“在阿里和很多互联网企业中有一个“沉默的大多数”的应用,就是推荐系统:它常常占据了超过80%甚至90%的机器学习算力。”
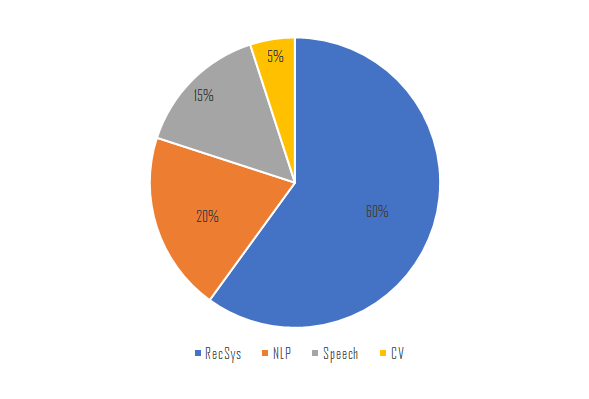
Facebook AI cycles allocation
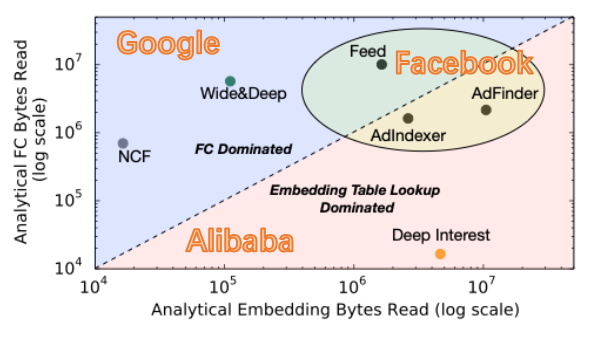
推荐系统占据了Facebook 50%的AI训练算力,80%的AI推理算力。

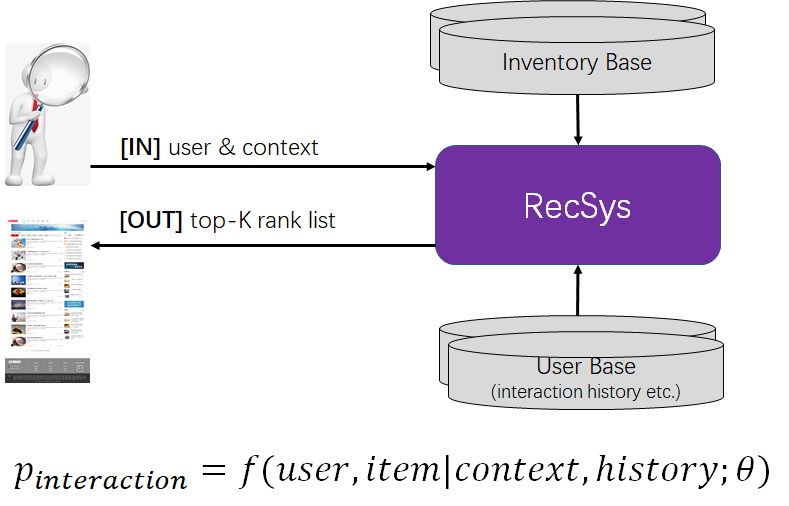
在给定用户和用户上下文(如入口、时间、地域、用户的人口统计学数据等)的情况下,计算用户与库存(如商品、文章、用户等)发生交互(如点击、购买、连接等)的概率,并筛选最有可能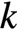 个库存推荐给用户,促成交互和转化。
个库存推荐给用户,促成交互和转化。
算法KPI - 开源
提高用户对推荐结果的交互率和转化率,这个是算法研究的范畴。
性能KPI - 可用+节流
Latency-Bound Throughput,在满足要求的延时SLA(Service Level Agreement)的条件下,提高系统的吞吐。这个是系统的范畴。

如:
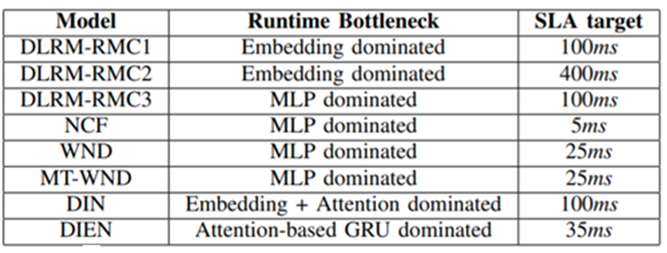
算法设计上,大致可以按下图来划分。目前主流工业使用以DNN models为主,这也是本文的目标workload。
