本文源于一位读者同学的提问,下图:
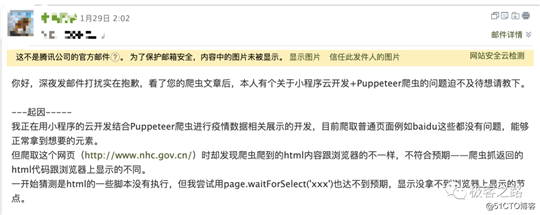
看到这位同学如此好学,博主就也研究了一下,发现确实当使用puppeteer爬取上述政府网的时候会卡住,看下方视频演示:
可以看到在打开页面之后就报错了。
?
后来查找了很多资料终于找到一条可用的方法:
增加参数:--disable-blink-features=AutomationControlled,
作用是:禁用启用Blink运行时的功能
const puppeteer = require(‘puppeteer‘);
(async () => {
const browser = await puppeteer.launch({
headless: false,
args: [
‘--no-sandbox‘,
‘--disable-setuid-sandbox‘,
‘--disable-blink-features=AutomationControlled‘,
],
dumpio: false,
});
const page = await browser.newPage();
await page.evaluate(
‘() =>{Object.defineProperties(navigator,{webdriver:{get: () => false}})}‘
);
await page.goto(‘http://www.nhc.gov.cn/‘, {
waitUntil: ‘networkidle0‘,
});
await page.waitForSelector(‘.intabr.fr‘, {
visible: true,
timeout: 3000,
});
const yqInfoList = await page.evaluate(() => {
const elements = Array.from(
document.querySelectorAll(‘.intabr.fr .yqdt .inLists li‘)
);
return elements.map((s) => {
let a = s.getElementsByTagName(‘a‘).item(0);
let txt = a.innerHTML;
let url = a.getAttribute(‘href‘);
return { title: txt, url: ‘http://www.nhc.gov.cn‘ + url };
});
});
console.log(yqInfoList);
await browser.close();
})();
然后我们再次使用脚本来爬取信息可以顺利得到结果了

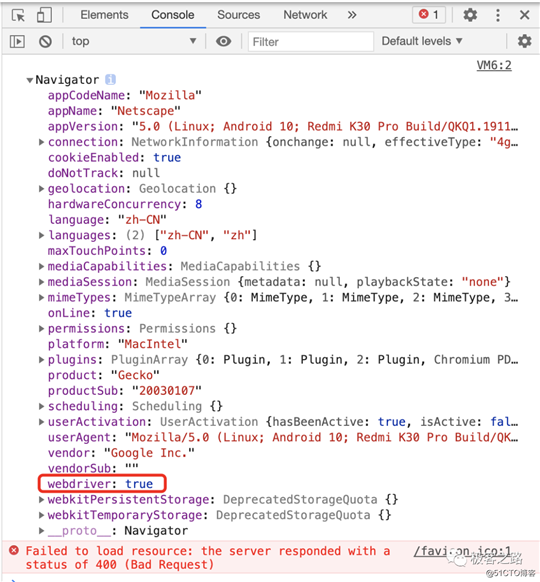
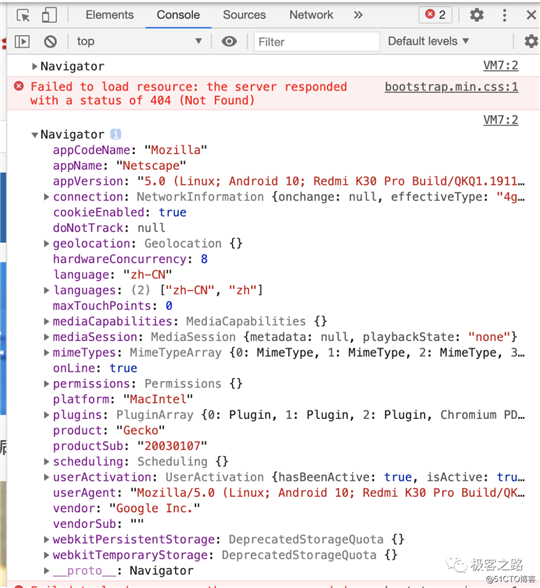
此时如果审查元素会发现,navigator中webdriver属性没了。
?
webdriver可以说是Puppeteer最明显的一个特征,检测也非常简单,获取navigator.webdriver这一属性,在默认启动的Puppeteer中,它的值为true,而在正常浏览器中,navigator里是没有这一属性的,是undefined。
所以我们通过把webdriver的返回置为false就可以使检测失效了,从而获取到想要的信息。
await page.evaluate( ‘() =>{Object.defineProperties(navigator,{webdriver:{get: () => false}})}‘ );
当然也存在许多其它的检测方法,有兴趣的同学可以自行查阅。欢迎交流????。
?
使用puppeteer实现产品经理咖啡自动签到
puppeteer抓取开源中国上的推荐软件数据
puppeteer实现百度贴吧自动签到
原文:https://blog.51cto.com/xuedingmaojun/3011799