pytorch保存模型权重非常方便
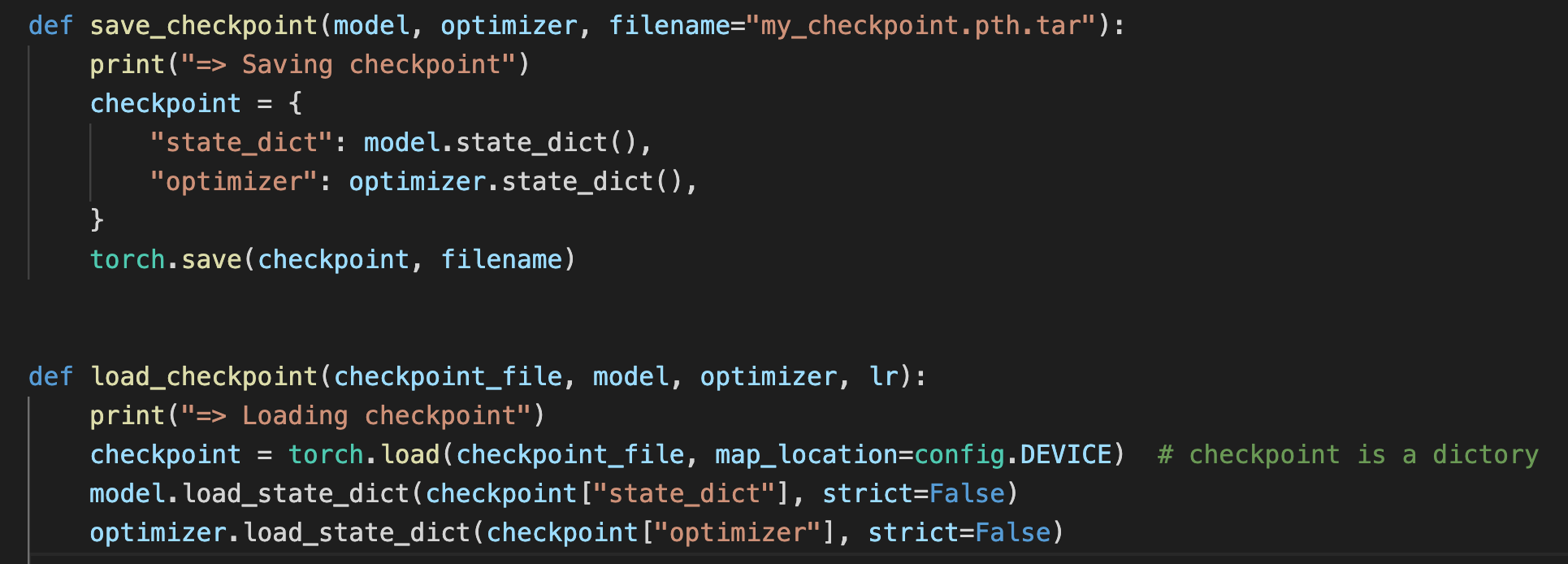
保存模型可以分为两种
一种是保存整个网络(网络结构+权重参数)
torch.save(model, ‘net.pth.tar‘)
一种是只保存模型的权重参数(速度快,内存占用少)
torch.save(model.state_dict(), ‘net.pth.tar‘)
标准的加载还可以做一些设置
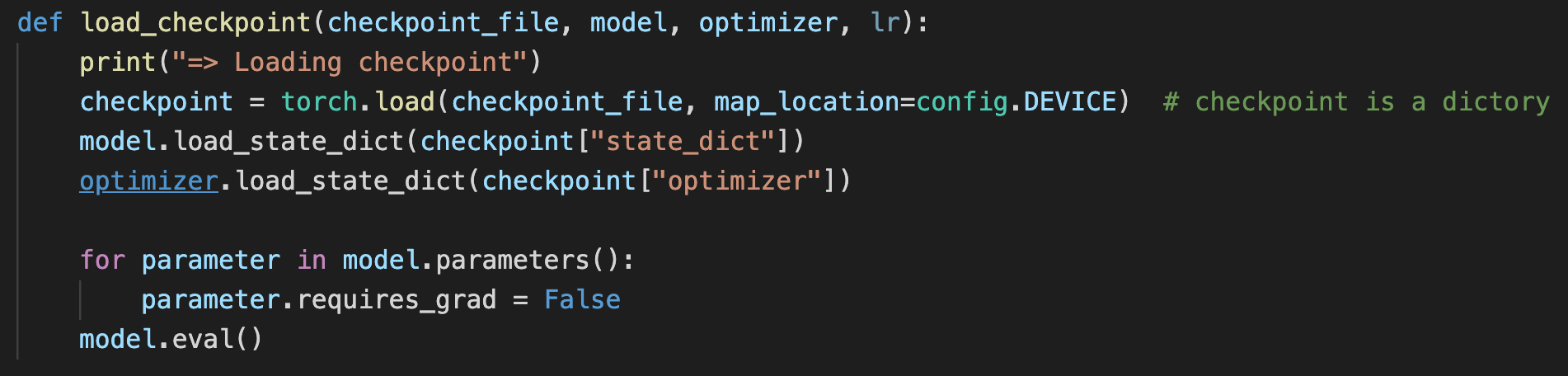
如果加载模型只是为了进行推理测试,则将每一层的 requires_grad 置为 False,即固定这些权重参数;还需要调用 model.eval() 将模型置为测试模式,主要是将 dropout 和 batch normalization 层进行固定,否则模型的预测结果每次都会不同。
如果希望继续训练,则调用 model.train(),以确保网络模型处于训练模式。
然后,想使用预训练权重有非常严格的要求,要求每一层一模一样,命名都要一样(不然dict的key就不一样了
如果两个模型实际是一样,既然是字典,可不可以手动赋值呢?
比如,我把cnn命名成conv了,导致load失败,因此我们来手动赋值

虽然load成功了,但是实际效果有点问题,直接用于生成,得到的图像颜色不对。
按道理两种方法的权重应该是一模一样啊,
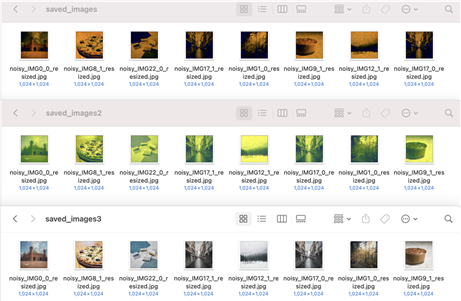
前两个是手动赋值,颜色都有偏差,第三个直接load的正常。。。
难道model.state_dict() 没有包含所有的权重信息?
其实还有一个简便方法:使用strict=False 参数
model.load_state_dict(checkpoint["state_dict"], strict=False) optimizer.load_state_dict(checkpoint["optimizer"])
奇怪的是,model的load_state_dict有strict参数,optimizer没有
参考链接:https://zhuanlan.zhihu.com/p/73893187
原文:https://www.cnblogs.com/lfri/p/14866849.html