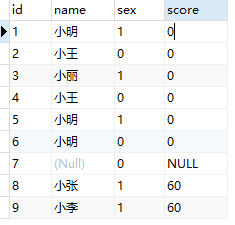
我们假设有以下一个表,表名为test
一、concat函数
功能:将多个字符串连接成一个字符串
语法:concat(str1,str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
1.1 以上面test表为例,运行以下语句,
SELECT CONCAT(id,name,score) AS info FROM test;
运行结果为,其中,因为有一行原表中score为null,所以在结果中为null,

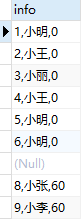
1.2 在1.1的结果中字段组合没有分隔符,我们可以加一个分隔符,比如逗号
SELECT CONCAT(id,‘,‘,name,‘,‘,score) AS info FROM test;
运行结果为,
但此方法有一个显而易见的缺点,当字段名很多,且要求每两个字段之间都要加分隔符,那语句就显得很冗长了,此时我们可以用指定参数之间的分隔符的concat_ws()函数!
二、concat_ws()函数
功能:和concat()函数一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符(concat_ws就是concat with separator的缩写) 语法:concat_ws(separator,str1,str2,...) 说明:第一个参数指定分隔符,需要注意的是分隔符不能为null,如果为null,则返回结果为null。
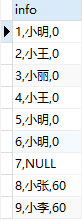
2.1 我们使用concat_ws()函数将逗号分隔符作为指定分隔符,
SELECT CONCAT_WS(‘,‘,id,name,score) AS info FROM test;
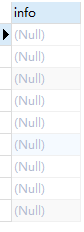
2.2 把分隔符指定为null,结果全部变成null,
SELECT CONCAT_WS(null,id,name,score) AS info FROM test;
三、group_concat函数
在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的一句,要么就包含在聚合函数中,比如
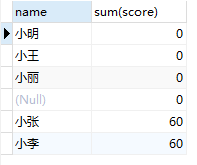
SELECT name,sum(score) FROM test GROUP BY name;
运行结果为,
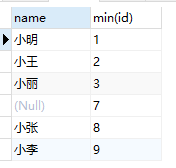
3.1 查询name相同的人中最小的id
SELECT name,min(id) FROM test GROUP BY name;
当我们要查询name相同的人的所有的id时候,可以这样,
SELECT name,id FROM test ORDER BY name;
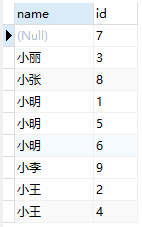
看起来不太直观,我们可以用group_concat()函数。
3.2 group_concat()函数
功能:将group by产生的同一个分组中的值连接起来,并返回一个字符串结果 语法:group_concat([distinct] 要连接字段 [order by 排序字段 asc|desc] [separator ‘分隔符‘]) 说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
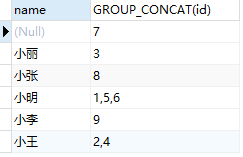
举例1,使用group_concat()和group by显示相同名字的人的id号,
SELECT name,GROUP_CONCAT(id) FROM test GROUP BY name;
举例2,将id号从大到小排序,并且用‘_‘作为分隔符,
SELECT name,GROUP_CONCAT(id ORDER BY id DESC separator ‘_‘) FROM test GROUP BY name;

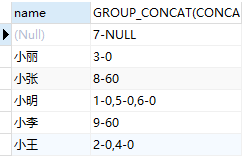
举例3,查询以name分组的所有组的id和score,
SELECT name,GROUP_CONCAT(CONCAT_WS(‘-‘,id,score) ORDER BY id) FROM test GROUP BY name;
原文:https://www.cnblogs.com/yongzhao/p/14797027.html