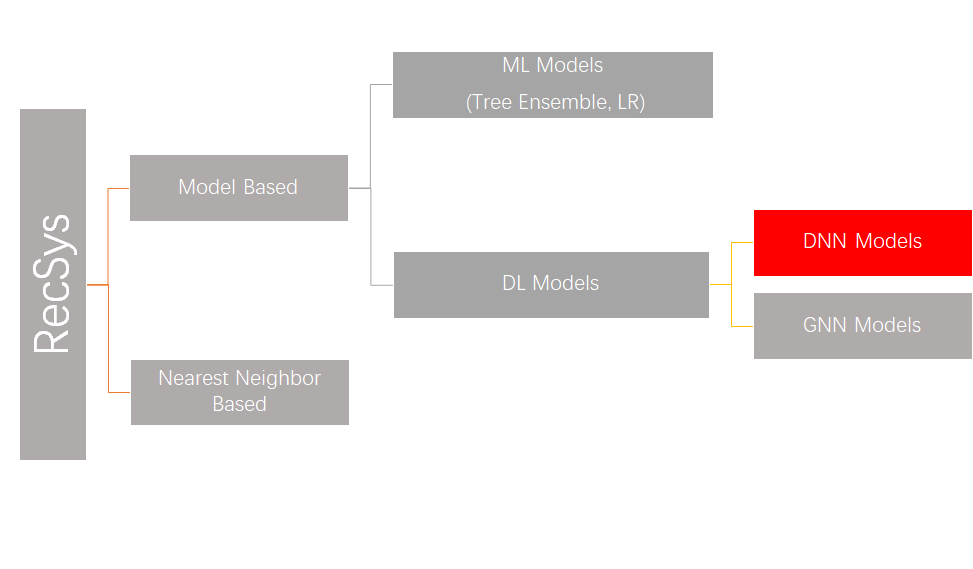
DNN RecSys Model = Feature Engineering + Feature Interaction + Predictor DNN
不同的feature engineering, feature interaction和predictor DNN的选型造就了不同的模型和workload特性。
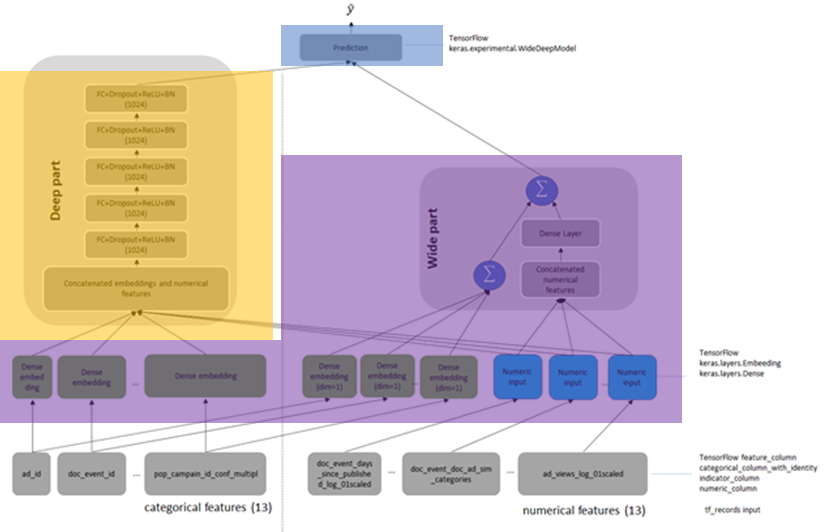
Wide and Deep Learning (WDL)
Deep Interest Network (DIN)
Deep Interest Evolution Network (DIEN)
Deep Learning Recommendation Model (DLRM)
算法主要思路
Wide for memorization, deep for generalization
选型
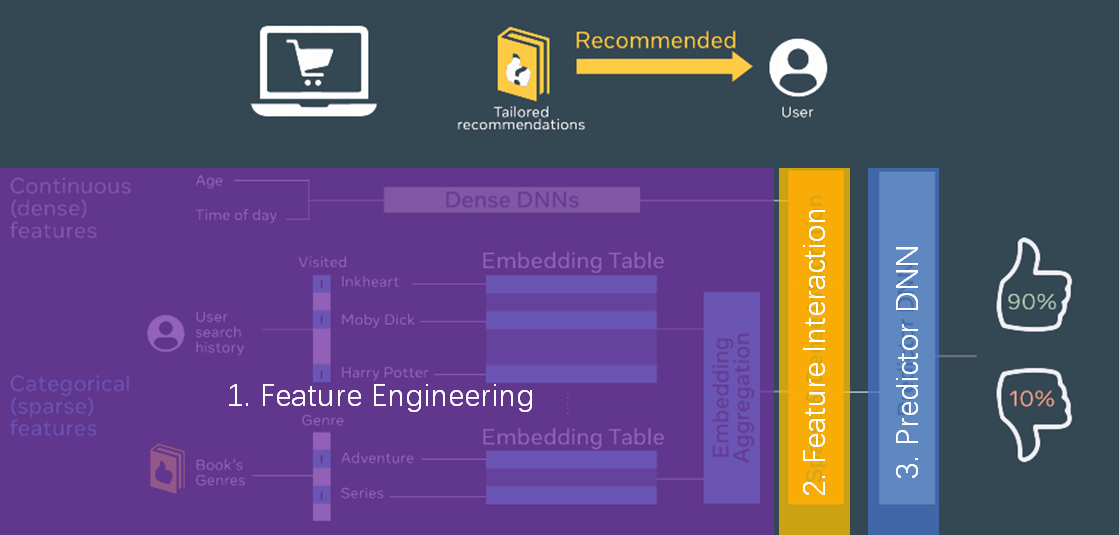
Feature Engineering
embedding_lookup
hash bucketing
slice (tensor manipulation)
concat (tensor manipulation)
dense fc
Feature Interaction
concat (tensor manipulation)
MLP (Multi-Layer Perception)
Predictor DNN
