database:存储数据的“仓库”,他保存了一系列有组织的数据。一张张数据表table,存储在DB中;
database management system:数据库管理系统,数据库是通过DBMS创建和操作的容器,例如mysql、sqlserver、Oracle等安装的软件系统;
结构化查询语言:专门用来与数据库通信的语言;
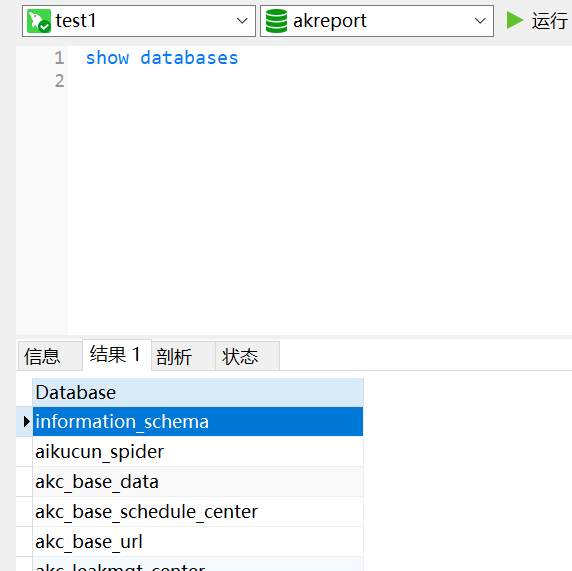
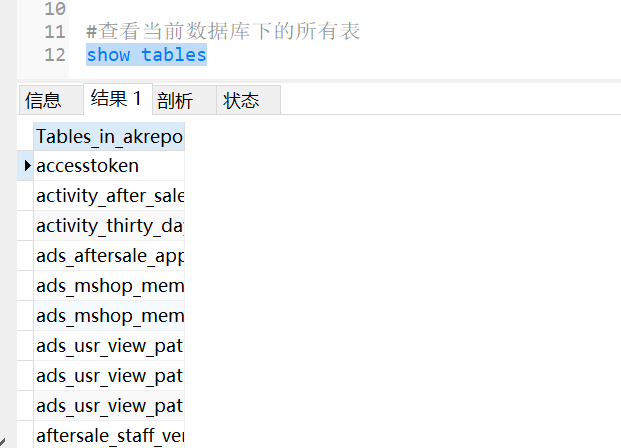
show databases
显示了test1下的所有数据库
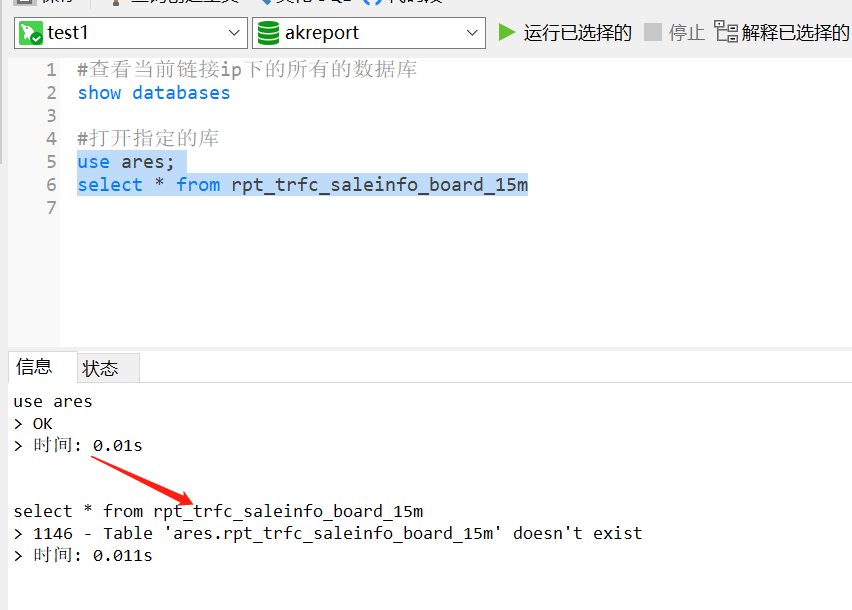
use database库名(具体的数据库名字)
则当前工作数据库直接切换到到了database下,再执行这个数据库下不存在的表,会提示doesn‘t exist
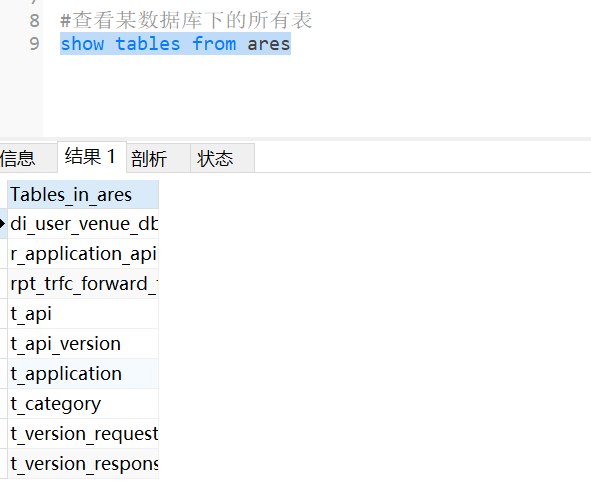
show tables from database库名
show tales
select version()
①字符编码方式是用一个或多个字节表示字符集中的一个字符
②每种字符集都有自己特有的编码方式,因此同一个字符,在不同字符集的编码方式下,会产生不同的二进制
ASCII字符集:基于罗马字母表的一套字符集,它采用1个字节的低7位表示字符,高位始终为0。
LATIN1字符集:相对于ASCII字符集做了扩展,仍然使用一个字节表示字符,但启用了高位,扩展了字符集的表示范围。
GBK字符集:支持中文,字符有一字节编码和两字节编码方式。
UTF8字符集:Unicode字符集的一种,是计算机科学领域里的一项业界标准,支持了所有国家的文字字符,utf8采用1-4个字节表示字符。
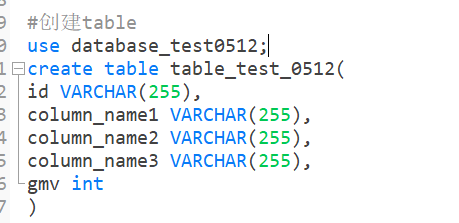
create table table_name表名(
column_name1字段名 data_type(size)字段类型及数据长度,
column_name2字段名 data_type(size)字段类型及数据长度,
column_name3字段名 data_type(size)字段类型及数据长度,
...
);
data_type数据类型:
数据类型(data_type)规定了列可容纳何种数据类型。下面的表格包含了SQL中最常用的数据类型:
字节与字符:
| 数据类型 | 描述 |
| tinyint integer(size) smallint int(size) smallint(size) tinyint(size) |
仅容纳整数。在括号内规定数字的最大位数 1.tinyint: 一个字节 取值范围 -128~127相当于java中的byte 2.smallint=integer: 两个字节 取值范围 -32768~32767相当于java中的short 3.mediumint:三个字节 4.int: 四个字节 取值范围 -2147483648~2147483647 5.bigint: 8个字节相当于java的long |
| decimal(size,d) numeric(size,d) |
容纳带有小数的数字。 "size" 规定数字的最大位数。"d" 规定小数点右侧的最大位数。 |
| char(size) |
mysql5.0版本以上,varchar(20),指的是20字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放20个,最大大小是65532字节 即65532/3个汉字 |
| varchar(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 注释:如果值的长度大于 255,则被转换为 TEXT 类型。 text:存放最大长度为 65,535 个字节的字符串。 |
| date(yyyymmdd) | 容纳日期。 |
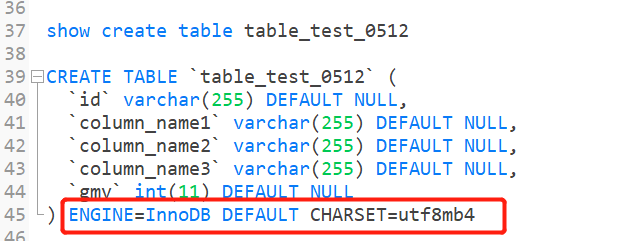
create table table_name表名(
column_name1字段名 data_type(size)字段类型及数据长度 character set utf8 not null,
column_name2字段名 data_type(size)字段类型及数据长度character set utf8 not null,
