五月底发现并种草,事情实在有点多于是咕到现在

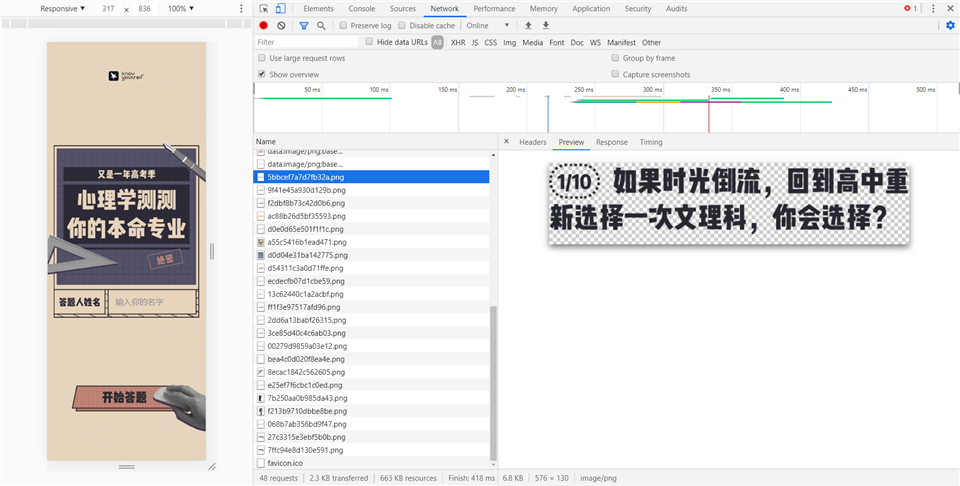
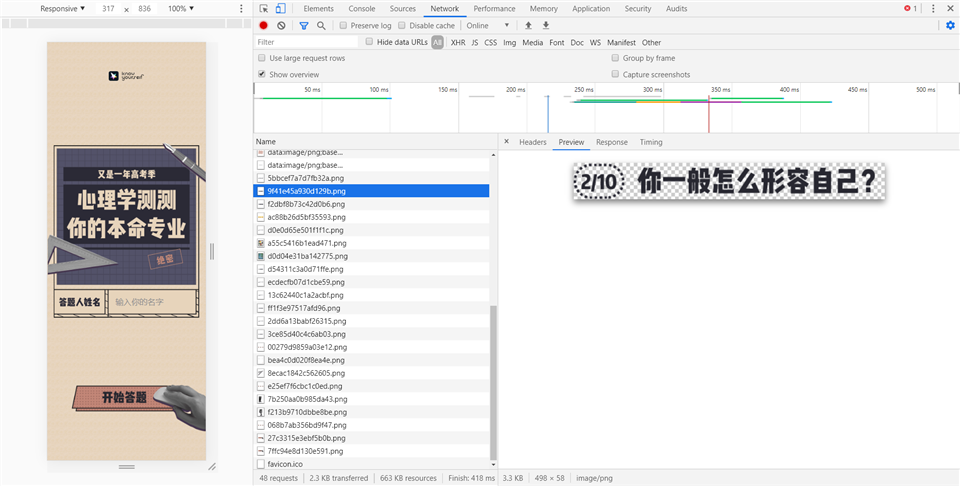
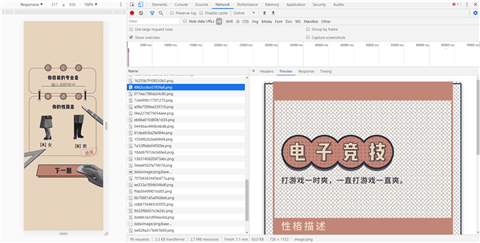
T = (t(123), [{
key: "a",
value: "文科"
}, {
key: "b",
value: "理科"
}, {
key: "c",
value: "再让我想想..."
