigned char flags; /* 3 lsb of type, 5 unused bits */ 16 char buf[]; 17 }; 18 struct __attribute__ ((__packed__)) sdshdr32 { 19 uint32_t len; /* used */ 20 uint32_t alloc; /* excluding the header and null terminator */ 21 unsigned char flags; /* 3 lsb of type, 5 unused bits */ 22 char buf[]; 23 }; 24 struct __attribute__ ((__packed__)) sdshdr64 { 25 ........
下面是ziplist的结构图:

答案:
redis中为什么hash比string做缓存更节省内存与效率更高?
原文:https://www.cnblogs.com/chenzhoulibo/p/15106573.html