fc
算法主要思路
Attention, weighting interaction influence with similarity
选型
Feature Engineering
embedding_lookup
concat (tensor manipulation)
Feature Interaction
batch matrix multiplication
sum pooling (tensor manipulation)
concat (tensor manipulation)
Predictor DNN
MLP
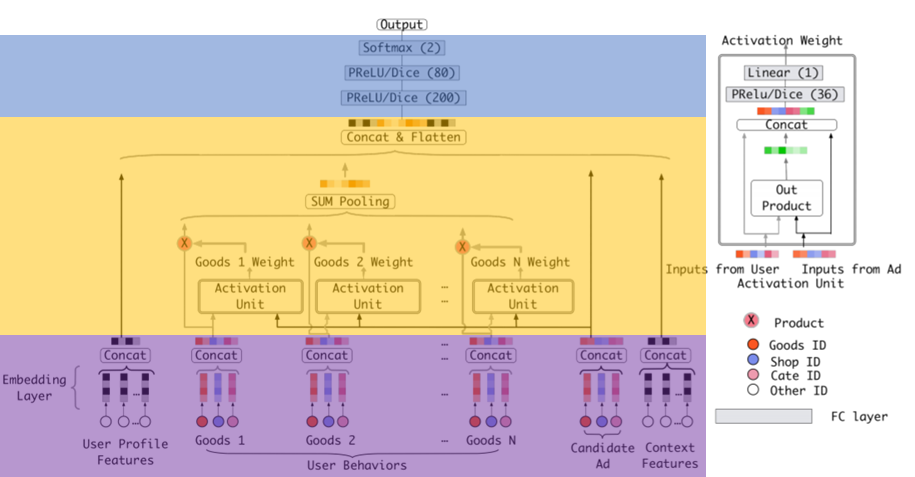
算法主要思路
Introduce time-decay effect to attention
选型
Feature Engineering
embedding_lookup
concat (tensor manipulation)
Feature Interaction
GRU (Gated Recurrent Unit)
concat (tensor manipulation)
Predictor DNN
MLP
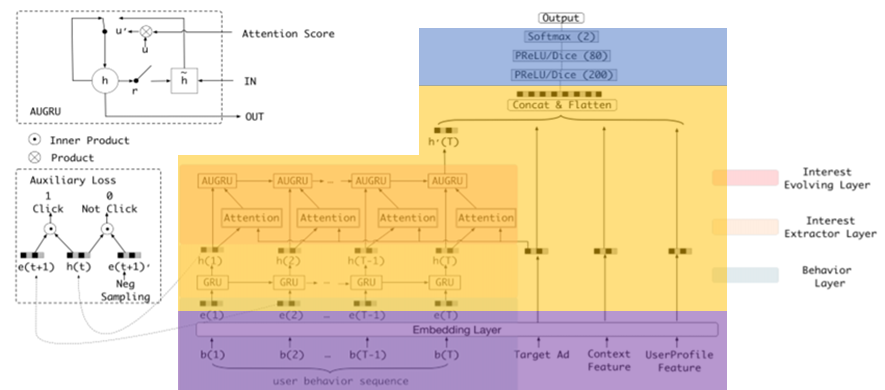
算法主要思路
Interaction using auto-correlation
选型
Feature Engineering
embedding_lookup
sum pooling (tensor manipulation)