}]),
K = (t(124), [{
key: "a",
value: "外向且理性的人"
}, {
key: "b",
value: "外向但感性的人"
}, {
key: "c",
value: "内向且感性的人"
}, {
key: "d",
value: "内向但理性的人"
}]),
var J = function(A) {
Array.prototype.shuffle || (Array.prototype.shuffle = function() {
for (var A, e, t = this.length; t; A = parseInt(Math.random() * t),
e = this[--t],
this[t] = this[A],
this[A] = e)
return this
});
for (var e = {/* 见下表1 */}, t = [], n = 0; n < A.length; n++)
for (var r = 0; r < A[n].length; r++) {
var o = A[n][r], i = e[n][o];
t = t.concat(i)
}
var a = {}, s = -1;
t.shuffle();
for (var l = 0; l < t.length; l++)
void 0 === a[t[l]] && (a[t[l]] = 0),
a[t[l]]++, -1 == s ? s = t[l] : a[t[l]] > a[s] && (s = t[l]);
return s
},
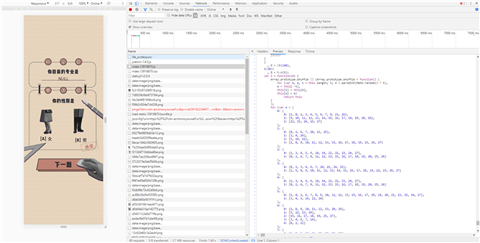
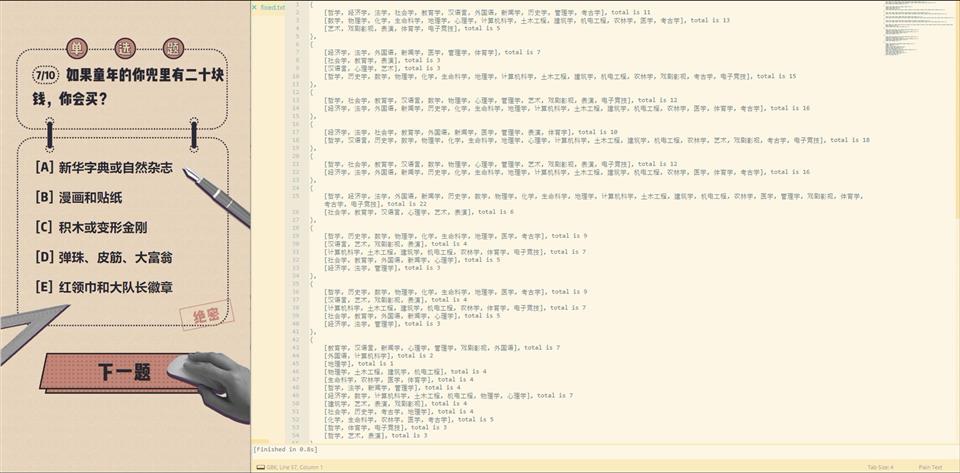
[22, 23, 24, 25, 27],选择了第一题C选项,那么最终列表会和[22, 23, 24, 25, 27]合并,即变为[22, 23, 24, 25, 27][5, 14, 22],选择了第二题C选项,那么最终列表会和[5, 14, 22]合并,即变为[22, 23, 24, 25, 27, 5, 14, 22]for (var e = {/* 见下表1 */}, t = [], n = 0; n < A.length; n++)
for (var r = 0; r < A[n].length; r++) {
var o = A[n][r], i = e[n][o];
t = t.concat(i)
}
A[n].length为1A[n].length为2或3var a = {}, s = -1;
for (var l = 0; l < t.length; l++)
void 0 === a[t[l]] && (a[t[l]] = 0),
a[t[l]]++, -1 == s ? s = t[l] : a[t[l]] > a[s] && (s = t[l]);
t.shuffle()随机打乱最终列表C C A B A A B C BC A
22, 23, 24, 25, 27
5, 14, 22
1, 3, 4, 5, 9, 10, 14, 21, 22, 23, 24, 27
1, 5, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 22, 23, 26, 27
1, 3, 4, 5, 9, 10, 14, 21, 22, 23, 24, 27
1, 0, 2, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 23, 25, 26, 27
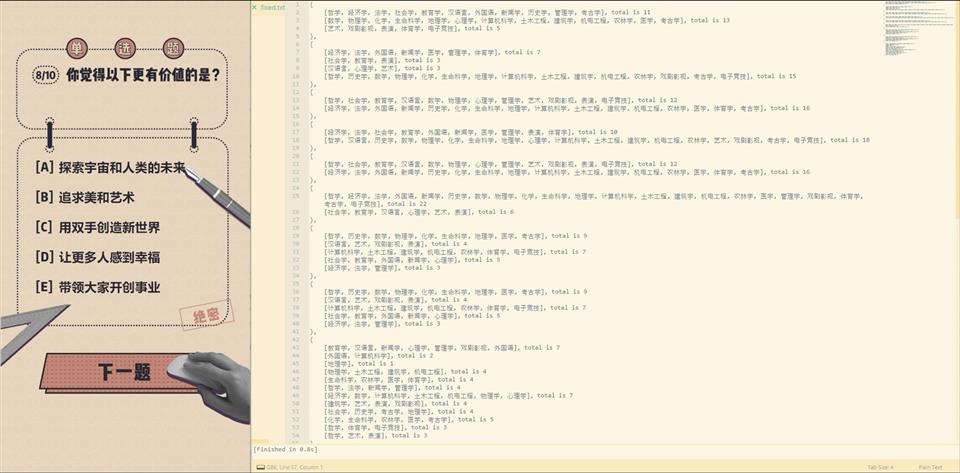
5, 22, 23, 24
15, 16, 17, 18, 19, 25, 27
6, 15, 13
(Array.prototype.shuffle = function() {
for (var A, e, t = this.length; t; A = parseInt(Math.random() * t),
e = this[--t],
this[t] = this[A],
this[A] = e)
return this
});
var A, e, t = this.length,再执行B也就是t,如果结果为真执行C也就是return this返回,等于什么都没有改变for (/* [A] */; /* [B] */; /* [C] */) {
/* [D] */
}
0: {
0: [1, 0, 2, 3, 4, 5, 6, 7, 8, 21, 26],
1: [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 26],
2: [22, 23, 24, 25, 27]
