一、架构图:
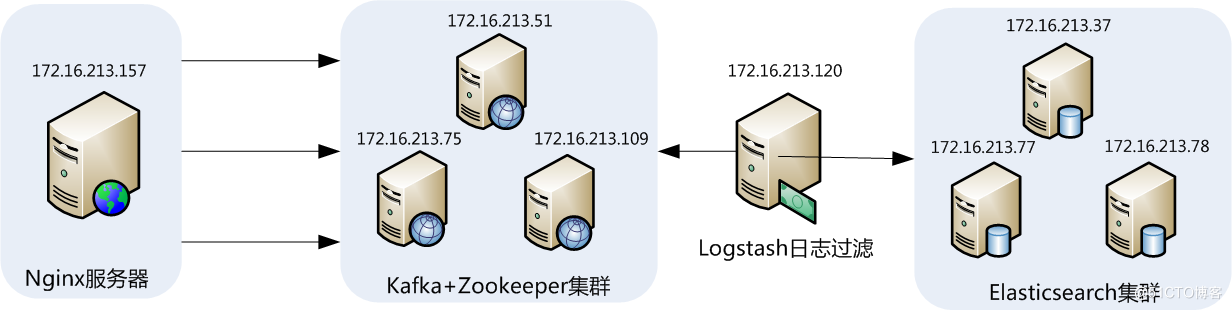
二、日志收集方式:
ELK收集日志常用的有两种方式,分别是:
(1)不修改源日志的格式,而是通过logstash的grok方式进行过滤、清洗,将原始无规则的日志转换为规则的日志。
(2)修改源日志输出格式,按照需要的日志格式输出规则日志,logstash只负责日志的收集和传输,不对日志做任何的过滤清洗。
这两种方式各有优缺点:
第一种方式不用修改原始日志输出格式,直接通过logstash的grok方式进行过滤分析,好处是对线上业务系统无任何影响,缺点是logstash的grok方式在高压力情况下会成为性能瓶颈,如果要分析的日志量超大时,日志过滤分析可能阻塞正常的日志输出。因此,在使用logstash时,能不用grok的,尽量不使用grok过滤功能。
第二种方式缺点是需要事先定义好日志的输出格式,这可能有一定工作量,但优点更明显,因为已经定义好了需要的日志输出格式,logstash只负责日志的收集和传输,这样就大大减轻了logstash的负担,可以更高效的收集和传输日志。另外,目前常见的web服务器,例如apache、nginx等都支持自定义日志输出格式。因此,在企业实际应用中,第二种方式是首选方案。
三、配置filebeat
filebeat是安装在Nginx服务器上:
| filebeat.inputs: | |
| ? | - type: log |
| ? | enabled: true |
| ? | paths: |
| ? | - /var/log/nginx/access.log |
| ? | fields: |
| ? | log_topic: nginxlogs |
| ? | filebeat.config.modules: |
| ? | path: ${path.config}/modules.d/*.yml |
| ? | reload.enabled: false |
| ? | name: 172.16.213.157 |
| ? | output.kafka: |
| ? | enabled: true |
| ? | hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"] |
| ? | version: "0.10" |
| ? | topic: ‘%{[fields.log_topic]}‘ |
| ? | partition.round_robin: |
| ? | reachable_only: true |
| ? | worker: 2 |
| ? | required_acks: 1 |
| ? | compression: gzip |
| ? | max_message_bytes: 10000000 |
| ? | logging.level: debug |
| ? | 这个配置文件中,是将Nginx的访问日志/var/log/nginx/access.log内容实时的发送到kafka集群topic为nginxlogs中。需要注意的是filebeat输出日志到kafka中配置文件的写法。 |
| ? | 配置完成后,启动filebeat即可: |
| ? | [root@filebeatserver ~]# cd /usr/local/filebeat |
| ? | [root@filebeatserver filebeat]# nohup ./filebeat -e -c filebeat.yml & |
| ? | 启动完成后,可查看filebeat的启动日志,观察启动是否正常。 |
?