fc
Feature Interaction
batch matrix multiplication
Predictor DNN
MLP
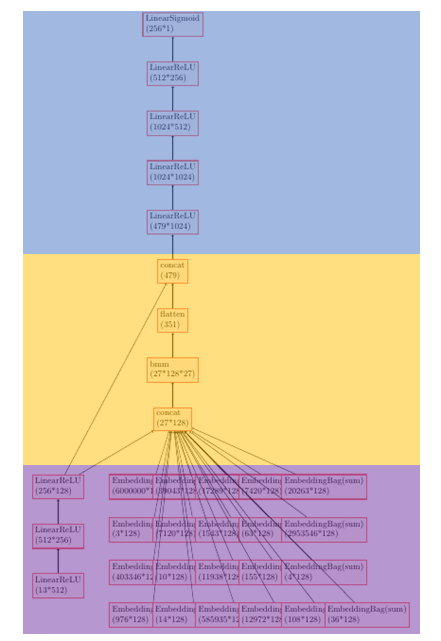
Each record of Criteo TeraByte Dataset
13 numerical features + 26 categorical feature = 156 B
DLRM open-source Model
~24 billion parameters = 96 GB, most of them are embedding tables
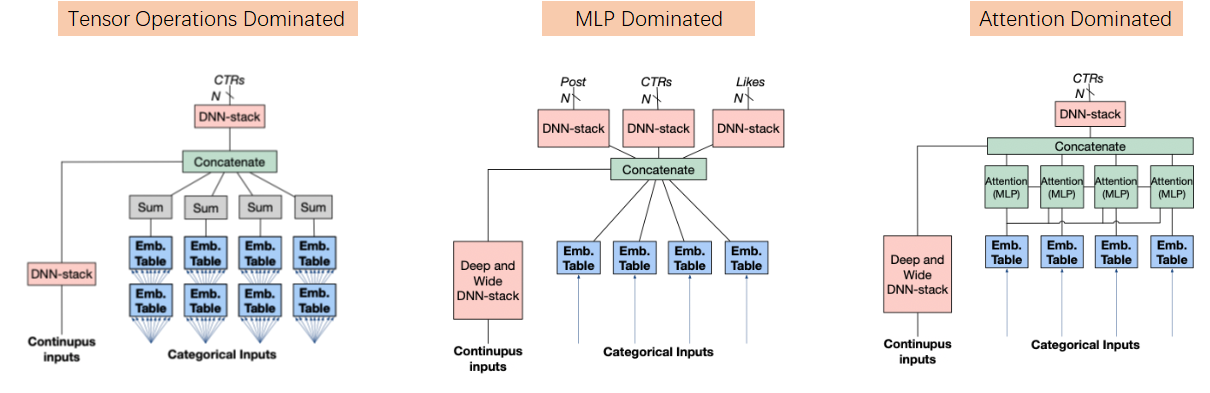
It leads to lower Computational Intensity than CNN workloads.
Tensor operations which are Embedding Lookup & Tensor Manipulation occupy a non-negligible part.
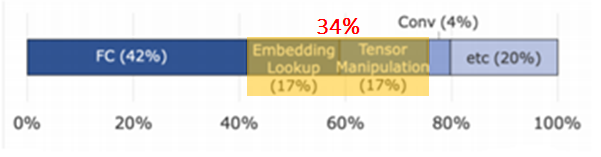
Diverse combinations of 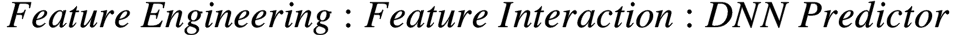 lead to workload heterogeneity.
lead to workload heterogeneity.