},
1: {
0: [0, 2, 6, 7, 20, 21, 25],
1: [3, 4, 24],
2: [5, 14, 22],
3: [1, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 23, 26, 27]
},
2: {
0: [1, 3, 4, 5, 9, 10, 14, 21, 22, 23, 24, 27],
1: [0, 2, 6, 7, 8, 11, 12, 13, 15, 16, 17, 18, 19, 20, 25, 26]
},
3: {
0: [0, 2, 3, 4, 6, 7, 20, 21, 24, 25],
1: [1, 5, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 22, 23, 26, 27]
},
4: {
0: [1, 3, 4, 5, 9, 10, 14, 21, 22, 23, 24, 27],
1: [0, 2, 6, 7, 8, 11, 12, 13, 15, 16, 17, 18, 19, 20, 25, 26]
},
5: {
0: [1, 0, 2, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 23, 25, 26, 27],
1: [3, 4, 5, 14, 22, 24]
},
6: {
0: [1, 8, 9, 10, 11, 12, 13, 20, 26],
1: [5, 22, 23, 24],
2: [15, 16, 17, 18, 19, 25, 27],
3: [3, 4, 6, 7, 14],
4: [0, 2, 21]
},
7: {
0: [1, 8, 9, 10, 11, 12, 13, 20, 26],
1: [5, 22, 23, 24],
2: [15, 16, 17, 18, 19, 25, 27],
3: [3, 4, 6, 7, 14],
4: [0, 2, 21]
},
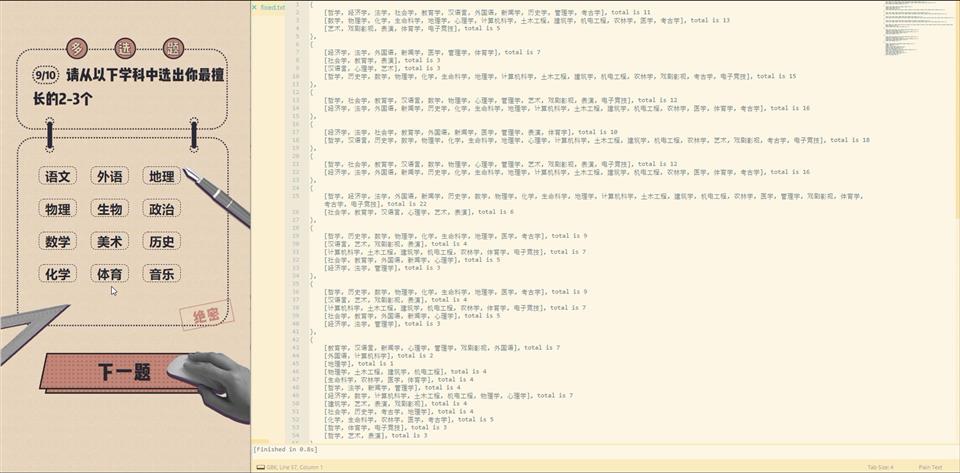
8: {
0: [4, 5, 7, 14, 21, 23, 6],
1: [6, 15],
2: [13],
3: [10, 16, 17, 18],
4: [12, 19, 20, 25],
5: [1, 2, 7, 21],
6: [0, 9, 15, 16, 18, 10, 14],
7: [17, 22, 24, 23],
8: [3, 8, 26, 13],
9: [11, 12, 19, 20, 26],
10: [25, 27],
11: [22, 24]
},
9: {
0: [],
1: [],
2: []
}
W = ["jingjixue", "zhexue", "faxue", "shehuixue", "jiaoyuxue", "hanyuyan", "waiguo", "xinwenxue", "lishixue", "shuxue", "wulixue", "huaxue", "shengmingkexue", "dilixue", "xinlixue", "jisuanjikexue", "tumugongcheng", "jianzhuxue", "jidiangongcheng", "nonglinxue", "yixue", "guanlixue", "yishu", "xijuyingshi", "biaoyan", "tiyuxue", "kaoguxue", "dianzijingji"],
const char* text[]=
{
"经济学","哲学","法学","社会学","教育学",
"汉语言","外国语","新闻学","历史学","数学",
"物理学","化学","生命科学","地理学","心理学",
"计算机科学","土木工程","建筑学","机电工程","农林学",
"医学","管理学","艺术","戏剧影视","表演",
"体育学","考古学","电子竞技"
};
(o<<3)+(o<<1)+(c^48)其实是o*10+c-‘0‘的意思,有兴趣可以自行了解位运算inline int read(char* s,int& idx)
{
int o=0; char c=s[idx++];
while (c && (c<‘0‘ || c>‘9‘)) c=s[idx++];
while (c>=‘0‘ && c<=‘9‘)
o=(o<<3)+(o<<1)+(c^48),c=s[idx++];
return c?o:-1;
}
2: [5, 14, 22],,按行读取的时候需要先跳过第一个数字,之后利用read读取即可,顺便可以统计读取到的数量inline void solve(char* s)
{
int i,idx=0,cnt=0;