四、配置logstash
由于在Nginx输出日志中已经定义好了日志格式,因此在logstash中就不需要对日志进行过滤和分析操作了,下面直接给出logstash事件配置文件kafka_nginx_into_es.conf的内容:
| input { | |
| ? | kafka { |
| ? | bootstrap_servers => "172.16.213.51:9092,172.16.213.75:9092,172.16.213.109:9092" |
| ? | topics =>"nginxlogs" #指定输入源中需要从哪个topic中读取数据,这里会自动新建一个名为nginxlogs的topic |
| ? | group_id => "logstash" |
| ? | codec => json { |
| ? | charset => "UTF-8" |
| ? | } |
| ? | add_field => { "[@metadata][myid]" => "nginxaccess-log" } #增加一个字段,用于标识和判断,在output输出中会用到。 |
| ? | } |
| ? | } |
| ? | ? |
| ? | filter { |
| ? | if [@metadata][myid] == "nginxaccess-log" { |
| ? | mutate { |
| ? | gsub => ["message", "\\x", "\\\x"] #这里的message就是message字段,也就是日志的内容。这个插件的作用是将message字段内容中UTF-8单字节编码做替换处理,这是为了应对URL有中文出现的情况。 |
| ? | } |
| ? | if ( ‘method":"HEAD‘ in [message] ) { #如果message字段中有HEAD请求,就删除此条信息。 |
| ? | drop {} |
| ? | } |
| ? | json { |
| ? | source => "message" |
| ? | remove_field => "prospector" |
| ? | remove_field => "beat" |
| ? | remove_field => "source" |
| ? | remove_field => "input" |
| ? | remove_field => "offset" |
| ? | remove_field => "fields" |
| ? | remove_field => "host" |