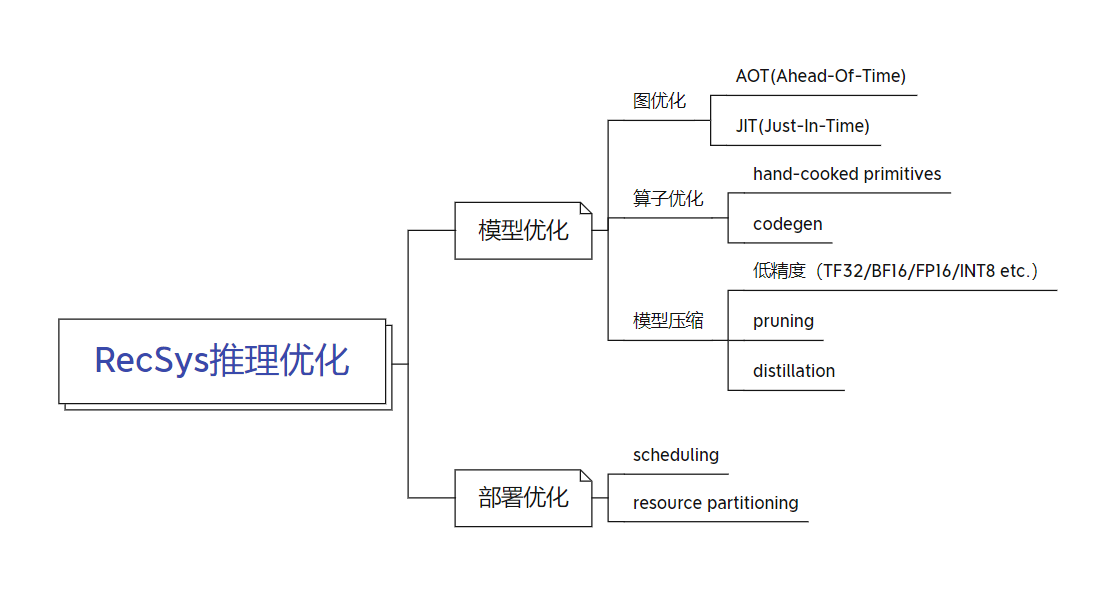
其中,模型优化专注于优化模型自身的性能,部署优化专注于优化模型在部署环境尤其是混部环境下的性能。
#1. Minimize system(HW/SW) overheads
minimize scheduling overhead
minimize function calls
use thread pool
use big thread (i.e. graph fusion/stitching)
[accelerator cases] minimize kernel launch overhead
use big kernel (i.e. graph fusion)
#2. Roofline analysis driven TFLOPS improvement
improve attainable TFLOPS
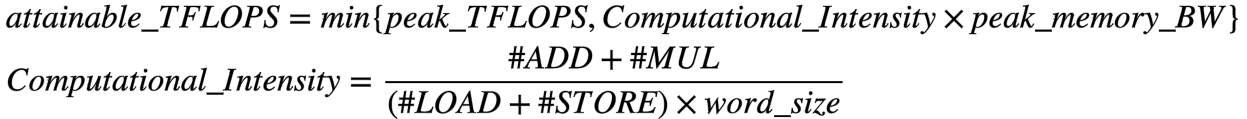
improve actual TFLOPS
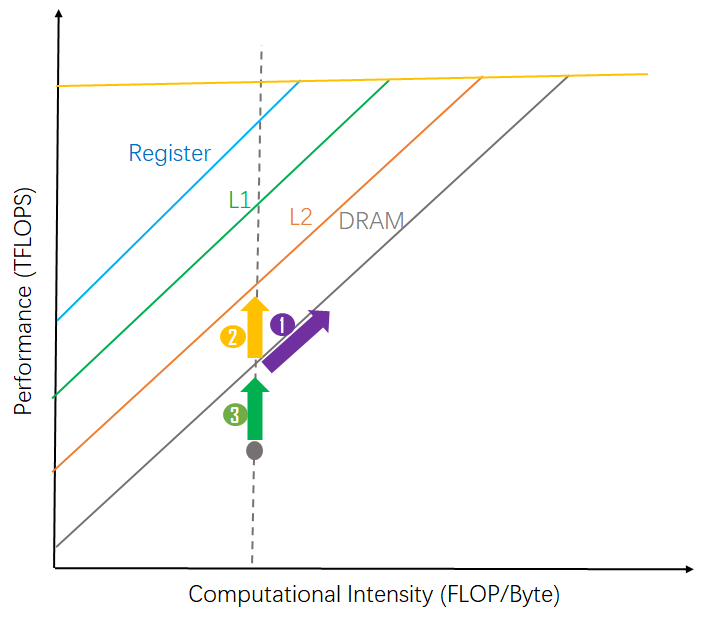
1 - improve computational intensity by decreasing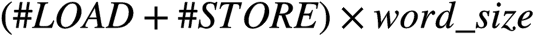
2 - improve attainable TFLOPs by improving peak memory BW
3 - improve actual TFLOPS
graph fusion/stitching
[#1] minimize kernel launch overhead
[#1] minimize unnecessary bad argument check
[#2.2] in-register/cache computing
[#2.3] more parallelism
embedding_lookup fusion
Facebook multiple embedding_lookup fusion brings 7x unit level performance improvement.