printf("\t[");
read(s,idx);
if ((i=read(s,idx))!=-1)
{
printf("%s",text[i]),cnt++;
while ((i=read(s,idx))!=-1)
printf(", %s",text[i]),cnt++;
}
printf("], total is %d\n",cnt);
return;
}
int main()
{
char *s=(char*)malloc(1<<10);
freopen("tag.txt","r",stdin);
freopen("fixed.txt","w",stdout);
while (fgets(s,1<<10,stdin))
{
if (strchr(s,‘[‘)) solve(s);
else fputs(s,stdout);
}
return 0;
}
major count percent 经济学 55896 4.07% 哲学 53735 3.91% 法学 30227 2.20% 社会学 73748 5.37% 教育学 39249 2.86% 汉语言 73436 5.35% 外国语 64519 4.70% 新闻学 43233 3.15% 历史学 33503 2.44% 数学 35957 2.62% 物理学 29806 2.17% 化学 13529 0.99% 生命科学 28147 2.05% 地理学 36290 2.64% 心理学 93522 6.81% 计算机科学 59620 4.34% 土木工程 28676 2.09% 建筑学 26632 1.94% 机电工程 0 0.00% 农林学 25619 1.87% 医学 69655 5.07% 管理学 65040 4.74% 艺术 95100 6.93% 戏剧影视 57054 4.16% 表演 82970 6.04% 体育学 89138 6.49% 考古学 28874 2.10% 电子竞技 39625 2.89%
major count percent 艺术 95100 6.93% 心理学 93522 6.81% 体育学 89138 6.49% 表演 82970 6.04% 社会学 73748 5.37% 汉语言 73436 5.35% 医学 69655 5.07% 管理学 65040 4.74% 外国语 64519 4.70% 计算机科学 59620 4.34% 戏剧影视 57054 4.16% 经济学 55896 4.07% 哲学 53735 3.91% 新闻学 43233 3.15% 电子竞技 39625 2.89% 教育学 39249 2.86% 地理学 36290 2.64% 数学 35957 2.62% 历史学 33503 2.44% 法学 30227 2.20% 物理学 29806 2.17% 考古学 28874 2.10% 土木工程 28676 2.09% 生命科学 28147 2.05% 建筑学 26632 1.94% 农林学 25619 1.87% 化学 13529 0.99% 机电工程 0 0.00%
major count percent 经济学 39508 2.88% 哲学 33830 2.46% 法学 30929 2.25% 社会学 55427 4.04% 教育学 40098 2.92% 汉语言 48557 3.54% 外国语 59138 4.31% 新闻学 51414 3.75% 历史学 19030 1.39% 数学 16750 1.22% 物理学 49155 3.58% 化学 7487 0.55% 生命科学 28192 2.05% 地理学 44696 3.26% 心理学 90569 6.60% 计算机科学 41542 3.03% 土木工程 24746 1.80% 建筑学 42353 3.09% 机电工程 24616 1.79% 农林学 38035 2.77% 医学 67257 4.90% 管理学 78235 5.70% 艺术 80525 5.87% 戏剧影视 61330 4.47% 表演 104148 7.59% 体育学 84743 6.17% 考古学 67820 4.94% 电子竞技 42670 3.11%
major count percent 表演 104148 7.59% 心理学 90569 6.60% 体育学 84743 6.17% 艺术 80525 5.87% 管理学 78235 5.70% 考古学 67820 4.94% 医学 67257 4.90% 戏剧影视 61330 4.47% 外国语 59138 4.31% 社会学 55427 4.04% 新闻学 51414 3.75% 物理学 49155 3.58% 汉语言 48557 3.54% 地理学 44696 3.26% 电子竞技 42670 3.11% 建筑学 42353 3.09% 计算机科学 41542 3.03% 教育学 40098 2.92% 经济学 39508 2.88% 农林学 38035 2.77% 哲学 33830 2.46% 法学 30929 2.25% 生命科学 28192 2.05% 土木工程 24746 1.80% 机电工程 24616 1.79% 历史学 19030 1.39% 数学 16750 1.22% 化学 7487 0.55%