column_name3字段名 data_type(size)字段类型及数据长度character set utf8 not null,
...
);
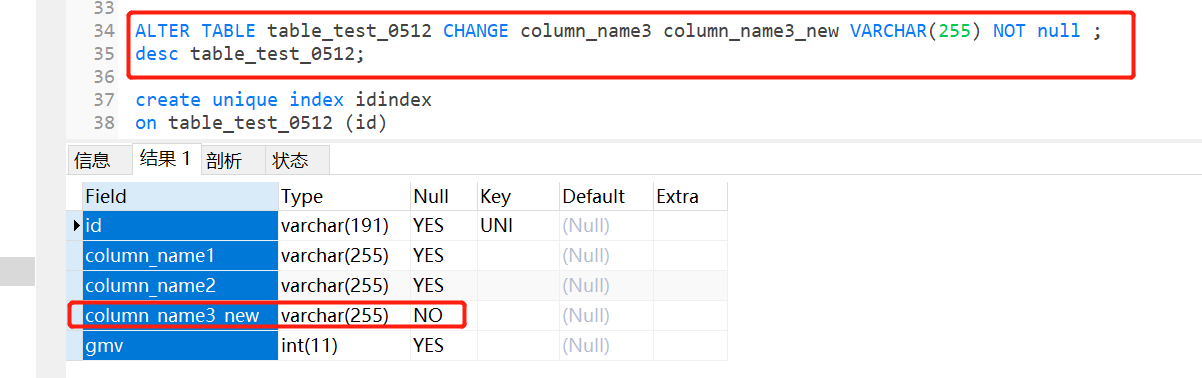
ALTER TABLE table_test_0512 CHANGE column_name3 column_name3_new VARCHAR(255) NOT null ;
ALTER TABLE <表名> rename to 新表名;
ALTER TABLE <表名> add/modify COLUMN 字段名 数据类型(vachar/int/double) ;
ALTER TABLE <表名> drop COLUMN 字段名;
ALTER TABLE <表名> change COLUMN 字段名 旧字段名 新字段名;
如果存在再删除,但是if exists不适用于列
DROP table IF EXISTS 表名
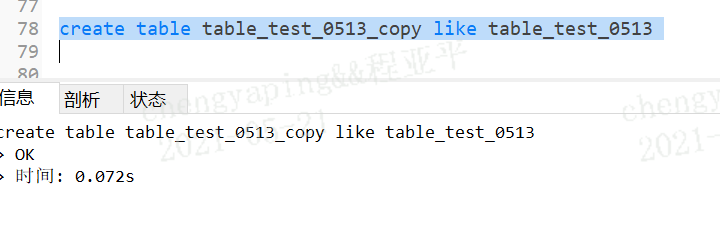
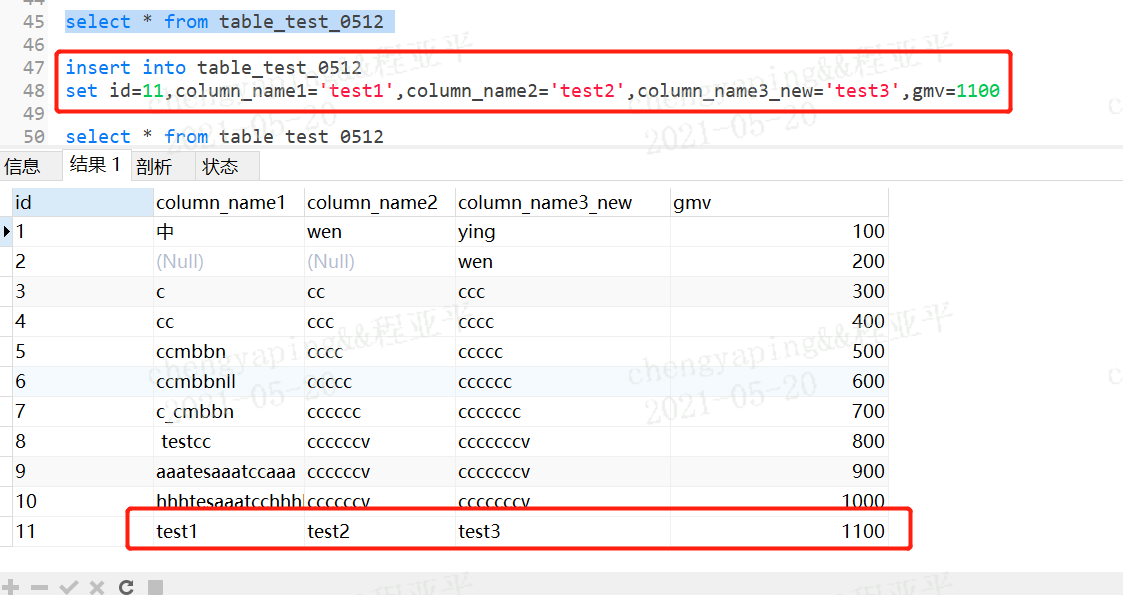
create table table_test_0513_copy like table_test_0513
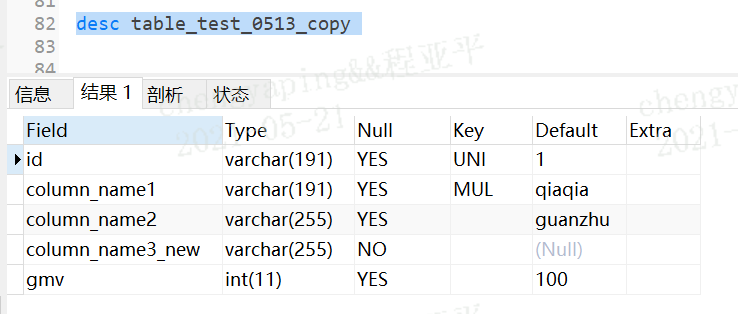
insert into table_test_0512_copy--要求表必须存在
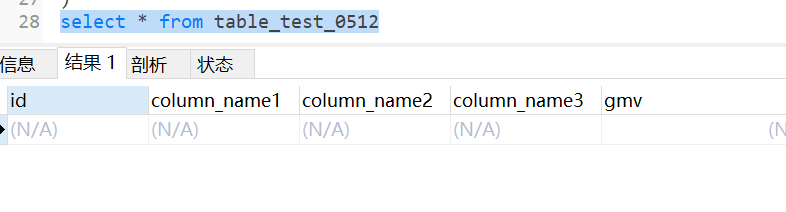
select * from table_test_0512
2.6 创建数据库create database database库名
create database books if not exists books;
数据层面的修改是update
库表层的修改:
alter/rename
rename database 库名 to 新库名;
alter database 库名 character set 字符集类型(utf8/gbk);
drop database 库名;
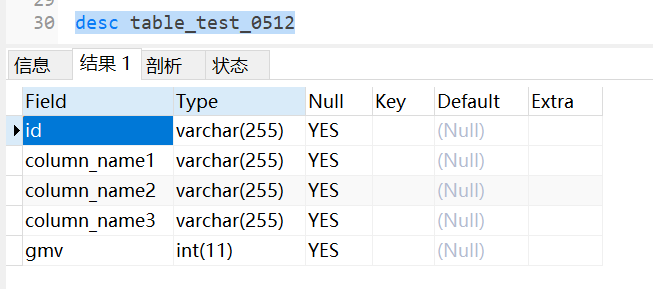
desc tablename表名
int最大长度是11位。即11为字符长度,如果在建表时不指定字段int类型的长度时,系统则默认生成长度为11的字段。11也是int类型的最大长度,其中第一位表示符号+或者-,后面十位表示数字。
从 -2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647) 的整型数据(所有数字)。存储大小为 4 个字节。
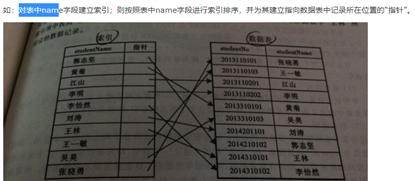
索引被创建于已有的表中,它可使对行的定位更快速更有效。可以在表格的一个或者多个列上创建索引,每个索引都会被起个名字。用户无法看到索引,它们只能被用来加速查询。
注释:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常用于搜索的列上面创建索引。
索引是查询优化最主要的方式;
查询方式:
一种是:全表扫描,即从第一行,一行行查,直到查到对应的那行才停止;
一种是:利用数据表上建立的索引进行扫描。
索引会单独形成一张数据表,里面存储了索引字段名、value值、指针;
这个指针是每一行value值在库表中对应的行地址,只要通过查询索引表知道这行数据的指针,mysql就可以直接到库表中定位到该行并返回该行所有数据;
Mysql索引根据用途分为:
1.普通索引:列值可以取空值或重复值。创建使用关键字INDEX或KEY;
2.唯一索引:列值不能重复;即索引列值必须是唯一的,但可以是空值;创建使用关键字UNIQUE;
3.主键索引:主键索引是系统自动创建的主键索引,并且是唯一的。与唯一索引区别是;列值不能为空;
4.聚簇索引:就是数据存储的物理存储顺序,非聚簇索引就是索引顺序与数据的物理顺序无关。一个表只能有一个聚簇索引。目前只有InoDB和solidDB支持。
5.全文索引:只能创建在varchar或text的列上;建立全文索引能够在全文索引的列上进行查找。
(1)单列索引:就是一个索引只包含表中的一个列;比创建一个学号ID的索引;以name再创建一个姓名的单列索引。即每个索引包含一个列。
(2)组合索引(复合索引或多列索引):就是表中的两个列或多个列来创建成一个索引;比如;以用户ID、用户名Name、用户年龄Age来创建的索引就是联合索引。
