第二章.HDFS
1.大数据的两个核心技术

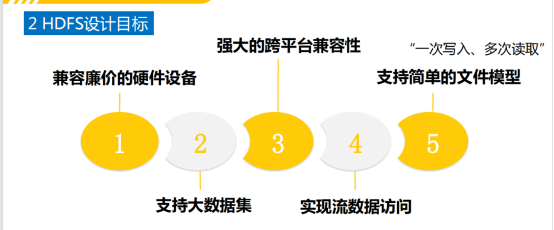
2.HDFS设计目标
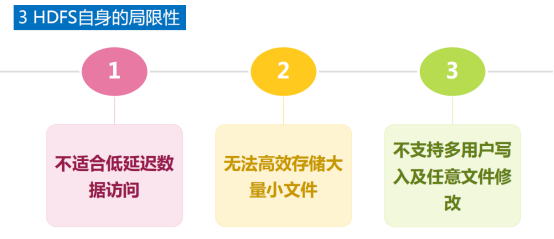
3.HDFS自身的局限性
4.HDFS采用块设计以及采用块设计的好处


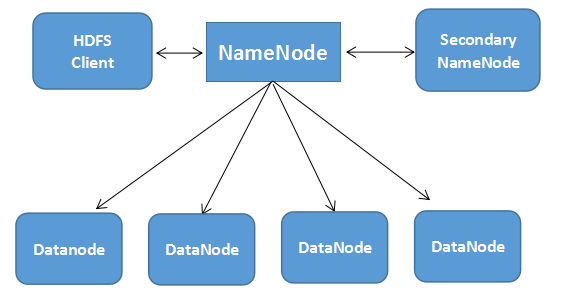
5.HDFS组成架构
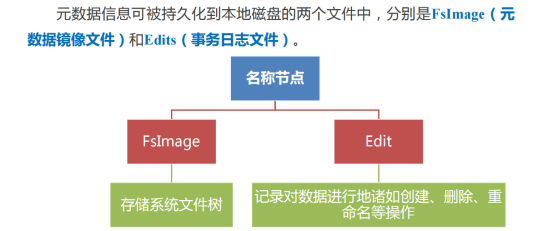
6.元数据信息被持久化到磁盘分为哪两个文件
7.第二名称节点的作用

8.名称节点,数据节点的功能
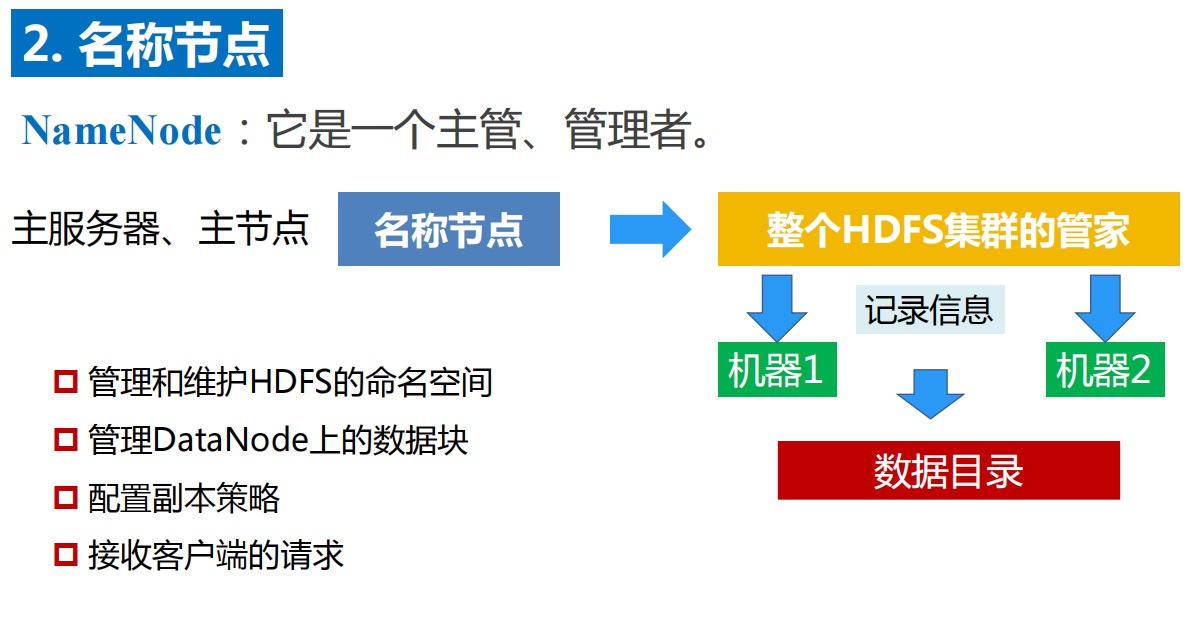
NameNode:就是 master,它是一个主管、管理者。
①管理 HDFS 的名称空间
②管理数据块(Block)映射信息
③配置副本策略
④处理客户端读写请求。
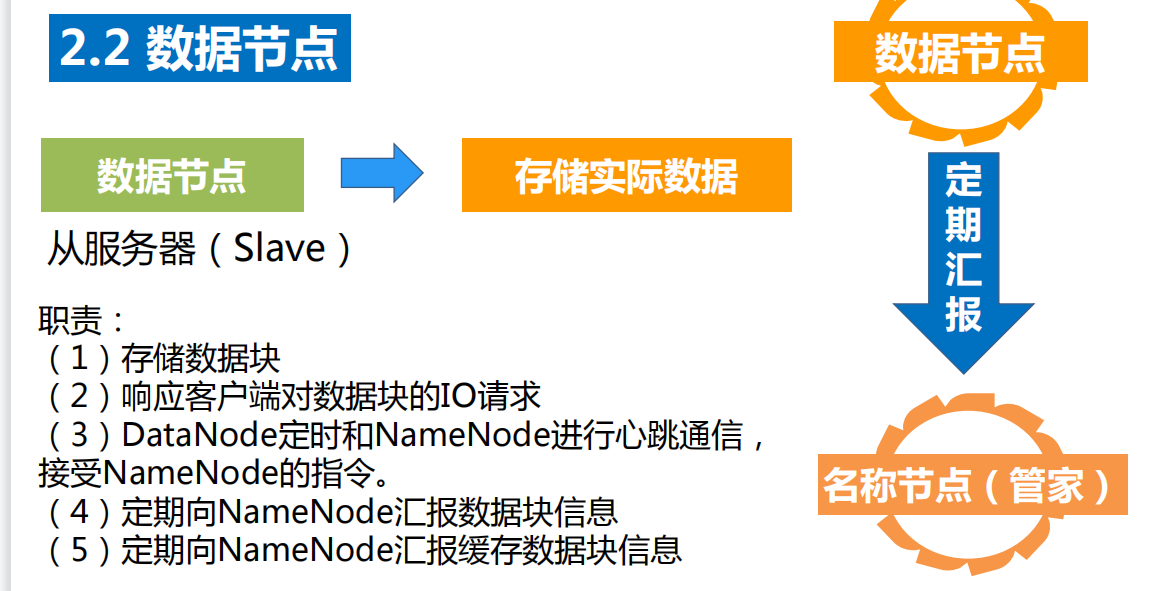
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
①存储实际的数据块。
②执行数据块的读/写操作。
9.副本机制、数据容错机制、心跳机制、采用什么通信协议
9.1副本机制
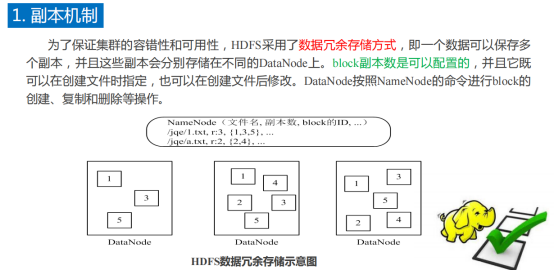
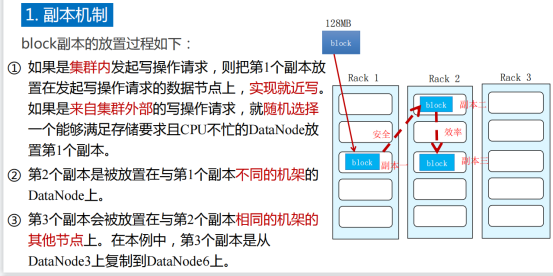