const char* text[]=
{
"经济学","哲学","法学","社会学","教育学",
"汉语言","外国语","新闻学","历史学","数学",
"物理学","化学","生命科学","地理学","心理学",
"计算机科学","土木工程","建筑学","机电工程","农林学",
"医学","管理学","艺术","戏剧影视","表演",
"体育学","考古学","电子竞技"
};
vector<vector<vector<int>>> reflect=
{
{
{1,0,2,3,4,5,6,7,8,21,26},
{9,10,11,12,13,14,15,16,17,18,19,20,26},
{22,23,24,25,27}
},
{
{0,2,6,7,20,21,25},
{3,4,24},
{5,14,22},
{1,8,9,10,11,12,13,15,16,17,18,19,23,26,27}
},
{
{1,3,4,5,9,10,14,21,22,23,24,27},
{0,2,6,7,8,11,12,13,15,16,17,18,19,20,25,26}
},
{
{0,2,3,4,6,7,20,21,24,25},
{1,5,8,9,10,11,12,13,14,15,16,17,18,19,22,23,26,27}
},
{
{1,3,4,5,9,10,14,21,22,23,24,27},
{0,2,6,7,8,11,12,13,15,16,17,18,19,20,25,26}
},
{
{1,0,2,6,7,8,9,10,11,12,13,15,16,17,18,19,20,21,23,25,26,27},
{3,4,5,14,22,24}
},
{
{1,8,9,10,11,12,13,20,26},
{5,22,23,24},
{15,16,17,18,19,25,27},
{3,4,6,7,14},
{0,2,21}
},
{
{1,8,9,10,11,12,13,20,26},
{5,22,23,24},
{15,16,17,18,19,25,27},
{3,4,6,7,14},
{0,2,21}
},
{
{4,5,7,14,21,23,6},
{6,15},
{13},
{10,16,17,18},
{12,19,20,25},
{1,2,7,21},
{0,9,15,16,18,10,14},
{17,22,24,23},
{3,8,26,13},
{11,12,19,20,26},
{25,27},
{22,24}
}
};
class Ans
{
public:
static int total;
static int summary[28];
int cnt,last[3],normal[8];
inline void pushUp()
{
vector<int> temp;
if (++total%50000==0) printf("%07d searched\n",total);
for (int i=0;i<(int)(sizeof(normal)/sizeof(*normal));i++)
for (vector<int>::iterator it=reflect[i][normal[i]].begin();
it!=reflect[i][normal[i]].end();it++)
temp.push_back(*it);
for (int i=0;i<cnt;i++)
for (vector<int>::iterator it=reflect[reflect.size()-1][last[i]].begin();
it!=reflect[reflect.size()-1][last[i]].end();it++)
temp.push_back(*it);
if (SHUFFLE) shuffle(temp.begin(),temp.end(),generator);
int out=-1,vis[28]={0};
for (int i=0;i<(int)temp.size();i++)
{
vis[temp[i]]++;
if (out==-1) out=temp[i];
else if (vis[temp[i]]>vis[out]) out=temp[i];
}
summary[out]++;
return;
}
};
int Ans::total=0;
int Ans::summary[28]={0};
