编译器或者运行时环境为了优化程序性能而采取的对指令进行重排序的一种手段。
也就是说,对于下面两条语句:
int a=10;
int b=10;
在计算机执行上面两句话的时候,有可能第二条语句会先于第一条语句的执行。所以,千万不要假设指令执行的顺序。
答案是否定的,为了将清除这个问题,先讲解另一个概念:数据依赖性
2.1、什么是数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖。数据依赖分为下列三种类型:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a=1;b=a; | 写一个变量之后,在读这个变量 |
| 写后写 | a=1;a=2; | 写一个变量之后,在改变这个变量的值 |
| 读后写 | a=b;b=1; | 读一个变量之后,在改变这个变量的值 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。所以,编译器和处理器在重排顺序的时候,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。也就是说:在单线程环境下,指令执行的最终效果应当与器在顺序执行下的效果一致,否则这种优化便会失去意义。这句话有个专业术语叫做as-if-serial语义
as-if-serial语义的意思是指不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能改变,编译器、runtime和处理器都必须遵守as-if-serial语义
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。
现在让我们来看看,重排序是否会改变多线程程序的执行结果,请看下面的示例代码:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
flag变量是个标记,用来标识变量a是否已经被写入。这里假设有两个线程A和B,A首先执行write方法,随后B线程接着执行reader()方法。线程B在执行操作4的时候,能否看到线程A在操作1对共享变量的写入吗?
这里是不一定能够看到
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4也没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作1和操作2重排序的时候,可能会产生什么效果?请看下面的
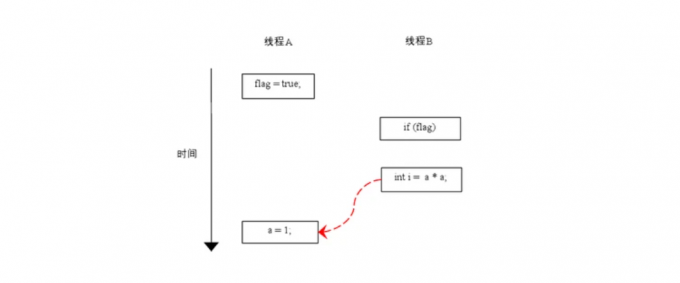
如上图所示,操作1和操作2做了重排序。程序执行的时候,线程A首先写标记变量flag,随后随后线程B读了这个变量。由于条件判断为真,线程B将读取变量a,此时变量a还根本没有被线程A写入,在这里多线程程序的语义被重排序破坏了。
注意:本文同一用红色的虚线表示错误的读操作,用绿色的虚箭线表示正确的读操作
下面再让我们看看,当操作3和操作4重排序的时候会产生什么效果(借助这个重排序,可以顺便说明控制依赖性),下面是操作3和操作4重排序后,程序的执行时序图:
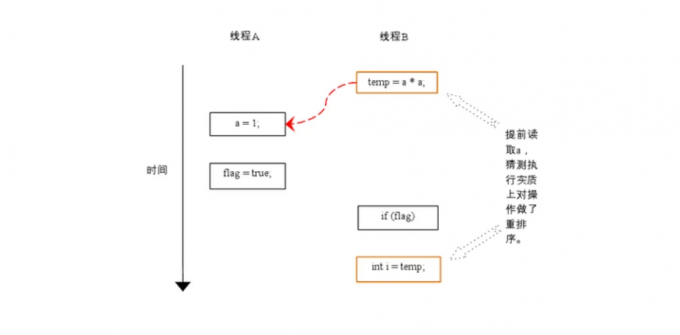
在程序中,操作3和操作4存在控制依赖关系,当代码中存在控制依赖性的时候,会影响程序序列执行的并行度,为此,编译器会采用猜测执行来客服相关性对并行度的影响,以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果保存到一个名为重排序缓冲的硬件缓存中。当接下来的判断条件为真的时候,就把该计算结果写入变量i中。
从图中我们可以看出,猜测执行实质上对操作3和4做了重排序,重排序在这里破坏了多线程程序的语义。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作进行重排序的原因);但在多线程程序中,对存在控制以来的操作重排序,可能会改变程序的执行结果。
本文参考:https://www.infoq.cn/article/java-memory-model-2/
原文:https://www.cnblogs.com/gesh-code/p/15024866.html