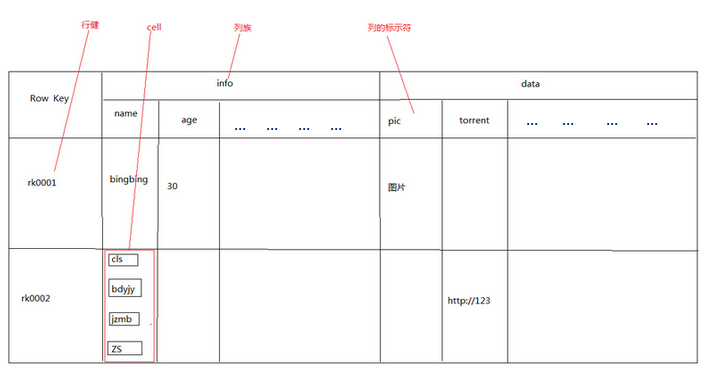
主键是用来检索记录的主键,访问 HBase Table 中的行,只有三种方式:
通过单个 row key 访问
通过 row key 的 range
全表扫描
列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型。
HBase 中通过 row 和 columns 确定的一个存储单元,称为 cell。每个 cell 都保存着同一份数据的多个版本。版本通过时间戳来索引。
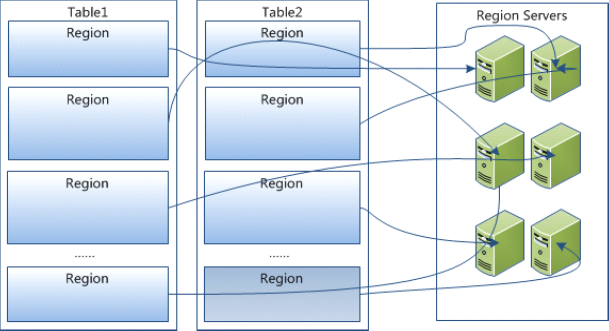
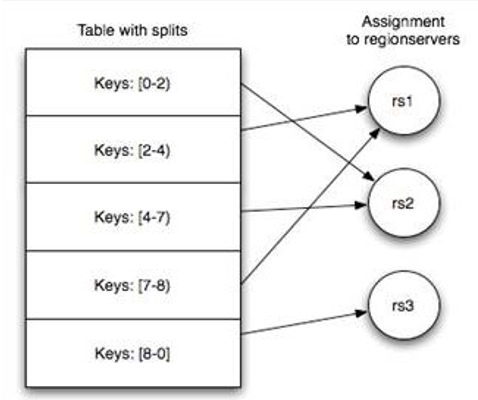
Table 在行的方向上分割为多个 HRegion,一个 region 由 [startkey,endkey) 表示,每个 HRegion 分散在不同的 RegionServer 中 。
参数:hbase.hregion.max.filesize
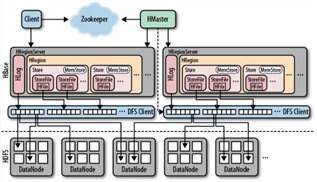
可以看出,Client 访问 HBase 上数据的过程并不需要 Master 参与,寻址访问先 Zookeeper 再 Regionserver,数据读写访问 RegionServer。
HRegion Server 主要负责响应用户I/O请求,向 HDFS 文件系统中读写数据,是 HBase 中最核心的模块。
bin 目录进入 HBase 命令行:
./hbase shell
list
create ‘user‘, ‘info1‘, ‘data1‘ create ‘user‘, {NAME => ‘info‘, VERSIONS => ‘3‘}
put ‘user‘, ‘rk0001‘, ‘info:name‘, ‘zhangsan‘
put ‘user‘, ‘rk0001‘, ‘info:gender‘, ‘female‘
put ‘user‘, ‘rk0001‘, ‘info:age‘, 20
put ‘user‘, ‘rk0001‘, ‘data:pic‘, ‘picture‘
get ‘user‘, ‘rk0001‘
get ‘user‘, ‘rk0001‘, ‘info‘
get ‘user‘, ‘rk0001‘, ‘info:name‘, ‘info:age‘
get ‘user‘, ‘rk0001‘, ‘info‘, ‘data‘ get ‘user‘, ‘rk0001‘, {COLUMN => [‘info‘, ‘data‘]} get ‘user‘, ‘rk0001‘, {COLUMN => [‘info:name‘, ‘data:pic‘]}
get ‘people‘, ‘rk0002‘, {COLUMN => ‘info‘, VERSIONS => 2} get ‘user‘, ‘rk0001‘, {COLUMN => ‘info:name‘, VERSIONS => 5} get ‘user‘, ‘rk0001‘, {COLUMN => ‘info:name‘, VERSIONS => 5, TIMERANGE => [1392368783980, 1392380169184]}
get ‘people‘, ‘rk0001‘, {FILTER => "ValueFilter(=, ‘binary:图片‘)"}
get ‘people‘, ‘rk0001‘, {FILTER => "(QualifierFilter(=,‘substring:a‘))"}
scan ‘user‘
scan ‘people‘, {COLUMNS => ‘info‘} scan ‘user‘, {COLUMNS => ‘info‘, RAW => true, VERSIONS => 5} scan ‘persion‘, {COLUMNS => ‘info‘, RAW => true, VERSIONS => 3}
