1. Hadoop 简介
目前主流的大数据框架
大数据框架能处理传统计算技术所无法处理的大型数据集。它不是单一的技术或工具,而是涉及的业务和技术的许多领域。
目前主流的三大分布式计算系统分别为 Hadoop、Spark 和 Strom:
- Hadoop 是当前大数据管理标准之一,运用在当前很多商业应用系统。可以轻松地集成结构化、半结构化甚至非结构化数据集。
- Spark 采用了内存计算。从多迭代批处理出发,允许将数据载入内存作反复查询,此外还融合数据仓库,流处理和图形计算等多种计算范式。Spark 构建在 HDFS 上,能与 Hadoop 很好地结合。
- Storm 用于处理高速、大型数据流的分布式实时计算系统。为 Hadoop 添加了可靠的实时数据处理功能。
什么是 Hadoop?
The Apache? Hadoop? project develops open-source software for reliable, scalable, distributed computing.
Hadoop 被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。
Hadoop 使用 Java 编写,允许分布在集群,是专为从单一服务器到上千台机器的扩展,每个机器都可以提供本地计算和存储,即 Hadoop 就是一个分布式计算的解决方案。
Hadoop 可以编写和运行分布式应用来处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
Hadoop = HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理)。Hadoop 的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为 key/value(key/value 是基本数据单元)。用函数式编程(Mapreduce)代替 SQL。SQL 是查询语句,而 Mapreduce 则是使用脚本和代码。不过对于习惯使用 SQL 的,Hadoop 也有开源工具 Hive 代替。
解决的核心问题
- 海量数据的存储(HDFS —— Hadoop Distributed File System)
- 海量数据的分析(MapReduce —— 并行计算模型/框架)
- 资源管理调度系统(YARN —— Yet Another Resource Negotiator)
Hadoop 特点
- 扩容能力(Scalable):能可靠地存储和处理千兆字节(PB)数据。
- 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,Hadoop 可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。
- 可靠性(Reliable):Hadoop 能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
使用场景
- 大数据量存储:分布式存储(如各种云盘)。
- 日志处理:Hadoop 擅长这个。
- 海量计算:并行计算。
- ETL:数据抽取到 Oracle、Mysql、DB2、Mongdb 及其他主流数据库。
- 使用 HBase 做数据分析:用扩展性应对大量读写操作(如 Facebook 构建了基于 HBase 的实时数据分析系统)。
- 机器学习:比如 Apache Mahout 项目(常见领域:协作筛选、集群、归类)。
- 搜索引擎:Hadoop + Lucene 实现。
- 数据挖掘:目前比较流行的广告推荐。
- 大量地从文件中顺序读。HDFS 对顺序读进行了优化,代价是对于随机的访问负载较高。
- 用户行为特征建模。
- 个性化广告推荐。
案例:
假如我有一个 100M 的数据库备份的 sql 文件,我现在想在不导入到数据库的情况下直接用 grep 操作通过正则过滤出我想要的内容。例如:某个表中含有相同关键字的记录。有几种方式,一种是直接用 linux 的命令 grep;还有一种就是通过编程来读取文件,然后对每行数据进行正则匹配得到结果好了现在是 100M 的数据库备份。
上述两种方法都可以轻松应对。那么如果是 1G,1T 甚至 1PB 的数据呢,上面 2 种方法还能行得通吗?答案是不能。毕竟单台服务器的性能总有其上限。那么对于这种超大数据文件怎么得到我们想要的结果呢?