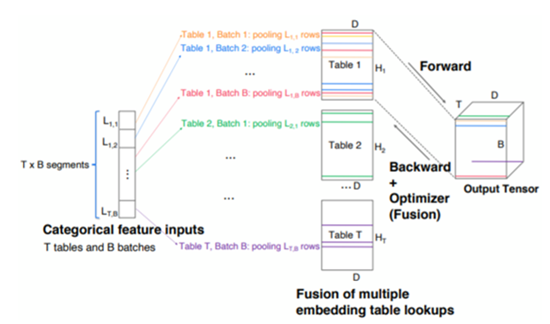
tensor manipulation sub-graph fusion
Feature engineering sub-graph fusion brings 2x unit level performance improvement w/ XLA CPUInstructionFusion pass.
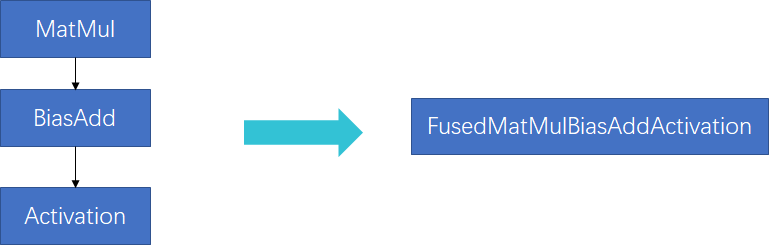
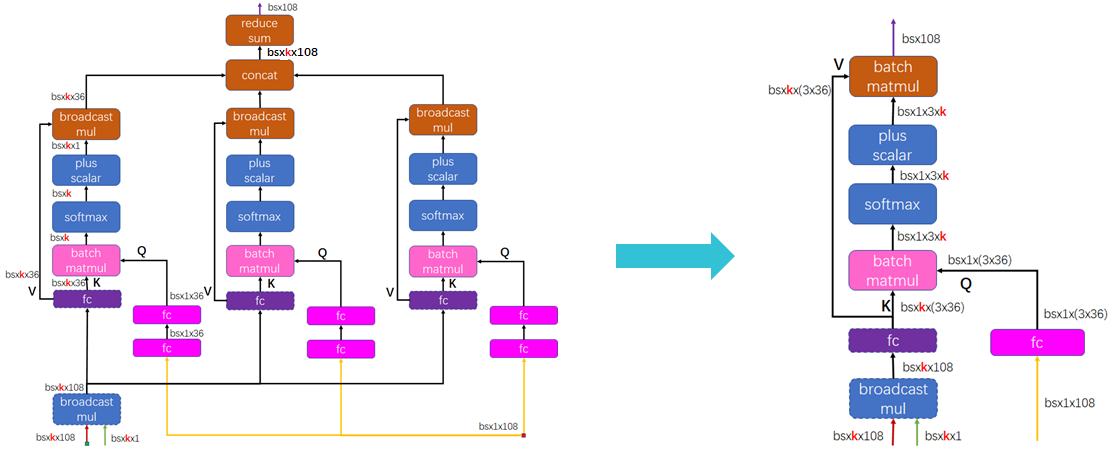
“MatMul + BiasAdd + Activation” 是FC子图中的典型子图,也是graph optimizer(如TF Grappler等)一般都会实现的graph optimization pass。目前主要是基于模板匹配的方式来实现。
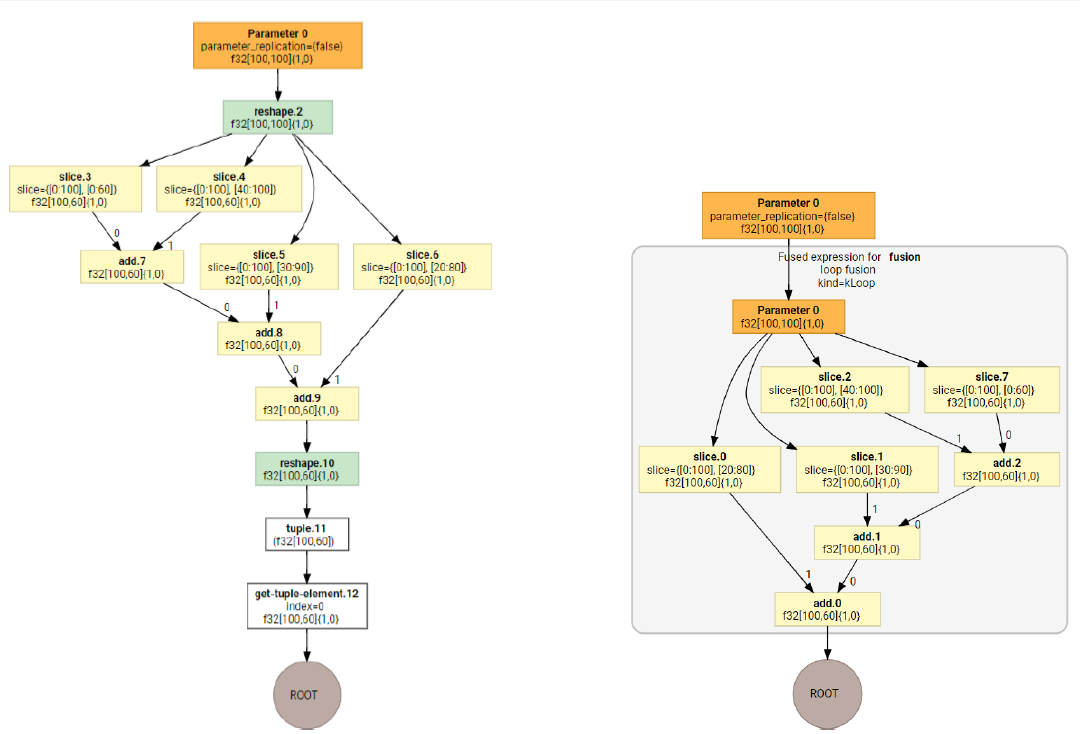
在RecSys中的一个复杂性在于,对于同一个”MatMul + BiasAdd + Activation”语义,经常会有不同子图形式,下面给出两种:
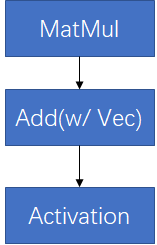
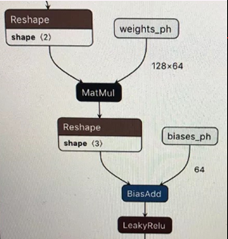
可以看到,虽然上述两个子图语义上仍然是”MatMul+BiasAdd+Activation”, 但由于形式上已经产生变化,基于模板匹配的子图融合pass对他们并不能正确地辨识和融合,需要使用更高抽象度的融合pass去辨识。实践也表明,增强的pass会给线上inference带来20%左右的latency减少。
Multi-Head Attention作为attention结构的基本子图,仔细分析并做极致优化是非常有必要的。
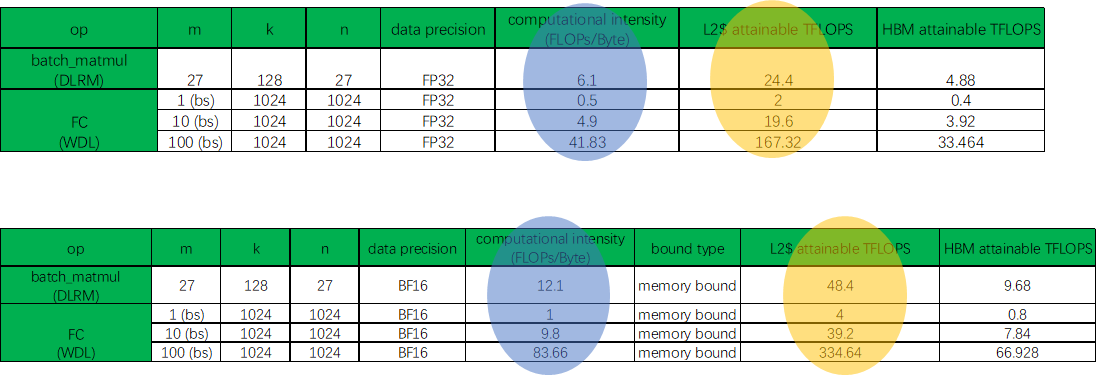
reduce precision: FP32 → BF16
reduce data traffic
FC: keep packed weight to amortize weight packing traffic