在表格上面创建某个一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。
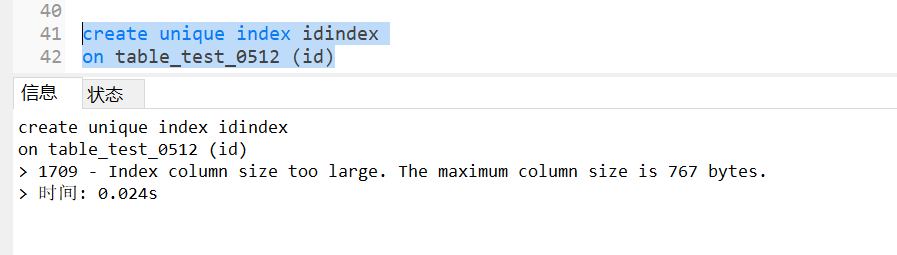
CREATE UNIQUE INDEX 索引名称
ON 表名称 (列名称)
因为查了数据库的字符集类型,编码格式是utf8mb4一个中文是4个字节,所以767个字节最多存储191个中文字符
TEXT、VARCHAR、CHAR等类型的列,只能用前面的 191 个字符做索引,因为 191×4=764,192×4=768,191个字符正好没有超过 767 字节的限制。如果 char、varchar 等定义的长度超过了 191,而指定索引时未说明索引长度,则会自动使用前191个字符做索引。
但是,若是唯一索引,单列的长度不能超过 191个字符,否则报错。
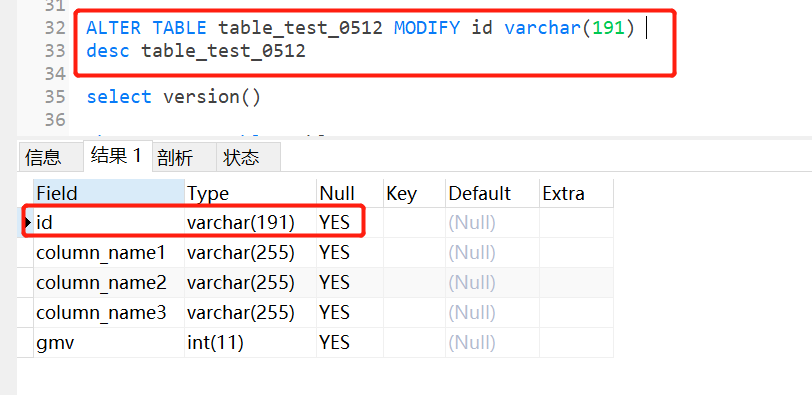
ALTER TABLE <表名> MODIFY <新字段名> <新数据类型>
ALTER TABLE table_test_0512 MODIFY id varchar(191)
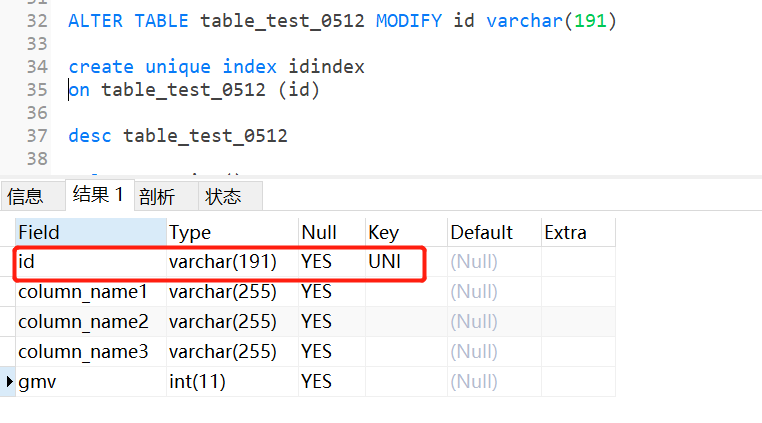
CREATE INDEX 索引名称
ON 表名称 (列名称)
create index column_name1_index
on table_test_0512 (column_name1)
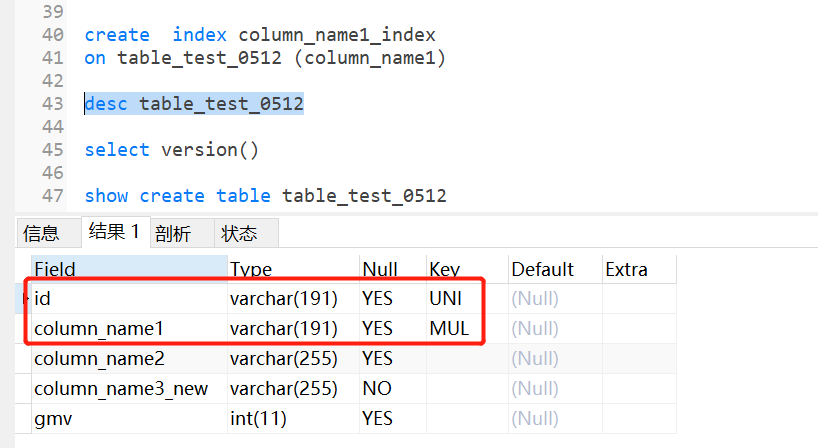
多个简单索引,字段用逗号分隔即可;
CREATE TABLE `table_test_0513` (
`id` varchar(191) DEFAULT 1,
`column_name1` varchar(191) DEFAULT ‘qiaqia‘,
`column_name2` varchar(255) DEFAULT ‘guanzhu‘,
`column_name3_new` varchar(255) NOT NULL,
`gmv` int(11) DEFAULT 100,
UNIQUE KEY `idindex` (`id`),
KEY `column_name1_index` (`column_name1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
#删除索引 17 drop index index_n on my_test;
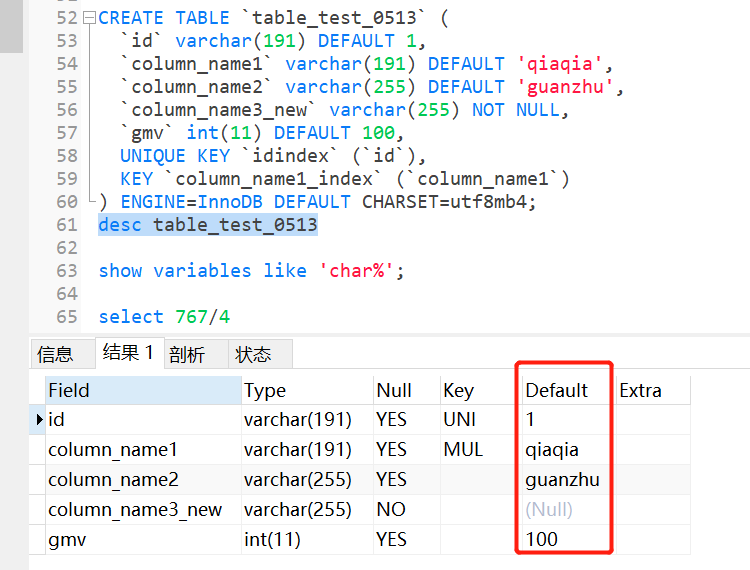
CREATE TABLE `table_test_05132` (
`id` varchar(191) DEFAULT 1,
`column_name1` varchar(191) DEFAULT ‘qiaqia‘,
`column_name2` varchar(255) DEFAULT ‘guanzhu‘,
`column_name3_new` varchar(255) NOT NULL,
`gmv` int(11) DEFAULT 100,
PRIMARY KEY `idindex` (`id`),--主键且默认是索引,不允许为空和重复值
KEY `column_name1_index` (`column_name1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
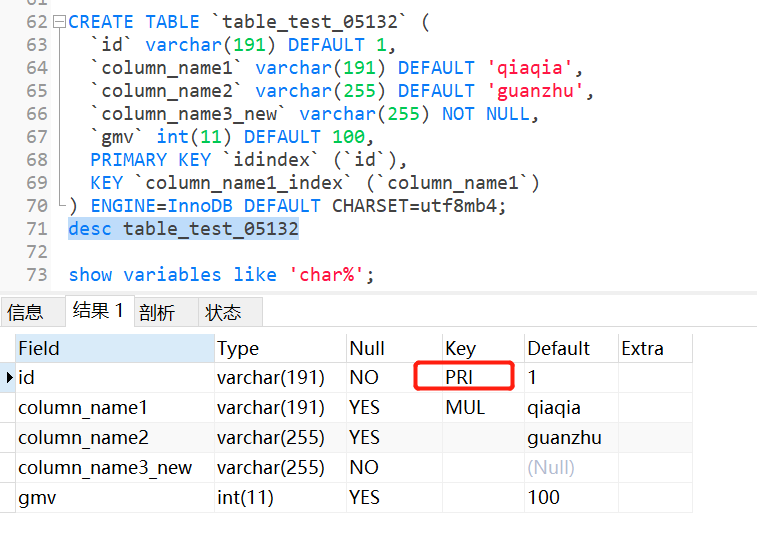
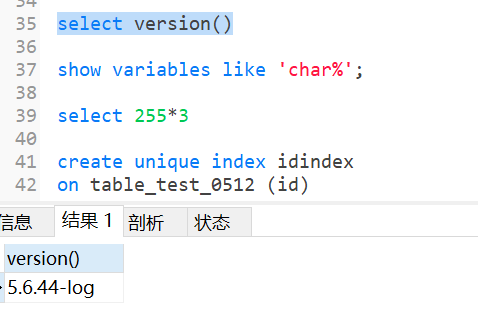
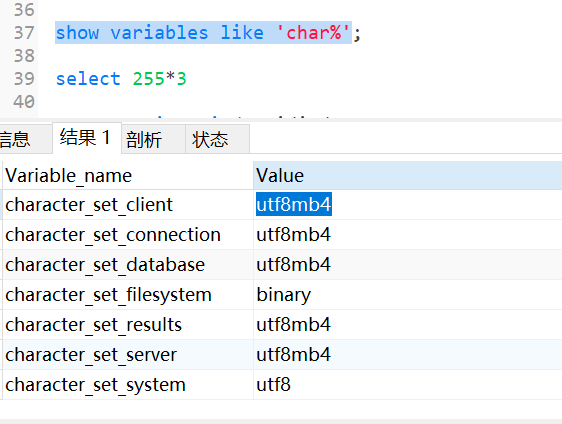
show variables like ‘char%‘;
名词解释:character_set_client:客户端请求数据的字符集character_set_connection:客户机/服务器连接的字符集character_set_database:默认数据库的字符集,无论默认数据库如何改变,都是这个字符集;如果没有默认数据库,那就使用 character_set_server指定的字符集,这个变量建议由系统自己管理,不要人为定义。character_set_filesystem:把os上文件名转化成此字符集,即把 character_set_client转换character_set_filesystem, 默认binary是不做任何转换的character_set_results:结果集,返回给客户端的字符集character_set_server:数据库服务器的默认字符集character_set_system:系统字符集,这个值总是utf8,不需要设置。这个字符集用于数据库对象(如表和列)的名字,也用于存储在目录表中的函数的名字。