解决方案就是分布式计算,分布式计算的核心就在于利用分布式算法把运行在单台机器上的程序扩展到多台机器上并行运行,从而使数据处理能力成倍增加。但是这种分布式计算一般对编程人员要求很高,而且对服务器也有要求。导致了成本变得非常高。
Hadoop 就是为了解决这个问题诞生的。Hadoop 可以很轻易的把很多 linux 的廉价 PC 组成分布式结点,然后编程人员也不需要知道分布式算法之类,只需要根据 mapreduce 的规则定义好接口方法,剩下的就交给 Haddop。它会自动把相关的计算分布到各个结点上去,然后得出结果。
例如上述的例子, Hadoop 要做的事:
- 首先把 1PB 的数据文件导入到 HDFS 中;
- 然后编程人员定义好 map 和 reduce,也就是把文件的行定义为 key,每行的内容定义为 value,然后进行正则匹配,匹配成功则把结果通过 reduce 聚合起来返回;
- Hadoop 会把这个程序分布到 N 个结点去并行的操作。
那么原本可能需要计算好几天,在有了足够多的结点之后就可以把时间缩小到几小时之内。
Hadoop 架构
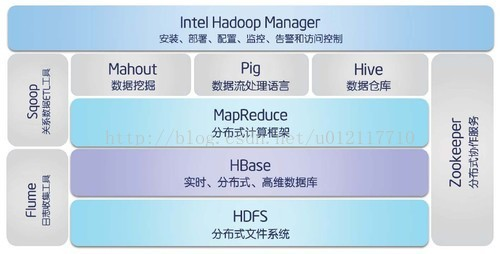
Hadoop(2.x)架构:
- 底层:存储层。文件系统 HDFS,NoSQL Hbase 等。
- 中间层:资源及数据管理层。YARN 以及 Sentry 等。
- 上层:MapReduce、Impala、Spark 等计算引擎。
- 顶层:基于 MapReduce、Spark 等计算引擎的高级封装及工具,如 Hive、Pig、Mahout。
Hadoop 生态
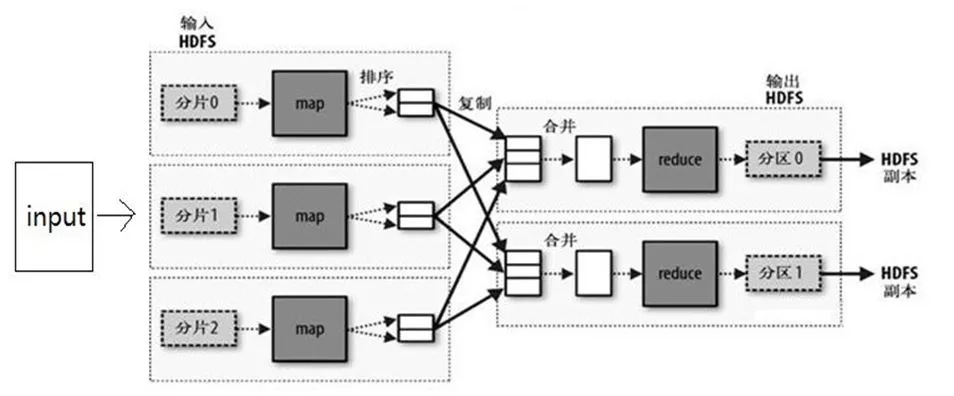
2. Mapreduce
MapReduce 是一个编程模型,封装了并行计算、容错、数据分布、负载均衡等细节问题,其原理是分治算法(Divide-and-Conquer)。
分治算法的基本原理:将一个复杂的问题,分成若干个简单的子问题进行解决。然后对子问题的结果进行合并,得到原有问题的解。
- 将一个大任务拆分成小的子任务,并且完成子任务的计算,这个过程叫做 Map。
- 将各子任务得到的中间结果合并成最终结果,这个过程叫做 Reduce。
于是就有了分布式计算的方法:将大量的数据分成小份,每台机器处理一小份,多台机器并行处理,很快就能算完。
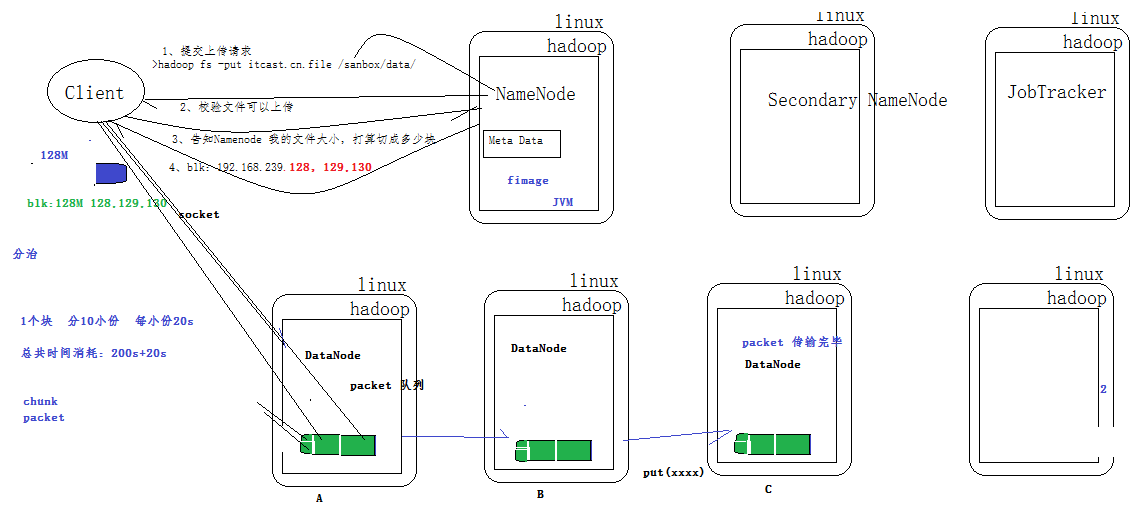
3. HDFS
HDFS(Hadoop File System)是 Hadoop 的分布式文件存储系统。
HDFS 将大文件分解为多个 Block,每个 Block 保存多个副本,并提供容错机制,副本丢失或者宕机时自动恢复。
每个 Block 默认保存 3 个副本,64M 为 1 个 Block,并将 Block 按照 key-value 映射到内存当中。
HDFS 的架构:主从结构
-
主节点只有一个:NameNode
-
从节点有很多个:DataNode
NameNode 负责:
- 保存元数据信息:如文件属性,服务器,文件怎么存。
- 接收用户操作请求。
- 维护文件系统的目录结构。
- 管理文件与 block 之间关系、block 与 datanode 之间关系。
DataNode 负责:
- 存储文件。
- 文件被分成 block 存储在磁盘上。
- 为保证数据安全,文件会有多个副本。
- 心跳检测。
4. 数据采集、存储、计算
数据采集和 DataFlow
对于数据采集主要分为三类,即结构化数据库采集、日志和文件采集、网页采集。
对于结构化数据库,采用 Sqoop 是合适的,可以实现结构化数据库中数据并行批量入库到 HDFS 存储。
对于网页采集,前端可以采用 Nutch,全文检索采用 Lucense,而实际数据存储最好是入库到 Hbase 数据库。
对于日志文件的采集,现在最常用的仍然是 Flume 或 Chukwa,但是如果对于日志文件数据需要进行各种计算处理再入库的时候,往往 Flume 并不容易处理,这也是为何可以采用 Pig 来做进一步复杂的 DataFlow 和 Process 的原因。
数据采集类似于传统的 ETL 等工作,因此传统 ETL 工具中的数据清洗、转换、调度等都是相当重要的内容。这一方面是要基于已有的工具,进行各种接口的扩展以实现对数据的处理和清洗,一方面是加强数据采集过程的调度和任务监控。