| ? | remove_field => "@version“ |
| ? | remove_field => "message" |
| ? | } |
| ? | } |
| ? | } |
| ? | output { |
| ? | if [@metadata][myid] == "nginxaccess-log" { |
| ? | elasticsearch { |
| ? | hosts => ["172.16.213.37:9200","172.16.213.77:9200","172.16.213.78:9200"] |
| ? | index => "logstash_nginxlogs-%{+YYYY.MM.dd}" #指定Nginx日志在elasticsearch中索引的名称,这个名称会在Kibana中用到。索引的名称推荐以logstash开头,后面跟上索引标识和时间。 |
| ? | } |
| ? | } |
| ? | } |
这个logstash事件配置文件非常简单,没对日志格式或逻辑做任何特殊处理,由于整个配置文件跟elk收集apache日志的配置文件基本相同,因此不再做过多介绍。所有配置完成后,就可以启动logstash了,执行如下命令:
[root@logstashserver ~]# cd /usr/local/logstash
[root@logstashserver logstash]# nohup bin/logstash -f kafka_nginx_into_es.conf &
logstash启动后,可以通过查看logstash日志,观察是否启动正常,如果启动失败,会在日志中有启动失败提示。
五、配置Kibana
Filebeat从nginx上收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,我们就可以在Kibana中配置索引了。
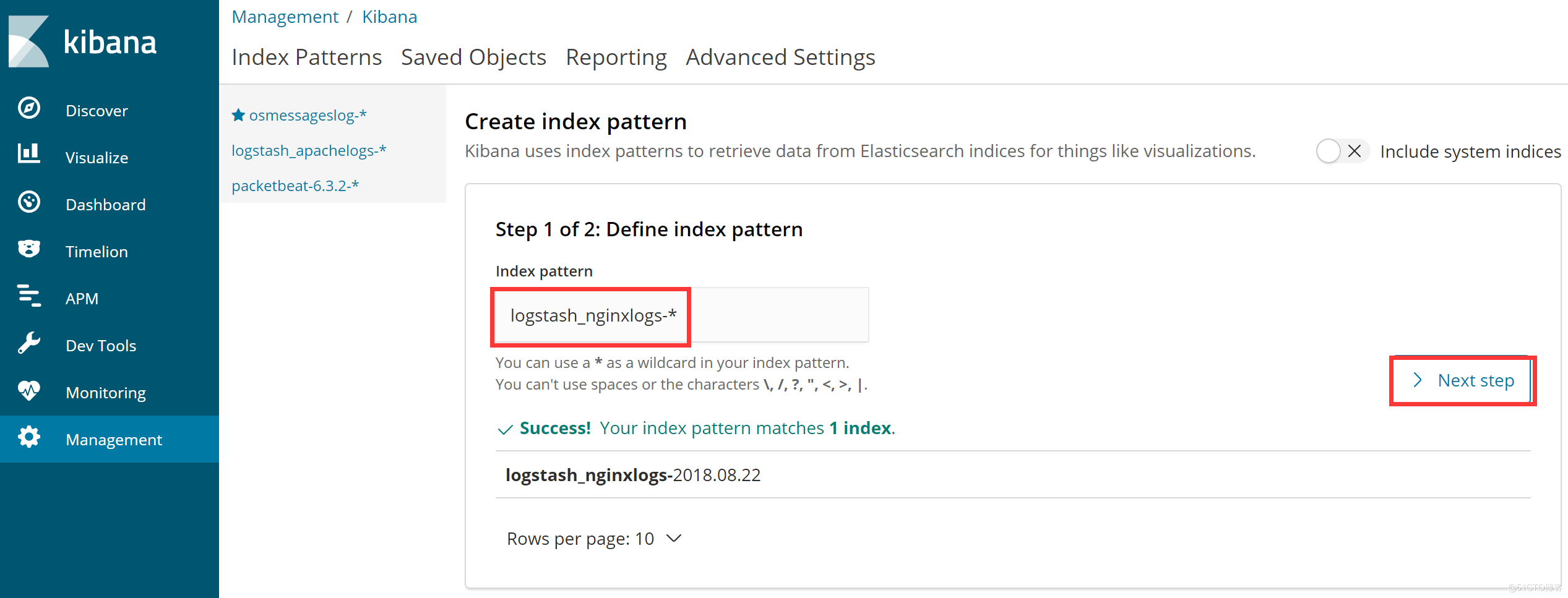
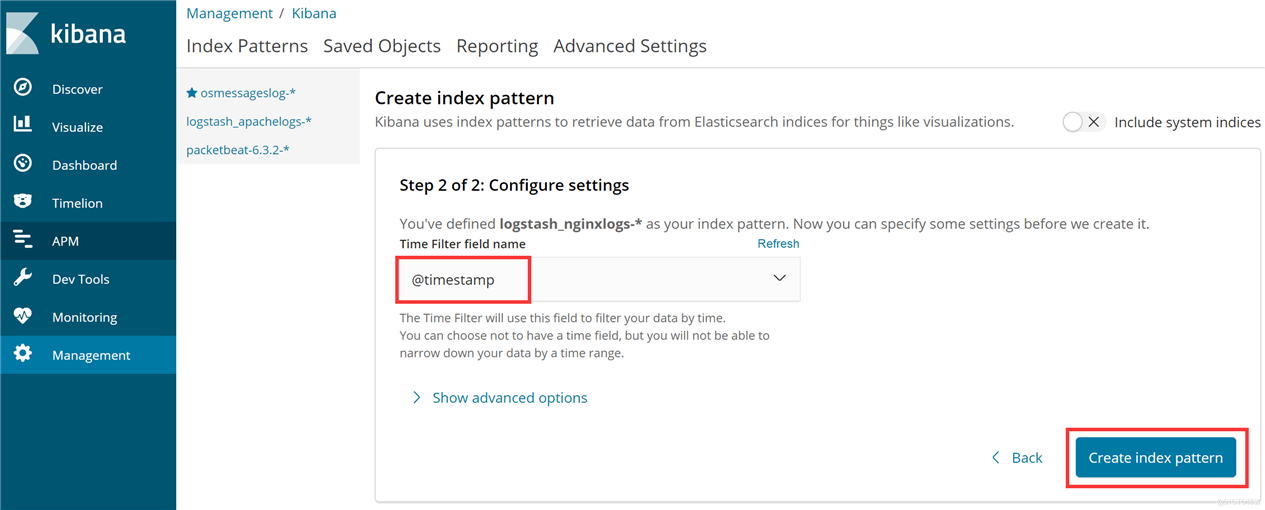
登录Kibana,首先配置一个index_pattern,点击kibana左侧导航中的Management菜单,然后选择右侧的Index Patterns按钮,最后点击左上角的Create index pattern,开始创建一个index pattern,如下图所示:
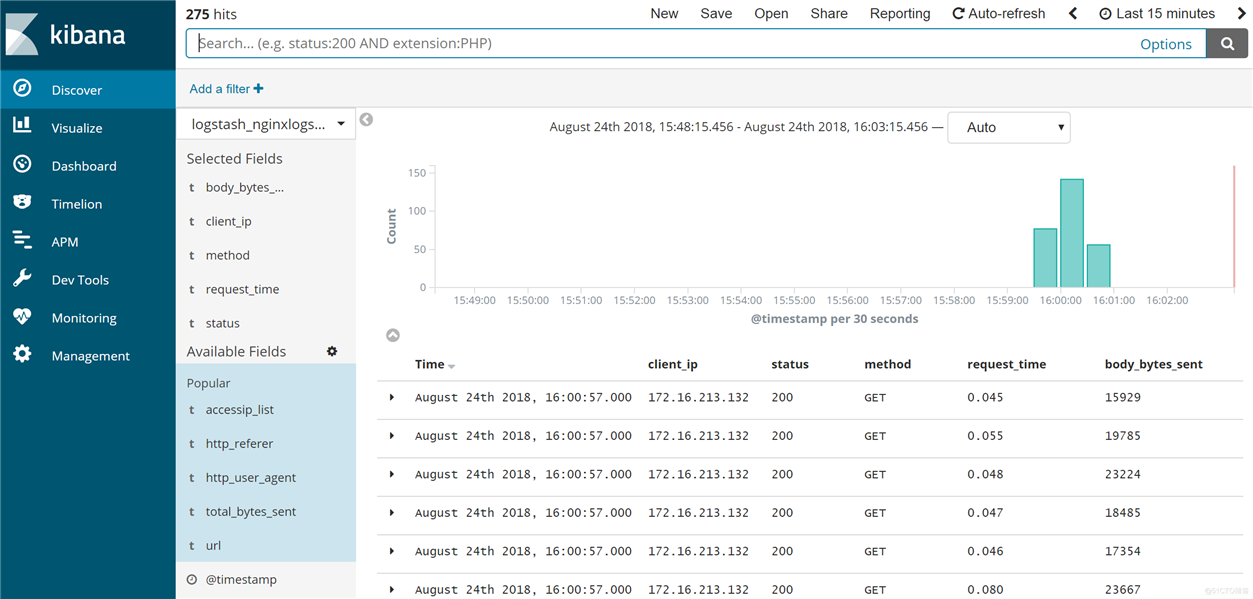
至此,ELK收集Nginx日志的配置工作完成
原文:https://blog.51cto.com/u_11110720/3146964