9.2数据容错机制

待补充
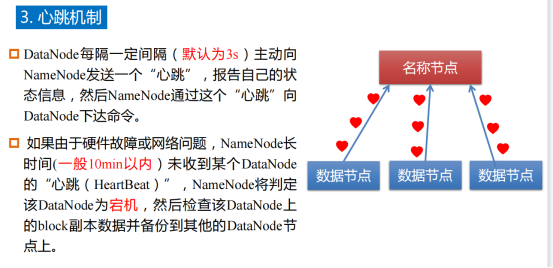
9.3心跳机制
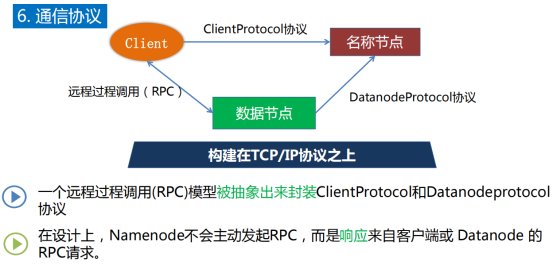
9.4通信协议
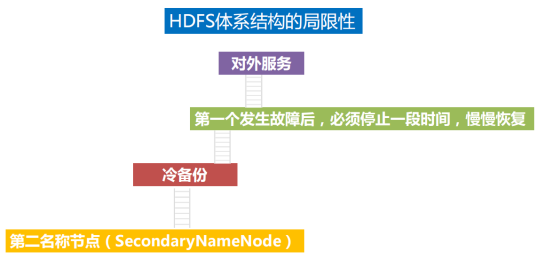
10.HDFS体系结构的局限性

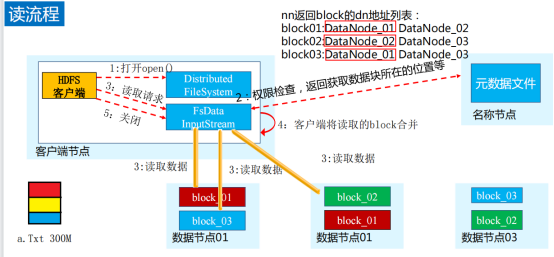
11.HDFS读写流程
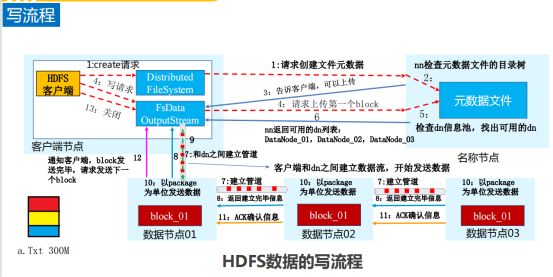
12.HDFS常用操作命令:上传,查看,下载等
待补充
Hadoop期末复习(第二章)
原文:https://www.cnblogs.com/codeforfuture/p/14942440.html