DLRM batchMatMul – only load A while compute AAT by leveraging HW transposer
DLRM index – de-duplicate indices
remove 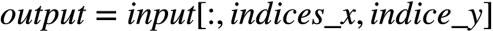 data traffic
data traffic
Improve cache residence
假想系统参数 L2$ peak BW(TB/s) 4 HBM2e peak BW(TB/s) 0.8 BF16 peak TFLOPS 512
Mixed deployment brings deployment optimization
Model co-location brings performance variance (noisy neighbors)
Optimal hardware varies across dynamic batch size([1, 100]) & different models
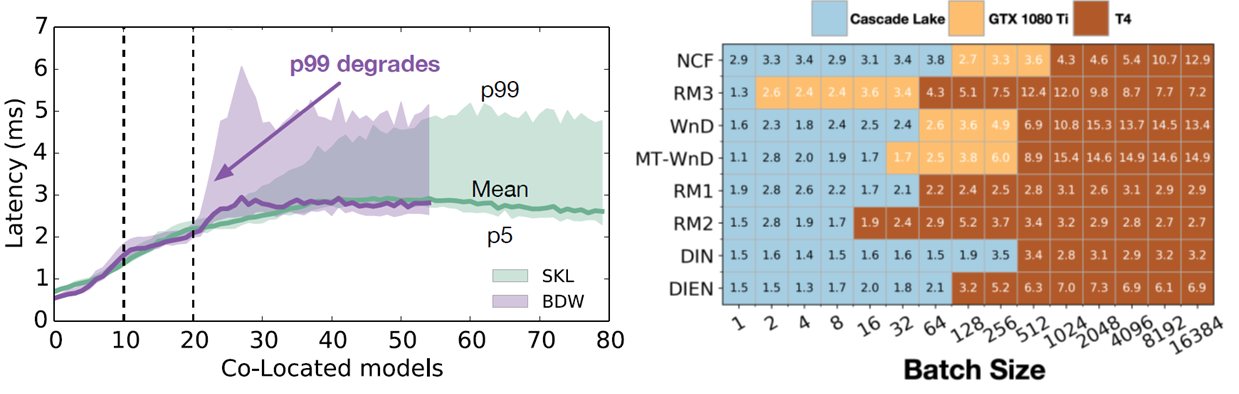
Facebook proposed DeepRecSched to search good deployment configurations with dry-run. Facebook的实验报告了在CPU上~2x的QPS,在GPU上~5x的QPS。
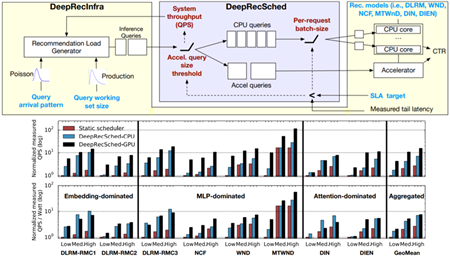
其他探索可见《深度学习推理性能优化》 部署优化部分。
主要有两个方向:
近内存计算
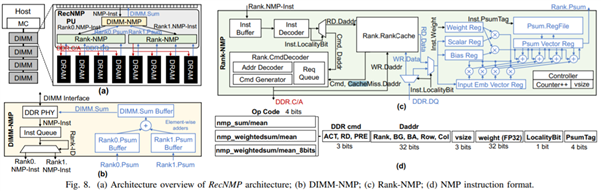
代表性的工作有Facebook的NMP(Near Memory Processor), 主要是通过把embedding_lookup_reduction操作放到内存模组里面来完成,从而在不提高内存的物理带宽的前提下提高有效带宽。Facebook报告了9.8x的延时减少和4.2x的吞吐提高,基于内部的embedding-dominated的模型族。
data pipeline in SoC
Intel
Intel 计划在Sapphire Rapids CPU中引入一些data accelerator IP, 如DSA(Data Streaming Accelerator)。把memory intensive的部分从CPU指令中解放出来,offload到一个专门的IP中来实现。这为实现片上data pipeline、提高workload吞吐提供了一种可能。

DeepRecSys: A System for Optimizing End-To-End At-scale Neural Recommendation Inference
The Architectural Implications of Facebook’s DNN-based Personalized Recommendation
Cross-Stack Workload Characterization of Deep Recommendation Systems
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Accelerating the Wide & Deep Model Workflow from 25 Hours to 10 Minutes Using NVIDIA GPUs
Applying the Roofline Model for Deep Learning performance optimizations
RecNMP: Accelerating Personalized Recommendation with Near-Memory Processing
MicroRec: Efficient Recommendation Inference by Hardware and Data Structure Solutions
AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Optimizing Recommendation System Inference Performance Based on GPU
原文:https://www.cnblogs.com/Matrix_Yao/p/15037865.html