a. 其实就是本地的reducer,在本地先聚合一次
b. 可以减少Map Tasks输出的数据量以及数据网络的传输量
a. 适用于求和、次数等的加载
b. 求平均数等的计算并不合适
a. 决定MapTask输出的数据交由哪个ReduceTask处理
b. 默认:计算分发的key的hash值对Reduce Task的个数取模决定有哪个处理
a. 在进行WordCount的时候,我们可以通过测试代码,计算一下每个单词的Hash值是多少,然后再观察值最终是去到了哪个节点。
b. 如果我们是设置成了2个Reduce,则% 2,测试代码如下:
public class HashCodeTest {
public static void main(String[] args) {
System.out.println("an".hashCode() % 2);
System.out.println("name".hashCode() % 2);
System.out.println("you".hashCode() % 2);
System.out.println("are".hashCode() % 2);
System.out.println("example".hashCode() % 2);
System.out.println("friend".hashCode() % 2);
System.out.println("how".hashCode() % 2);
System.out.println("is".hashCode() % 2);
System.out.println("my".hashCode() % 2);
System.out.println("this".hashCode() % 2);
System.out.println("twq".hashCode() % 2);
System.out.println("what".hashCode() % 2);
}
}
a. 逻辑上与reduce是一样的,因为其实就是本地聚合,在mian方法里添加此句即可:job.setCombinerClass(MyReducer.class);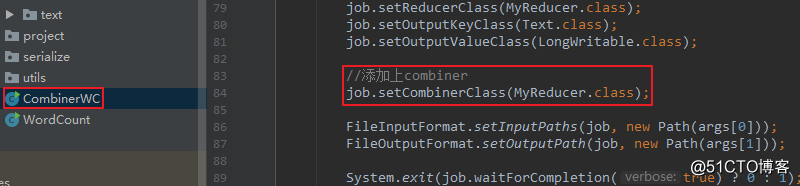
b. 打包执行与之前的类似,可以在执行界面上可看到字眼: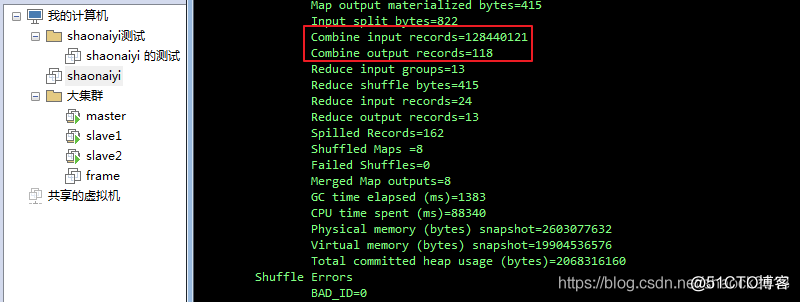
a. 准备统计的数据:
student 1500
teacher 200
student 2000
teacher 300
student 2000
teacher 300
doctor 100
doctor 200
artist 55
b. 修改MyMapper类里面的map方法代码:
for(String word : words) {
context.write(new Text(word), one);
}
修改成:context.write(new Text(words[0]), new LongWritable(Long.parseLong(words[1])));
c. 添加一个Partitioner类:
public static class MyPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
if(key.toString().equals("student")) {
return 0;
}
if(key.toString().equals("teacher")) {
return 1;
}
if(key.toString().equals("doctor")) {
return 2;
}
return 3;
}
}
d. 在main方法里添加上自定义的Partitioner类以及Reducer的个数:
//设置job的partition
job.setPartitionerClass(MyPartitioner.class);
//设置4个reducer
job.setNumReduceTasks(4);
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
复制粘贴玩转大数据系列专栏已经更新完成,请跳转学习!
MapReduce编程例子之Combiner与Partitioner
原文:https://blog.51cto.com/u_12564104/2894168