scan ‘user‘, {COLUMNS => [‘info‘, ‘data‘]} scan ‘user‘, {COLUMNS => [‘info:name‘, ‘data:pic‘]}
scan ‘user‘, {COLUMNS => ‘info:name‘}
scan ‘user‘, {COLUMNS => ‘info:name‘, VERSIONS => 5}
scan ‘people‘, {COLUMNS => [‘info‘, ‘data‘], FILTER => "(QualifierFilter(=,‘substring:a‘))"}
scan ‘people‘, {COLUMNS => ‘info‘, STARTROW => ‘rk0001‘, ENDROW => ‘rk0003‘}
scan ‘user‘,{FILTER=>"PrefixFilter(‘rk‘)"}
scan ‘user‘, {TIMERANGE => [1392368783980, 1392380169184]}
delete ‘people‘, ‘rk0001‘, ‘info:name‘
delete ‘user‘, ‘rk0001‘, ‘info:name‘, 1392383705316
truncate ‘people‘
添加两个列族 f1 和 f2:
alter ‘people‘, NAME => ‘f1‘ alter ‘user‘, NAME => ‘f2‘
删除一个列族:
alter ‘user‘, NAME => ‘f1‘, METHOD => ‘delete‘ -- 或 alter ‘user‘, ‘delete‘ => ‘f1‘
添加列族 f1 的同时删除列族 f2:
alter ‘user‘, {NAME => ‘f1‘}, {NAME => ‘f2‘, METHOD => ‘delete‘}
将 user 表的 f1 列族版本号改为 5:
alter ‘people‘, NAME => ‘info‘, VERSIONS => 5
删除表:
drop ‘user‘
修改表名:
get ‘person‘, ‘rk0001‘, {FILTER => "ValueFilter(=, ‘binary:中国‘)"} get ‘person‘, ‘rk0001‘, {FILTER => "(QualifierFilter(=,‘substring:a‘))"} scan ‘person‘, {COLUMNS => ‘info:name‘} scan ‘person‘, {COLUMNS => [‘info‘, ‘data‘], FILTER => "(QualifierFilter(=,‘substring:a‘))"} scan ‘person‘, {COLUMNS => ‘info‘, STARTROW => ‘rk0001‘, ENDROW => ‘rk0003‘} scan ‘person‘, {COLUMNS => ‘info‘, STARTROW => ‘20140201‘, ENDROW => ‘20140301‘} scan ‘person‘, {COLUMNS => ‘info:name‘, TIMERANGE => [1395978233636, 1395987769587]} delete ‘person‘, ‘rk0001‘, ‘info:name‘ alter ‘person‘, NAME => ‘ffff‘ alter ‘person‘, NAME => ‘info‘, VERSIONS => 10
原文:https://www.cnblogs.com/juno3550/p/14826346.html