以上这些参数如何起作用:
1.库、表、列字符集的由来
①建库时,若未明确指定字符集,则采用character_set_server指定的字符集。
②建表时,若未明确指定字符集,则采用当前库所采用的字符集。
③新增时,修改表字段时,若未明确指定字符集,则采用当前表所采用的字符集。
2.更新、查询涉及到得字符集变量
更新流程字符集转换过程:character_set_client-->character_set_connection-->表字符集。
查询流程字符集转换过程:表字符集-->character_set_result
3.character_set_database
当前默认数据库的字符集,比如执行use xxx后,当前数据库变为xxx,若xxx的字符集为utf8,那么此变量值就变为utf8(供系统设置,无需人工设置)。
1.不区分大小写,但是建议关键字大写,表名、列名小写
2.每条命令最好用分号结尾
3.每条命令根据需要,可以进行缩进或换行
4.注释:
单行注释:#
单行注释:--
多行注释:/* */
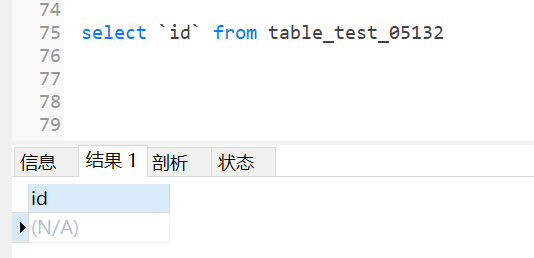
select `id` from table_test_05132
``是着重符,为了告诉sql服务器这个是一个字段,不是关键字
起别名的意义:便于理解、如果有查询字段重复可以用别名区分;
运算符的作用
select 100+100;两个操作数都为数值则做加减乘除法运算
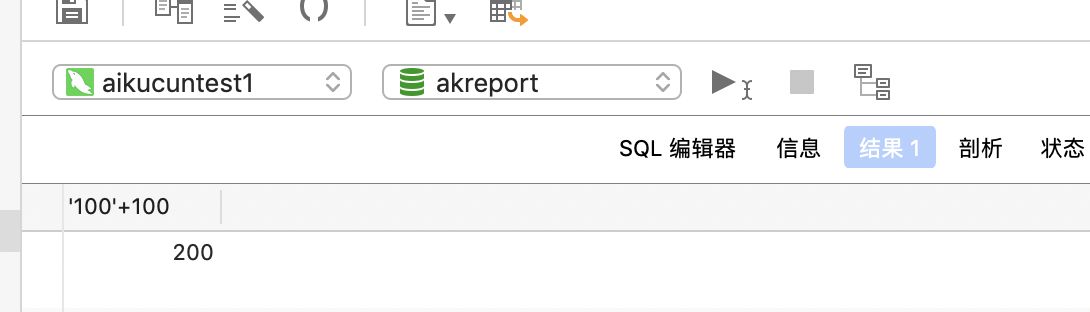
select ‘100‘+100;其中一方为字符型,试图将字符型数值转成数值型;如果转换成功则做加法运算,

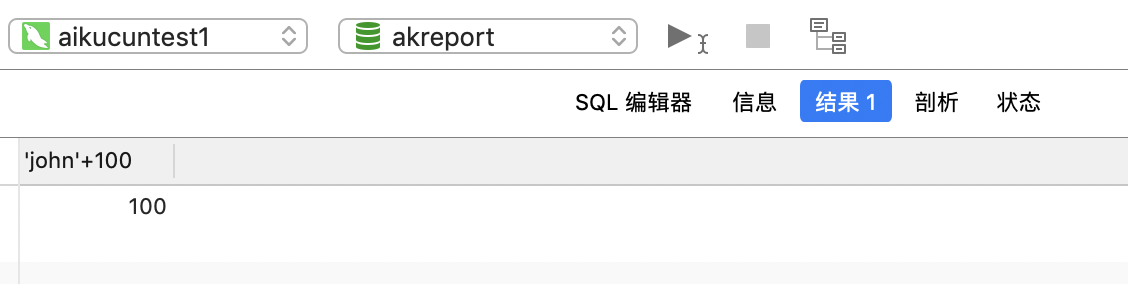
如果转换失败则将字符型数值转换成0:select ‘john‘+100;
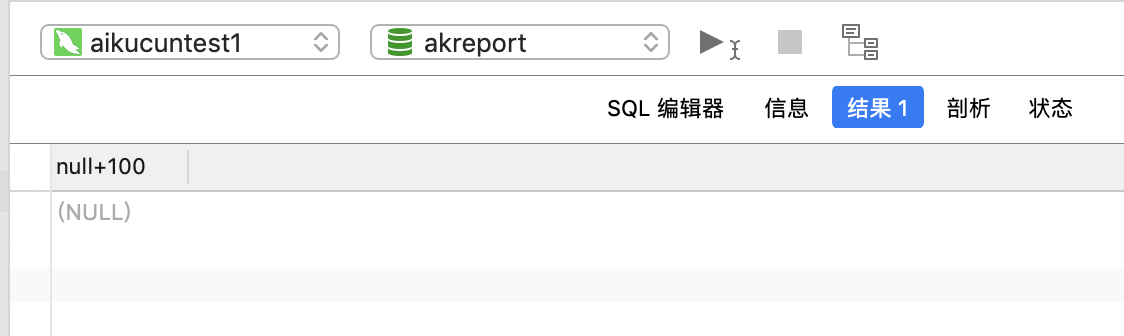
只要有一方是null,则结果是null
select null+100;
IFNULL(判断是否不为null的参数,为null则返回第二个参数值):
第一个参数不为null则返回第一个参数的值
如果为null,则返回第二个参数值;
这个函数只适用于mysql;
返回参数列表中第一个不为null的参数值;
hive与mysql通用
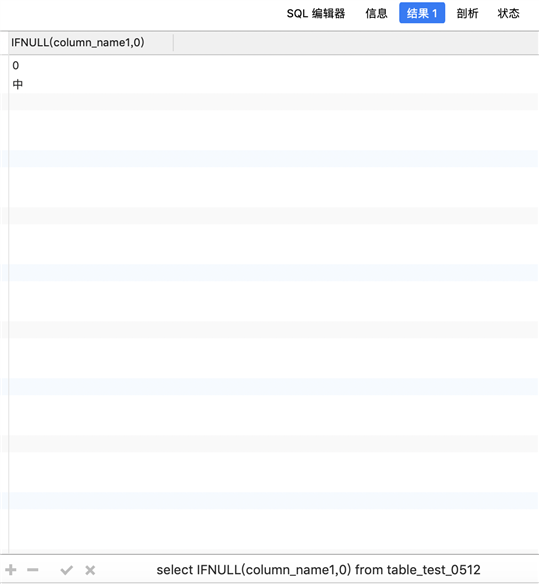
select IFNULL(column_name1,0) from table_test_0512
select COALESCE(column_name1,0) from table_test_0512
适用于数字型、字符型和日期型 , 不适用于mysql 适用于 oracle 和hive
Select NVL(null, 2)
> 、<、 =、 !=、 <>、 >=、 <=;
逻辑运算符:连接多个条件表达式
与:&&=and、或:||=or、非; !=not推荐用not
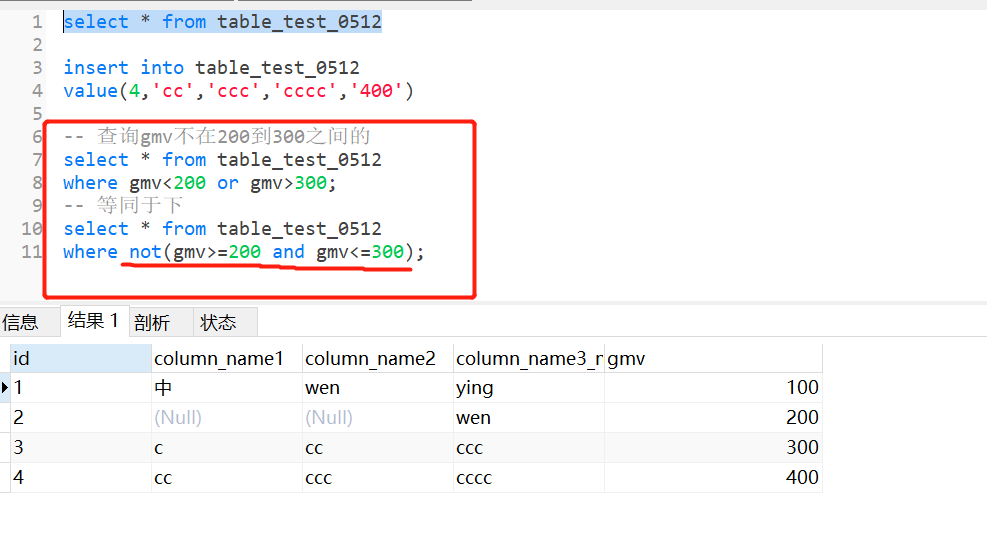
-- 查询gmv不在200到300之间的记录
select * from table_test_0512
where gmv<200 or gmv>300;
-- 等同于下
select * from table_test_0512
where not(gmv>=200 and gmv<=300);--gmv在200~300之间的否定则是不在这个范围的数据记录
一般和通配符搭配使用
通配符:
% 任意多个字符,包含0个字符
_ 任意单个字符
like 举例:
like的通配符在前%/_xxxxx,表示前模糊即半模糊,在后表示后模糊xxxx_/%,前后都有则表示全模糊%/_xxxxx%/_;
查询表中第三个字符是m,第六个字符是n的column_name1
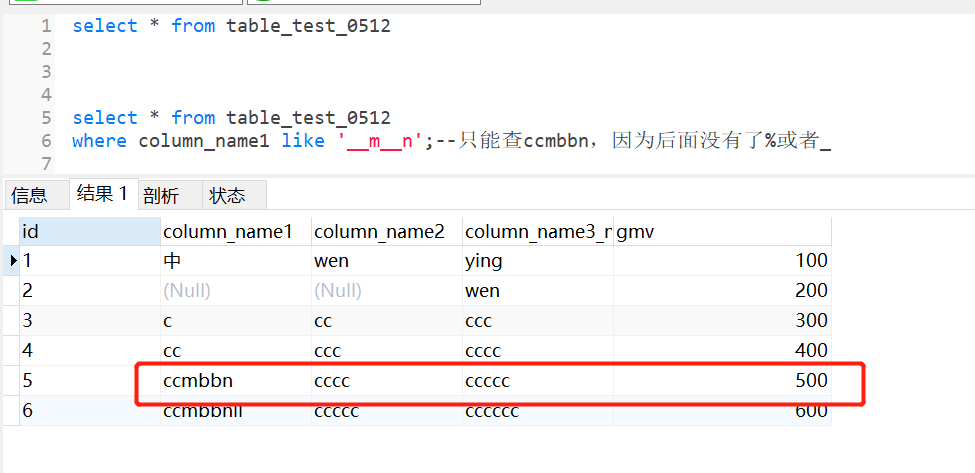
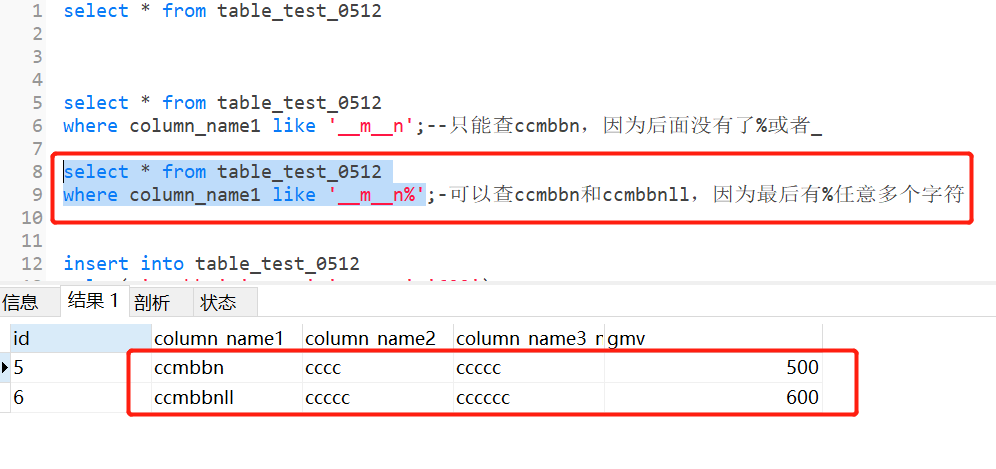
