1、Hive的存在可以简化MapReduce实现过程
(1)MapReduce编程的不便
(2)传统关系型数据库RDBMS人员的需要
(3)HDFS上的文件没有schema的概念:即没有表明、字段名、字段类型等信息。仅仅是一个字符串的文件。
2、Hive是什么?
(1)由Facebook开源,用于解决海量结构化日志的数据统计问题
(2)构建在Hadoop之上的数据仓库(当计算/存储能力不够,直接线性添加机器即可)
(3)Hive提供的SQL查询语言:HQL
(4)Hive底层支持多种不同的执行引擎:MR/Tez/Spark(在Hive里通过一个参数设置,即可更换底层引擎执行。客户对引擎是不感知的)
(5)使用SQL对海量数据的数据进行统计、分析的一个工具。
3、使用Hive的原因
(1)简单、容易上手
(2)为超大数据集设计的一个计算/存储扩展能力
(3)提供了统一的元数据管理:
Hive数据是存放在HDFS(普通的文本)上
元数据信息(记录数据[HDFS上的数据]的数据[描述HDFS的数据])是存放在MySQL中。
SQL on Hadoop 提供的框架:Hive、Spark SQL、impala....(因为有统一的元数据管理,使用的框架可以任意更换,方便Hive上的作业移植到其他平台中)
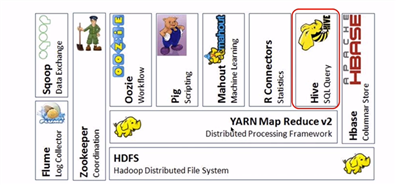
4、Hive在Hadoop生态系统中的位置
(1)Hive是构建在Hadoop之上的数据仓库,数据是存放在HDFS上的。
(2)当作业运行,即一个sql经过Hive,会自动翻译成MapRrduce作业,然后作业提交给YARN运行。然后不用担心MapRrduce到底是怎么实现了。
原文:https://www.cnblogs.com/jieqiong1755/p/15070947.html