数据存储库
在这里先谈三种场景下的三种存储和应用方式,即 Hive,Impala、Hbase,其中三者都是基于底层的 HDFS 分布式文件系统。
- Hive 重点是 Sql-Batch(批处理)查询,适用于海量数据的统计类查询分析。
- Impala 重点是 Ad-Hoc(点对点)模式和交互式查询。Hive 和 Impala 都可以看作是基于 OLAP(Online analytical processing,联机分析处理)模式的。
- Hbase 重点是支撑业务的 CRUD(增删改查)操作,如各种业务操作下的处理和查询。
Hive
- Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 重点是 Sql-Batch(批处理)查询,适用于海量数据的统计类查询分析。
- Hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL 查询功能,能将 SQL 语句转变成 MapReduce 任务来执行。
- Hive 的优点是学习成本低,可以通过类似 SQL 语句实现快速 MapReduce 统计,使 MapReduce 变得更加简单,而不必开发专门的 MapReduce 应用程序。
Impala
- Impala 是 Cloudera 公司主导开发的新型查询系统,它提供 SQL 语义,能查询存储在 Hadoop 的 HDFS 和 HBase 中的 PB 级大数据。已有的 Hive 系统虽然也提供了 SQL 语义,但由于 Hive 底层执行使用的是 MapReduce 引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速,Impala 本身是基于内存的 MPP(Massively Parallel Processing,大规模并行处理)机制。
- Impala 重点是 Ad-Hoc(点对点)模式和交互式查询。Hive 和 Impala 都可以看作是基于 OLAP(Online analytical processing,联机分析处理)模式的。
HBase
- HBase 是一个分布式的、面向列的开源数据库,是 Apache 的 Hadoop 项目的子项目,该技术来源于 Fay Chang 所撰写的 Google 论文“Bigtable:一个结构化数据的分布式存储系统”。
- 就像 Bigtable 利用了 Google 文件系统(File System)所提供的分布式数据存储一样,HBase 在 Hadoop 之上提供了类似于 Bigtable 的能力。
- HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。
如何对上面三种模式提供共享一致的数据存储和管理服务,HCatalog 是基于 Apache Hadoop 之上的数据表和存储管理服务,提供统一的元数据管理。不需要知道具体的存储细节当然是最好的,但是 Hcatalog 本身也还处于完善阶段,包括和 Hive、Pig 的集成。
对于 MapReduce 和 Zookeeper 本身就已经在 Hbase 和 Hive 中使用到了。如 Hive 的 HQL 需要通过 MapReduce 解析和合并等。
实时流计算
数据的价值越来越被企业重视,被称为是 21 世纪的石油。
当存储了大规模的数据,我们要干什么呢,当然是分析数据中的价值,Hadoop 的 MapReduce 主要用于离线大数据的分析挖掘,比如电商数据的分析挖掘、社交数据的分析挖掘、企业客户关系的分析挖掘等,最终的目标就是 BI(商业智能)了,以提高企业运作效率,实现精准营销及各个垂直领域的推荐系统、发现潜在客户等等。在这个数据化时代,每件事都会留下电子档案,分析挖掘日积月累的数据档案,我们就能理解这个世界和我们自己更多。
但 MR 编写代码复杂度高,且由于磁盘 I/O,分析结果周期长,现实世界中我们对数据分析的实时性要求越来越高,基于内存计算的 Spark 来了。Hadoop+Spark 正在替代 Hadoop+MR 成为大数据领域的明星,Cloudera 正在积极推动 Spark 成为 Hadoop 的默认数据处理引擎。
同时 Twitter 也推出了 Storm 用来解决实时热点查询和排序的问题。
Hadoop 简介
原文:https://www.cnblogs.com/juno3550/p/14823160.html