需要用到转义字符“\”,告诉服务器斜杠后面的_是单纯的下划线不是任意单个字符
select * from table_test_0512
where column_name1 like ‘_\_%‘
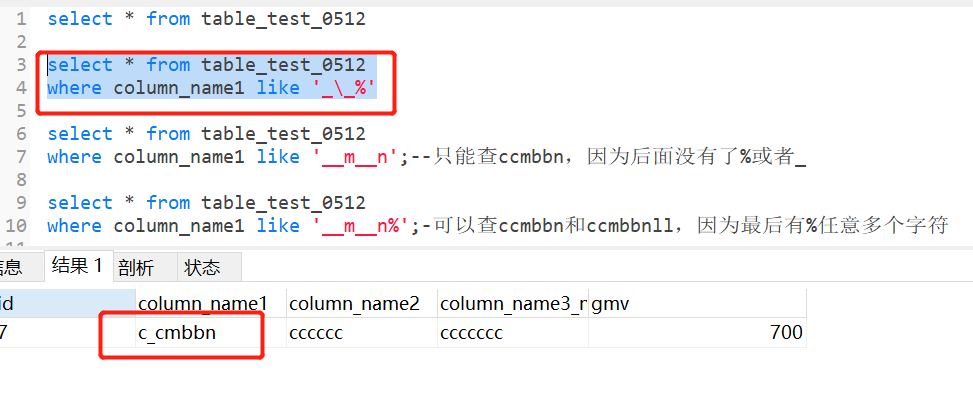
转义字符除了用斜杠\,还可以自定义,使用函数escape,escape后面的字符就是自定义的转义字符
select * from table_test_0512
where column_name1 like ‘_$_%‘ escape ‘$‘

判断为空不能用字段名=null,因为=判断不出来nul值,所以只能用is null;
拓展:select * from table_test_0512和
select * from table_test_0512
where column_name1 like ‘%%‘;
select * from table_test_0512
where column_name1 like ‘%%‘ or column_name3_new like ‘%%‘;
相等么?
答案是:不一定,首先%%不能查字段为null,所以为null记录查不出来,但是只要不存在null值就相等;
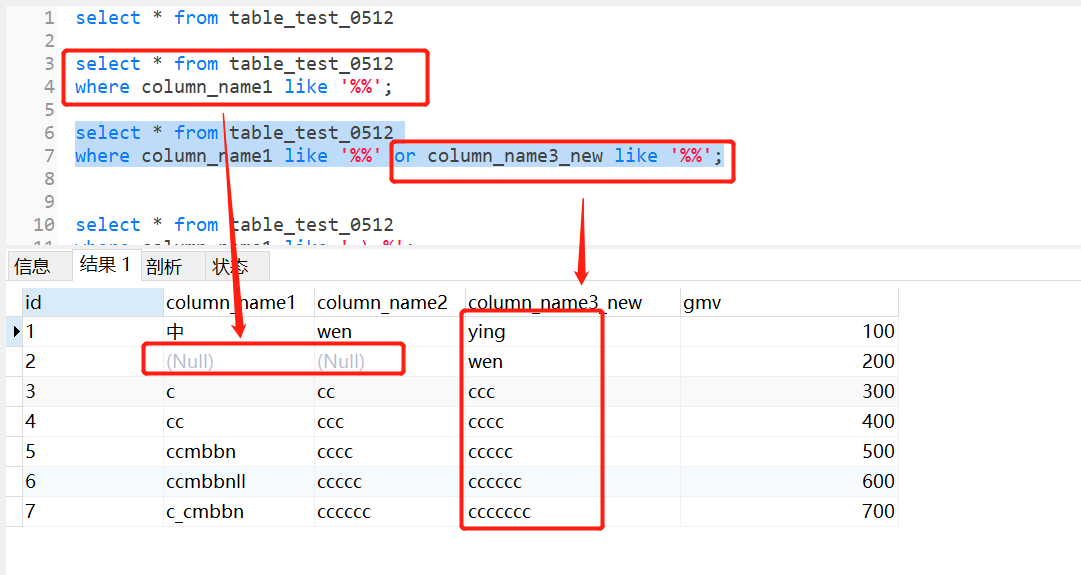
因为where后的条件是针对表内的字段,执行顺序高于select语句,不属于表内的字段是不认识的
因为排序是将查询的select结果排序,执行顺序低于select的,是认别名的;
order by 排序多个字段用逗号分隔,后面都需要加上是asc/desc,asc可以省略;
字节长度函数,在utf-8数据类型下一个英文字母是一个字节,一个中文是3个字节
在utf-8mb4是一个英文是1一个字节,一个中文是4个字节;
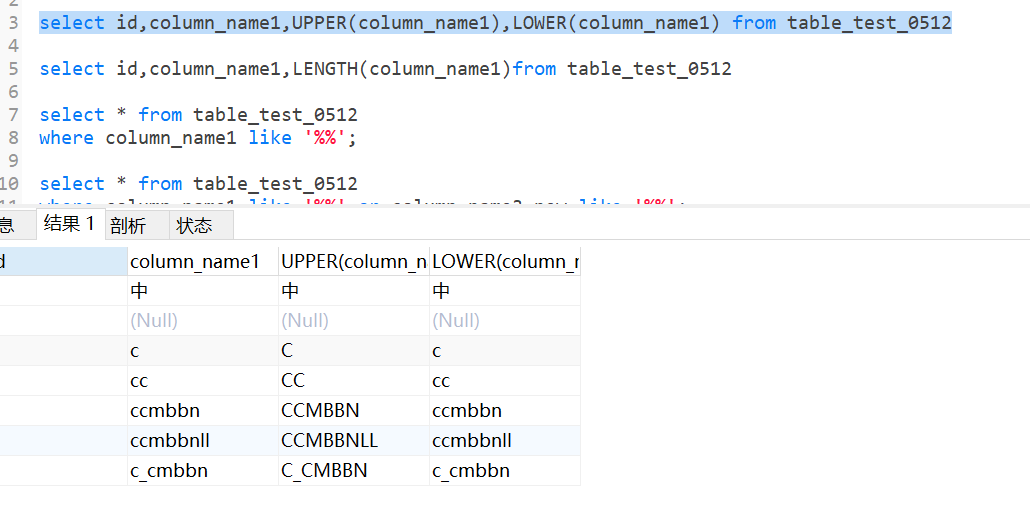
upper是字符串转大写
lower是字符串转小写
select id,column_name1,UPPER(column_name1),LOWER(column_name1) from table_test_0512
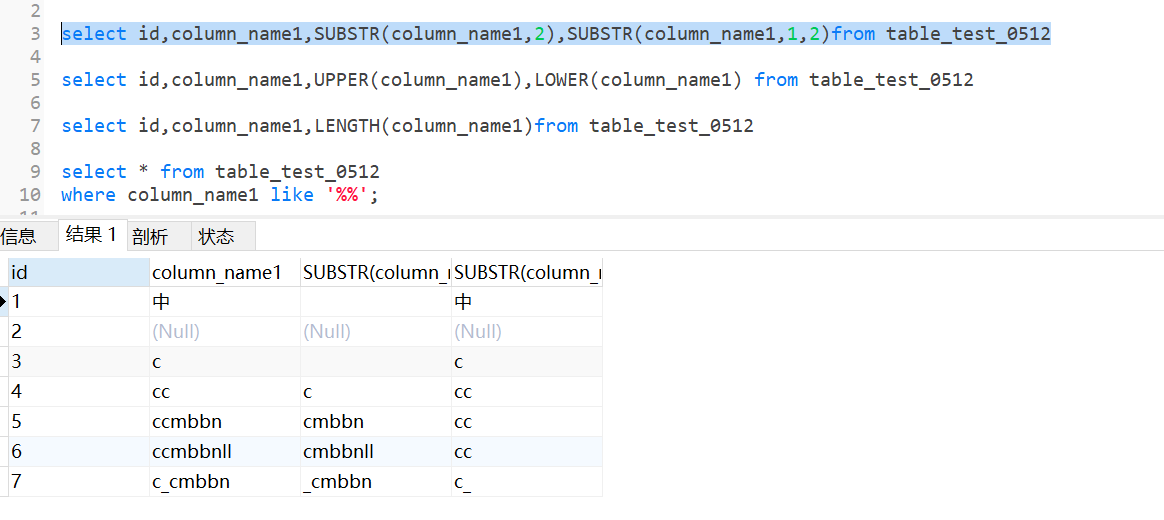
substr(exp1,2)截取从第2个字符开始;
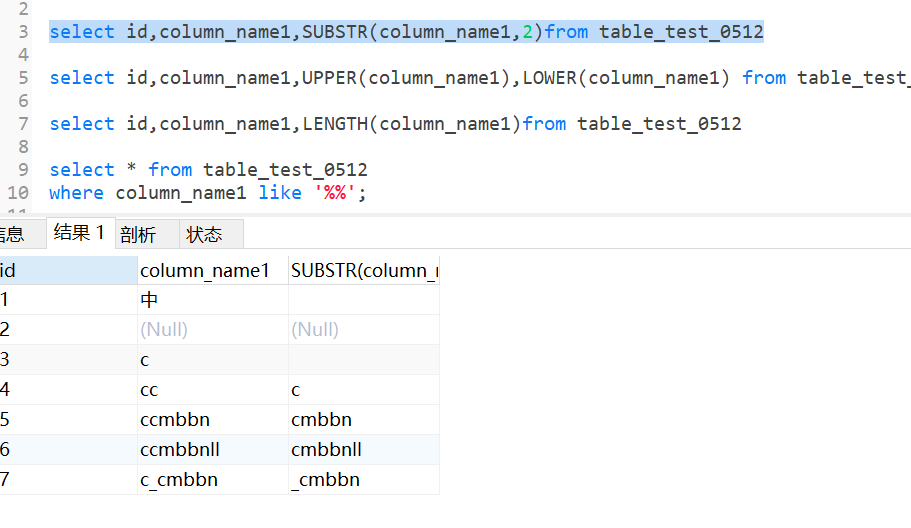
subatr(exp1,1,2)截取从第一个到第2个字符;
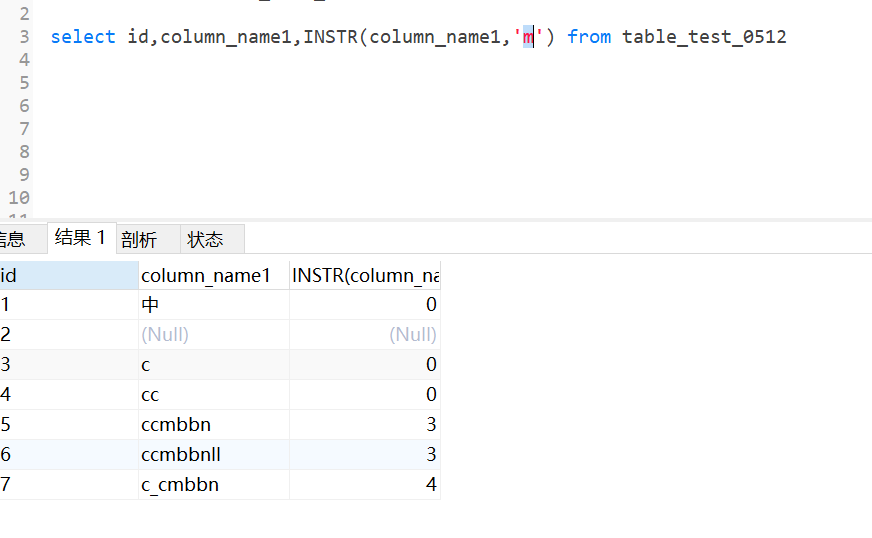
返回字段中第一次出现的索引,如果找不到则返回0
实例中找name1中m第一次出现的索引
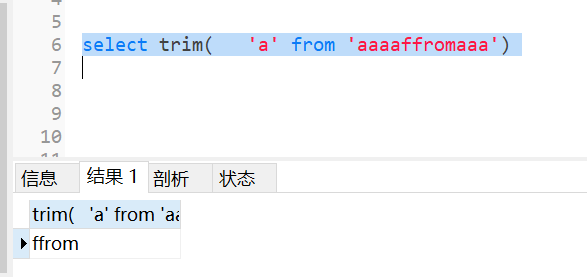
默认去掉前后空格
想要去掉字段前后的字符,可以传参数:trim(exp1 from exp2)把exp2中的前后exp1去掉
lpad是左填充,如果本身字符串长度够,就不需要填充,长度不足才要填充
参数:lpad(exp1,12,‘*‘)
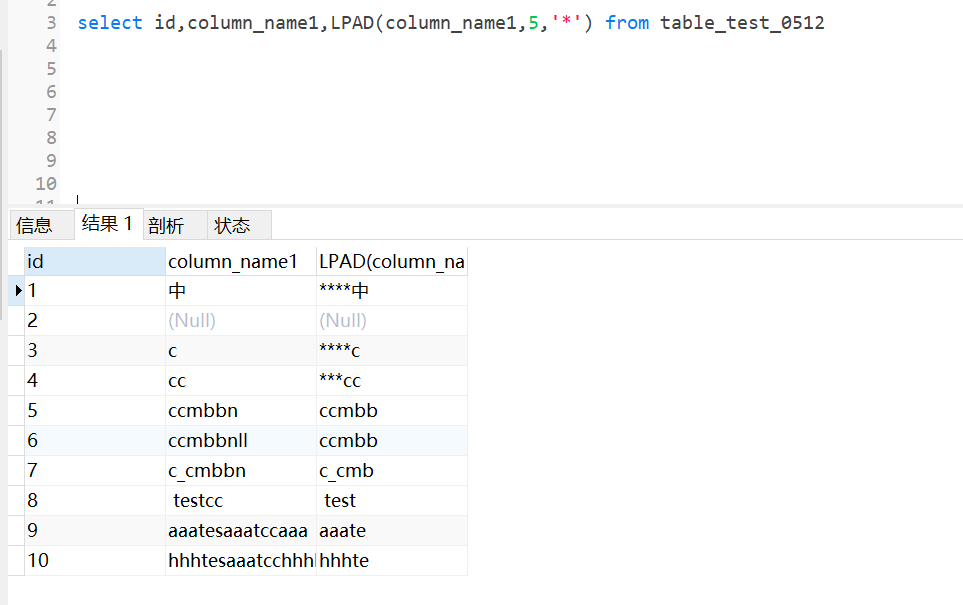
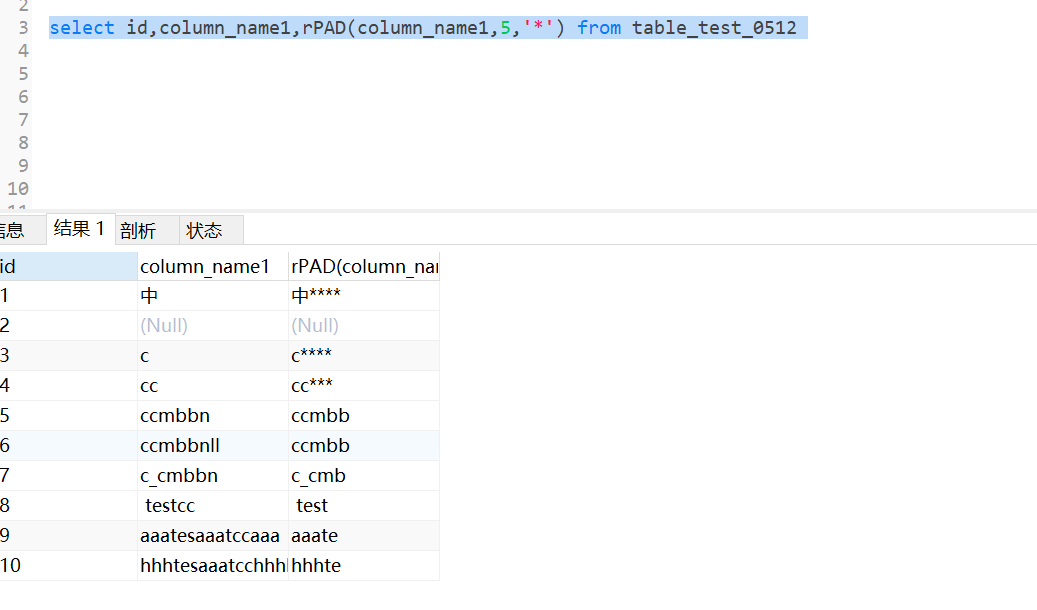
rpad 右填充
round不填保留几位则默认是四舍五入保留整数
相当于%
select mod(10,3)=select 10%3
被除数是负数/正数,则余数就是负数/正数
select mod(-10,3)=-1
select mod(10,-3)=1
可以验证下,取余就是select mod(a,b)=select a-a/b*b=select mod(-10,3)=select -10-(-10/3*3)
=select -10-(-9)=-1
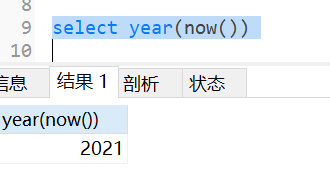
select now();
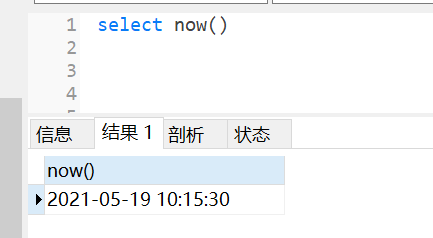
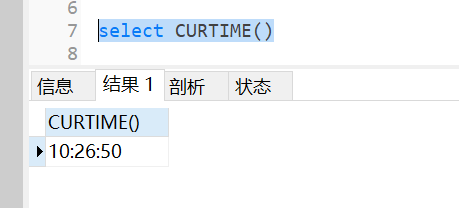
select curtime();
select CURRENT_DATE()
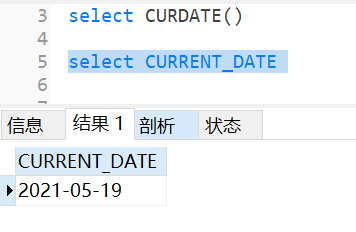
select cuttime();
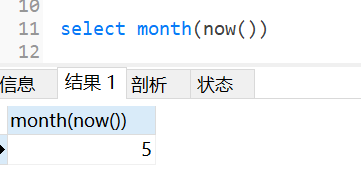