void dfs(int cur,int top,Ans* ans)
{
if (cur==top)
{
int range=reflect[reflect.size()-1].size();
ans->cnt=2;
for (int i=0;i<range;i++)
for (int j=i+1;j<range;j++)
{
ans->last[0]=i;
ans->last[1]=j;
ans->pushUp();
}
ans->cnt=3;
for (int i=0;i<range;i++)
for (int j=i+1;j<range;j++)
for (int k=j+1;k<range;k++)
{
ans->last[0]=i;
ans->last[1]=j;
ans->last[2]=k;
ans->pushUp();
}
return;
}
for (int i=0;i<(int)reflect[cur].size();i++)
{
ans->normal[cur]=i;
dfs(cur+1,top,ans);
}
return;
}
class Node
{
public:
int idx,val;
double percent;
inline Node(int idx,int val,int total)
{
this->idx=idx,this->val=val;
percent=1.0*val/total*100;
return;
}
inline void print() const
{
printf("major = %-10s | count = %06d | percent = %5.2lf%%\n",
text[idx],val,percent);
return;
}
inline void toMarkDown() const
{
printf("| %s | %d | %5.2lf%% |\n",
text[idx],val,percent);
return;
}
inline bool operator>(Node& rhs) const
{
return this->val<rhs.val;
}
inline bool operator<(Node& rhs) const
{
return this->val>rhs.val;
}
};
int main()
{
Ans ans;
puts("----- search started -----\n");
dfs(0,sizeof(ans.normal)/sizeof(*ans.normal),&ans);
printf("\n----- search finished, total = %d, analysing -----\n\n",Ans::total);
vector<Node> analyse;
for (int i=0;i<(int)(sizeof(Ans::summary)/sizeof(*Ans::summary));i++)
{
printf("%02d / %d done\n",i,(int)(sizeof(Ans::summary)/sizeof(*Ans::summary)));
Node node(i,Ans::summary[i],Ans::total);
analyse.push_back(node);
}
if (MARKDOWN) puts("| major | count | percent |\n| :---: | :---: | :---: |");
else puts("\n----- result sort by major id -----\n");
for (vector<Node>::iterator it=analyse.begin();it!=analyse.end();it++)
if (MARKDOWN) it->toMarkDown();
else it->print();
sort(analyse.begin(),analyse.end());
if (MARKDOWN) puts("| major | count | percent |\n| :---: | :---: | :---: |");
else puts("\n----- result sort by percent -----\n");
for (vector<Node>::iterator it=analyse.begin();it!=analyse.end();it++)
if (MARKDOWN) it->toMarkDown();
else it->print();
return 0;
}
#pragma GCC optimize(2)
#pragma GCC optimize(3,"Ofast","inline")
原文:https://www.cnblogs.com/Chenrt/p/14912590.html