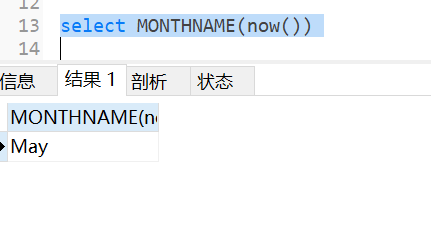
获取英文的月份:
一月:January(尖)、二月:February(飞鸟)、三月:march(马吃)、四月:April(A与4型近)、五月:may(妩媚)、六月:june(祝嗯-六一)、七月:july、八月:August、九月:September(蛇泡酒)、十月:October、十一月:November(no 温度)、十二月:december(底)
将字符串类型的日期转换成对应的日期格式
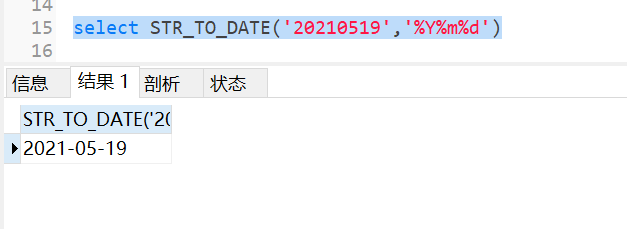
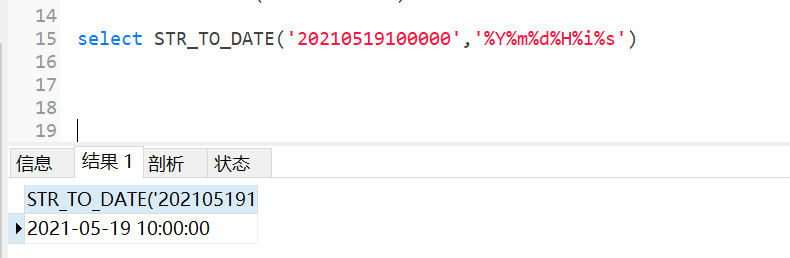
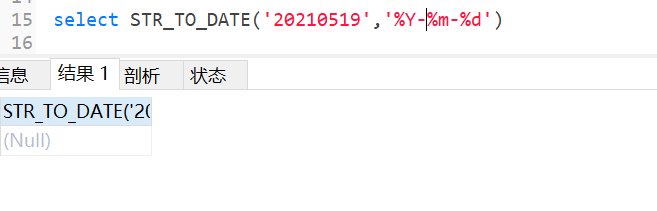
mysql默认支持的日期格式是YYYY-MM-DD或者YYYY/MM/DD、YYYYMMDD,所以如果字符串格式是这种可以使用date直接转换成日期
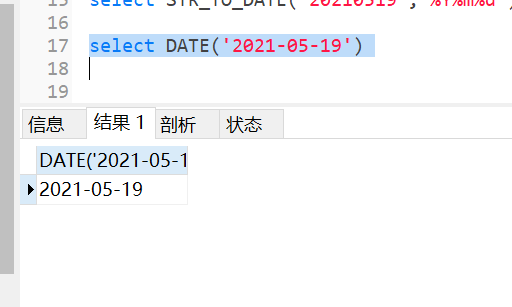
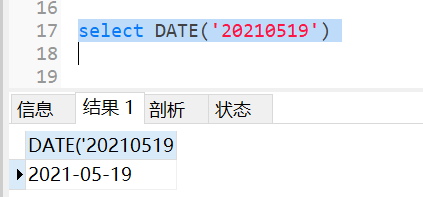
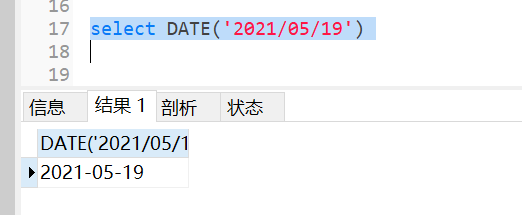
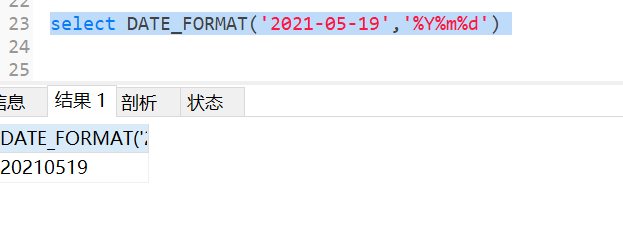
如果已经得到一个标准日期格式的字段,想要自定义日期的显示的格式,可以使用此函数
select DATE_FORMAT(‘2021-05-19‘,‘%Y%m%d‘)
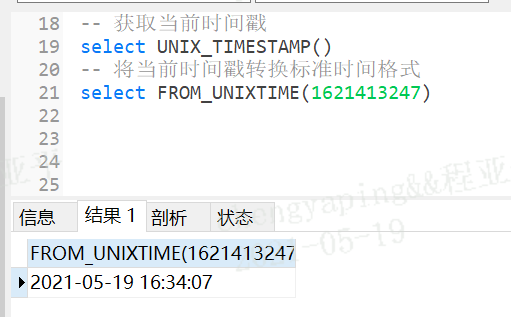
将当前时间的时间戳格式转化为标准时间格式
select from_unixtime()
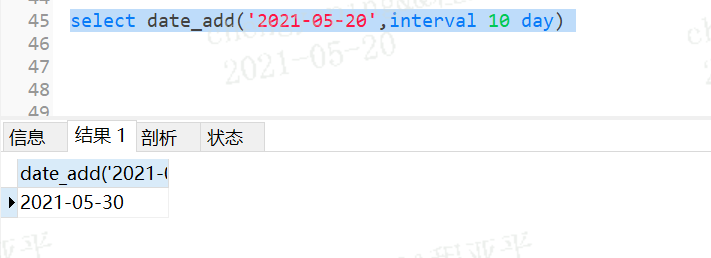
select date_add(‘2021-05-20‘,interval 10 day);
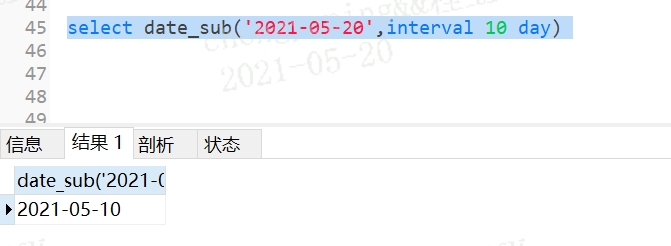
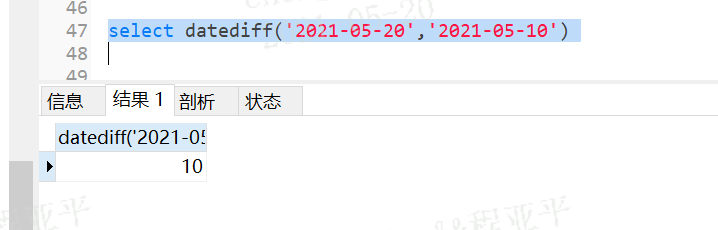
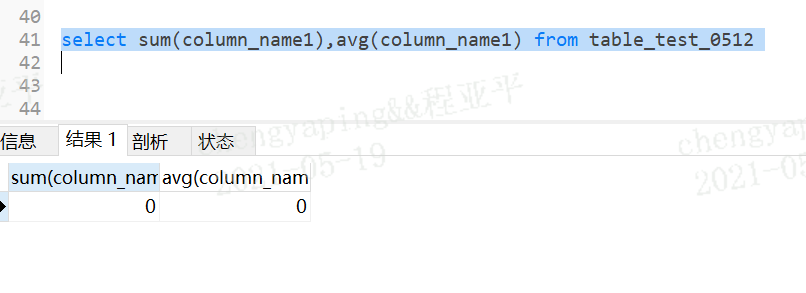
功能是做统计使用;
分类:sum() max() min() avg() count()
特点:
如果不是数值型会尝试转换,转换数值不成功则返回0
语法:if(判断语句,判断语句为true后的取值语句,判断语句为false后的取值语句);
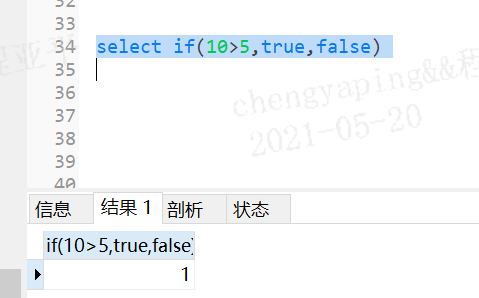
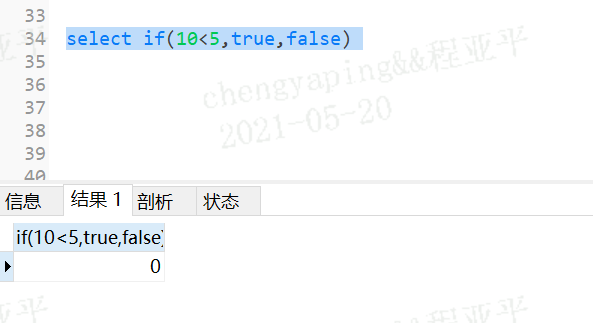
when 常量1 then 要显示的值1或语句1
when 常量2 then 要显示的值2或语句2
。。。
else 要显示的值n或语句n;
end as 别名--必须要起别名,因为then后面的值必须有个字段列展示出来
类似于java 的switch case
select
case user_role
when ‘b‘ then ‘b‘
when ‘e‘ then ‘e‘
when ‘全部‘ then ‘全部‘
end as user_role
from rpt_operate_order_flow_period
where date_time_key=(select MAX(date_time_key)
from rpt_operate_order_flow_period)
and user_role <>‘o‘
group by user_role
when 条件2 then 2
。。。
else 条件n then n
end as 别名
select
case
when user_role=‘b‘ then ‘b‘
when user_role=‘e‘ then ‘e‘
when user_role=‘全部‘ then ‘全部‘
end as user_role
from rpt_operate_order_flow_period
where date_time_key=(select MAX(date_time_key)
from rpt_operate_order_flow_period)
and user_role <>‘o‘
group by user_role
where CASE
WHEN ${datatype} =‘d‘ and ${datadate} is null then datadate=(select current_date - integer ‘1‘)--条件判断可以增加多个用and连接
WHEN ${datatype} =‘d‘ and ${datadate} is not null then datadate=${datadate}
WHEN ${datatype} != ‘d‘ then datatype = ${datatype} else true end;
where period_type=‘accu‘
and case when ${user_role} is null then user_role=‘全部‘
else user_role in (${user_roles}) end
and case when ${user_level} is null then user_level=‘全部‘
else user_level in (${user_levels}) end
当字段值是随着前端的筛选随机变化时,那么where条件中该字段值的判断需要用变量来表示${}
and case when ${user_role} is null then true else ${user_role} end-------${user_role}代表是字段名
and case when ‘${user_role}‘ is ‘null‘ then true else user_role = ‘${user_role}‘ end------ ‘${user_role}‘ 代表是将false的结果复制给字段名
then true是表示不做处理,获取全量数据
如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。两个字段都相同的行会聚合成一行,否则就是多行
select 聚合函数,(group by后面的字段)
from 表
where
group by 分组列表
having 字段必须是聚合函数表达式,可以是表中任意字段
order by ;
select column_name2,MAX(gmv) from table_test_0512
group by column_name2
having max(gmv)>=500
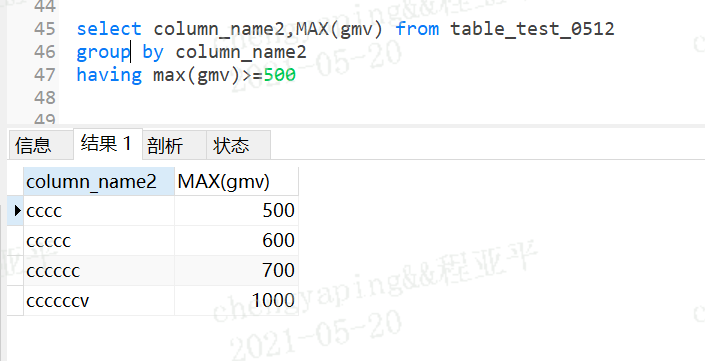
分组查询中的筛选条件分为两类:
1.分组前筛选 针对的是原始数据源即where部分
2.分组后筛选 分组后的结果集having部分
group by和having、order by 后可以跟select 别名
表1 m行 表2 n行,结果为m*n行
发生原因是因为没有:没有有效的连接条件
如何避免:添加有效的连接条件即where条件;
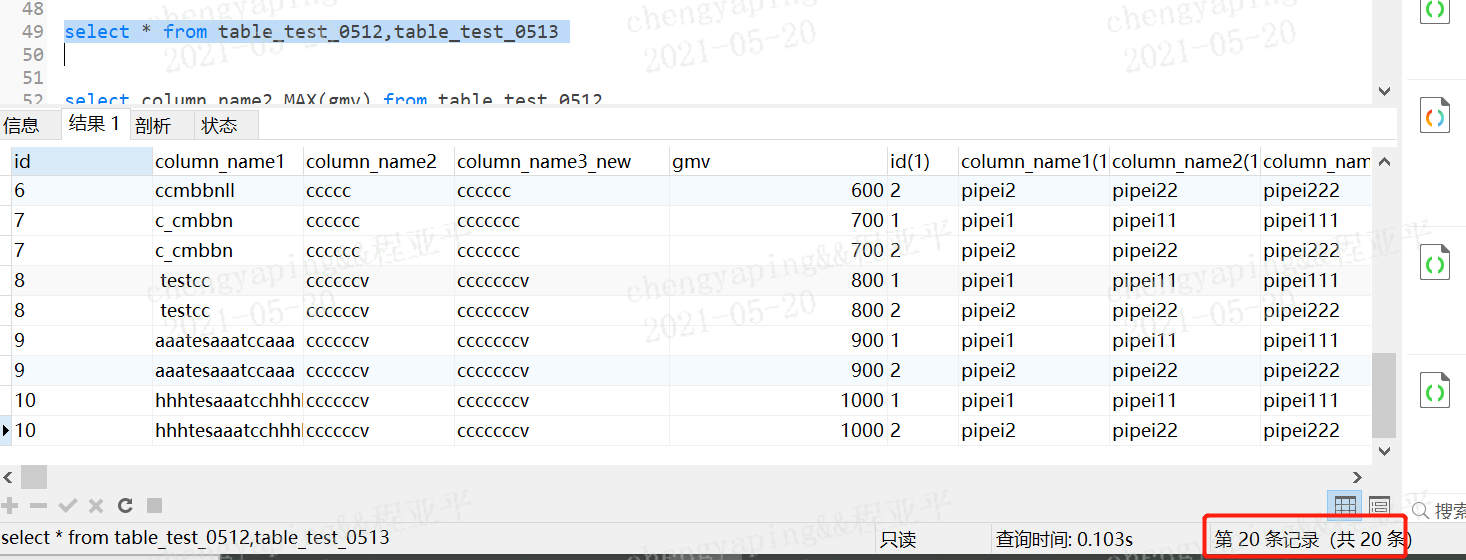
where 条件中用:表名.字段名=表名.字段名

select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where】
【group by】
【having】
【order by】
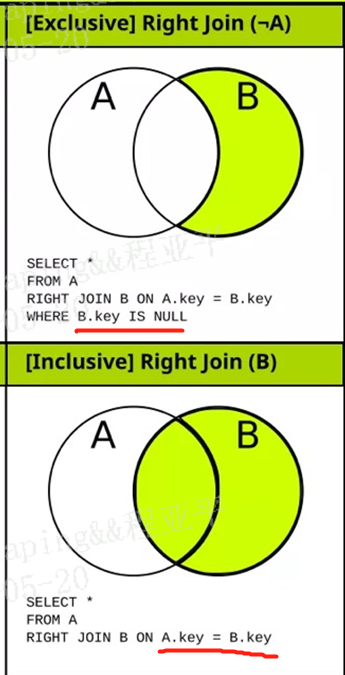
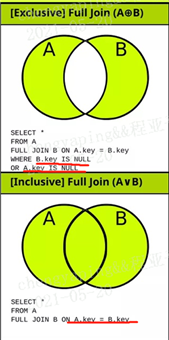
如图 on字段相等的数据记录,不相等的行剔除
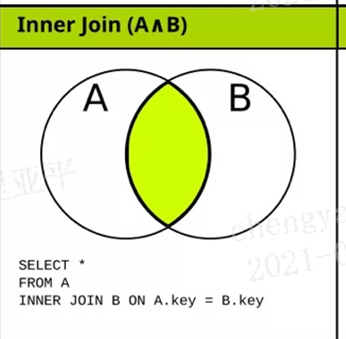
如果是三个及以上的表连接如下:那么就有顺序要求,因为A和B join后的结果集和C再去连接的,所以必须前面的结果集能和C有关联到的字段才行;
select * from A
inner join B on A.id=B.id
inner join C on A.key=C.key
a.id<=b.id则是将a表每一行的id值和b表对比,如果满足条件则输出展示
a的id=1 b表的id=1相等,则输出
a的id=1小于 b表的id=2,则输出
a的id=2 b表的id=2相等,则输出
忽略id=10,因为是字符串没比较出来;
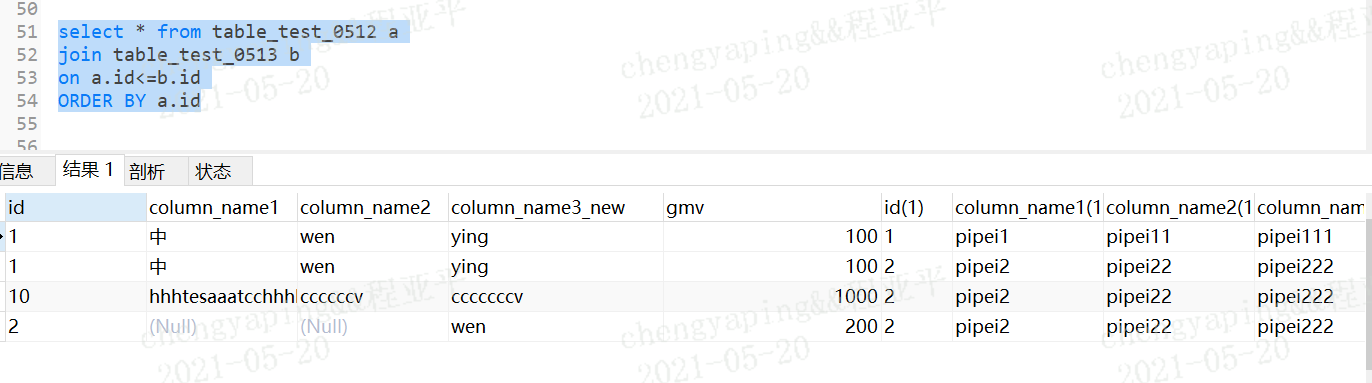
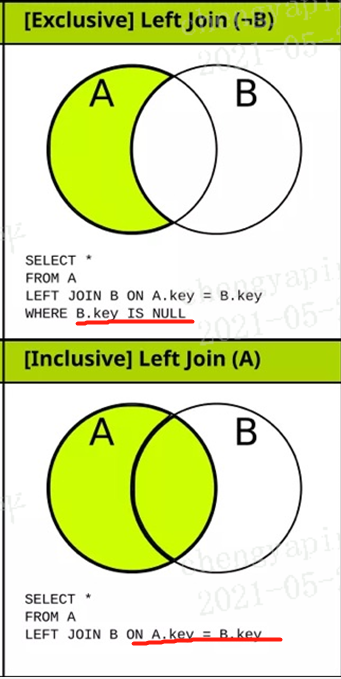
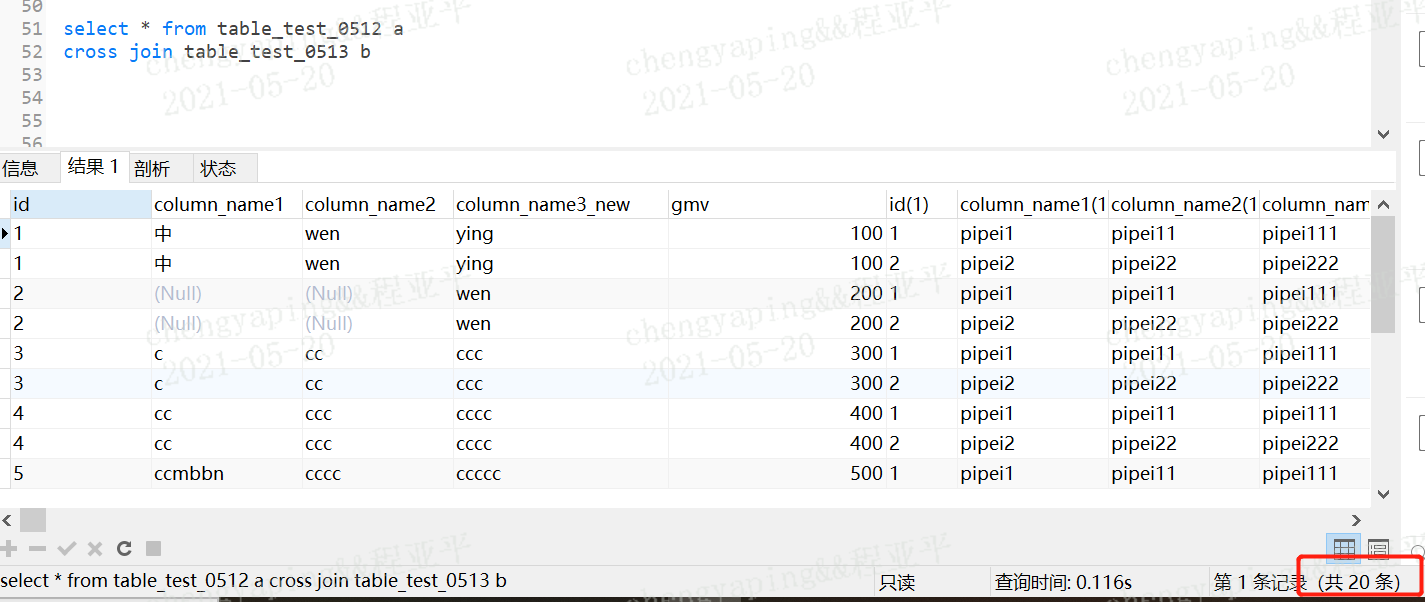
也就是笛卡尔乘积
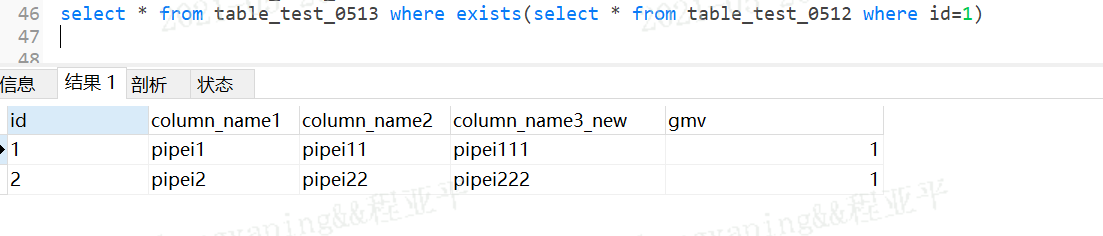
exists(完整的查询语句)
结果:1/0
如果子查询结果有数据,则存在=1,否则=0
经常用来放在where后面,必须where exists子查询存在,那么where前的查询才生效
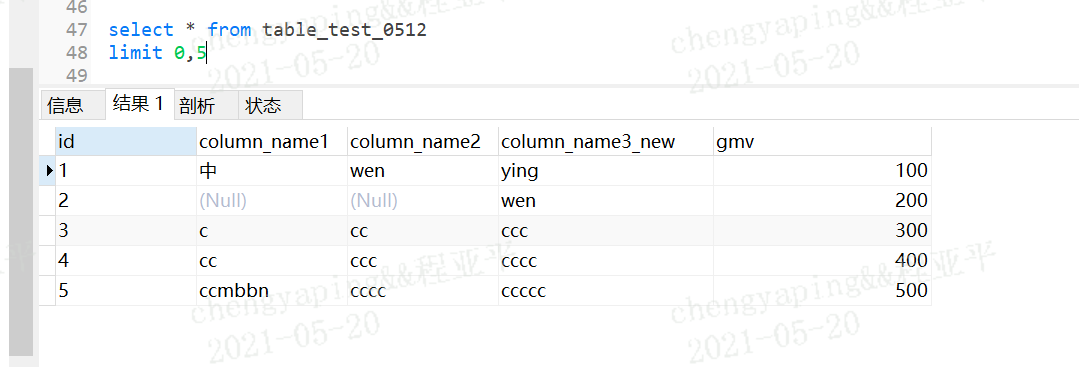
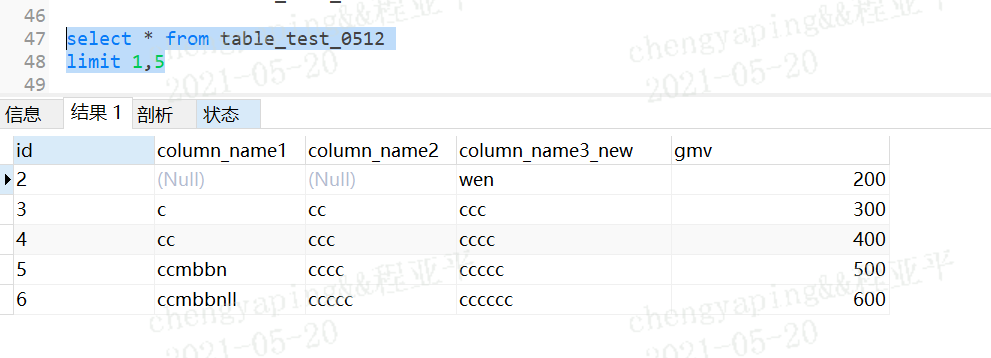
limit offset,size
offset是起始索引,即从第几行开始,mysql中从0开始表示第一行记录
size是获取条目
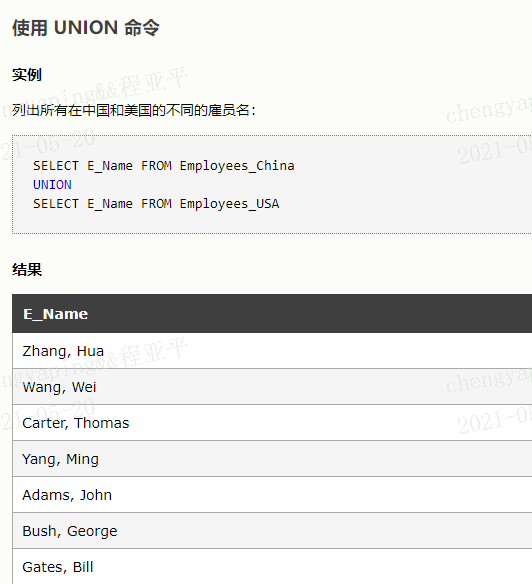
UNION 内部的 SELECT 语句必须拥有相同数量的列;
列也必须拥有相似的数据类型;
每条 SELECT 语句中的列的顺序必须相同;
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
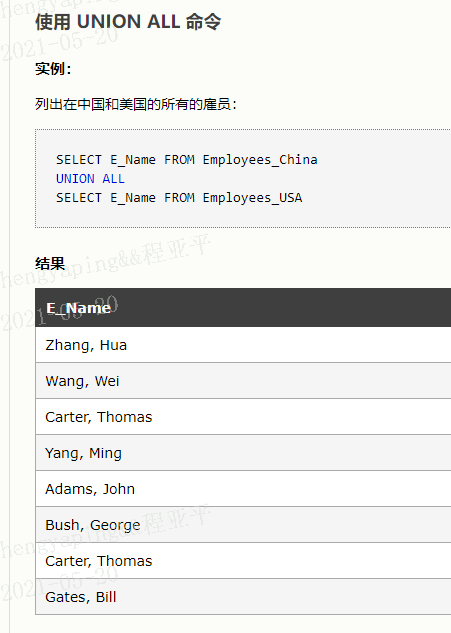
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
#批量插入带有自增字段的记录
insert into rpt_kpi_dboard_1d
set @id=0;--初始化id
select (@id:=@id+1) id
update 表名1 别名
inner/left/right/full join 表名2 别名
on 连接条件
set 列=值。。。
where 筛选条件
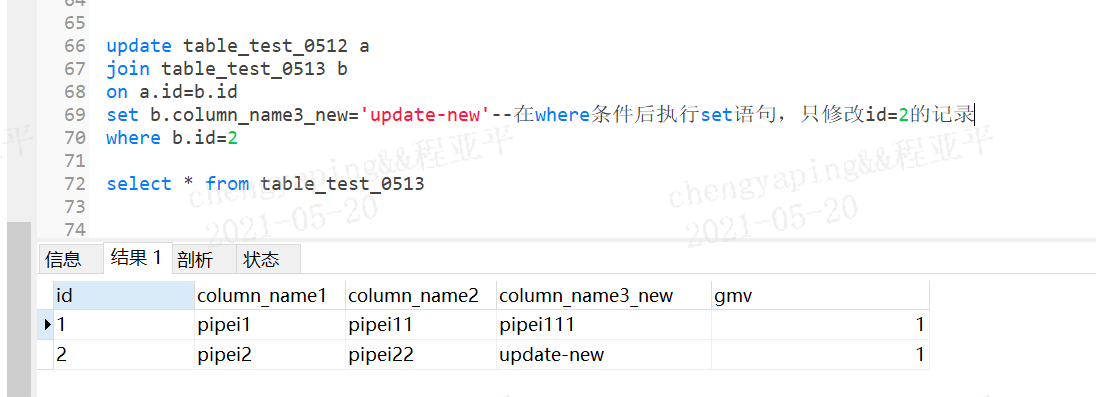
update table_test_0512 a
join table_test_0513 b
on a.id=b.id
set b.column_name3_new=‘update-new‘--在where条件后执行set语句,只修改id=2的记录
where b.id=2
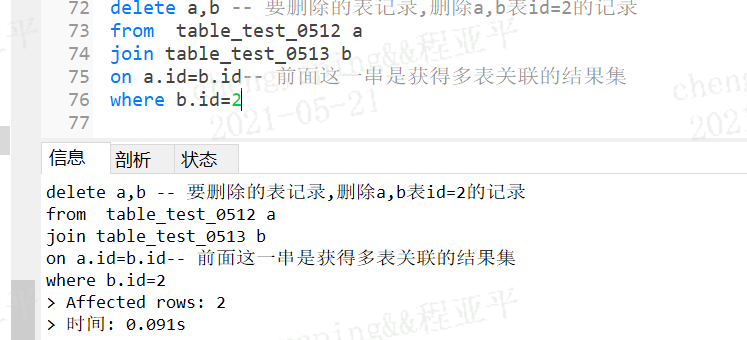
语法:delete 表1别名,表2别名
from 表1 别名
关联类型 join 表2 别名
on 连接条件
where 筛选条件后删除;
delete a,b -- 要删除的表记录,删除a,b表id=2的记录
from table_test_0512 a
join table_test_0513 b
on a.id=b.id-- 前面这一串是获得多表关联的结果集
where b.id=2
delete from users where 条件语句
truncate table 表名;
truncate table users;--truncate语法是不能加where条件,要删除都是整个表删除;
事务是由单独单元的一个或多个sql语句组成,在这个单元中(执行sql时选中的所有语句),每个mysql语句是相互依赖的。而整个单独单元作为一个不可分隔的整体,如果单元中某条sql语句一旦执行失败或者产生错误,整个单元将会回滚;
从5.0.1版本开始提供视图的功能。一种虚拟存在的表,行和列的数据来自定义视图的逻辑sql里的表,并且是在使用视图时动态生成,只保存sql逻辑,不保存查询结果;
/*
create view 视图名
as
select from表
*/
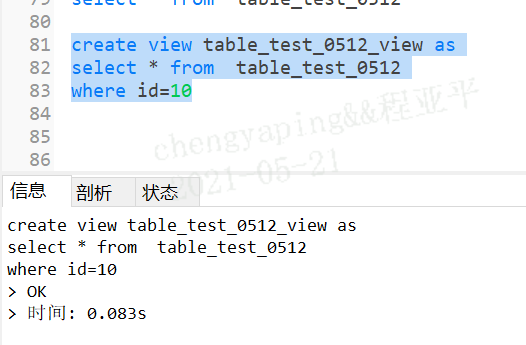
create view table_test_0512_view as
select * from table_test_0512
where id=10
在视图列表就会看到创建的视图
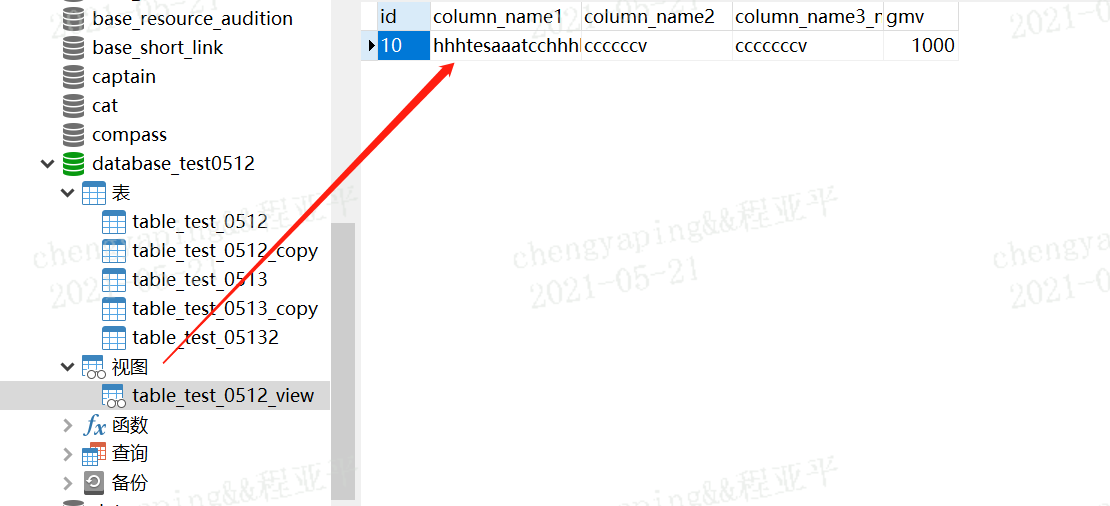
drop view 视图名
语法:
set @变量=变量值;或者
set @变量:=变量值;
用户自定义变量和引用的语句要用分号隔开,否则属于一个事务同时执行,那么后面的语句拿不到初始化后的值会爆错;
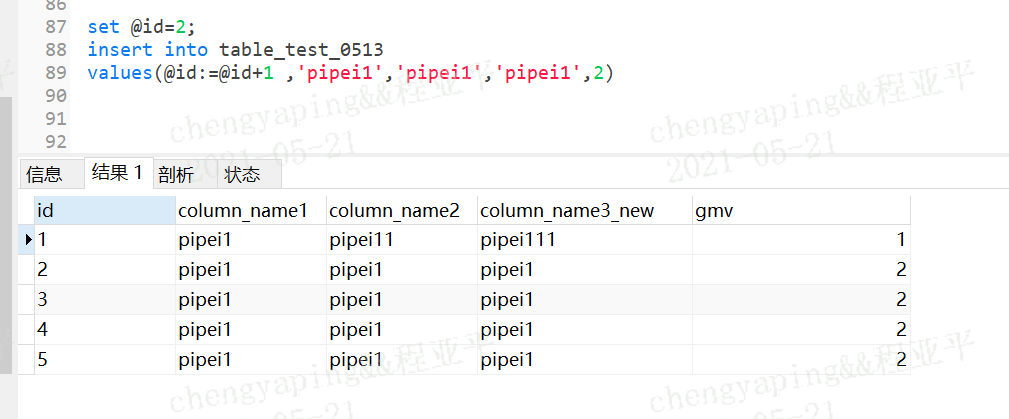
set @id=2;--限执行这个
insert into table_test_0513--再执行这个,那么第二次就不会执行初始化语句了,就会不断地自增下去的;
values(@id:=@id+1 ,‘pipei1‘,‘pipei1‘,‘pipei1‘,2)
原文:https://www.cnblogs.com/T-CYP/p/14760818.html