
#!/usr/bin/env python # -*- coding: utf-8 -*- #告诉python2使用utf-8执行下面代码 print "你好,世界"
C:\Windows\system32>python2 D:\test\python\test\test2.py #coding:utf8 import sys print(sys.getdefaultencoding()) #结果是:ascii
#!/usr/bin/env python3 print "你好,世界"
import sys print(sys.getdefaultencoding()) #结果是:utf-8

示例1:
# coding:utf8 #告知python解释器,这个.py文件里的文本是用utf-8编码的,这样解释器就会依照utf-8的编码形式解读其中的字符。 str1 = ‘hengha‘ print(str1, type(str1)) #结果是:(‘hengha‘, <type ‘str‘>) #python2.x将字符串处理为str类型,即字节型。 str2 = ‘哼哈‘ print(str2, type(str2)) #结果是:(‘\xe5\x93\xbc\xe5\x93\x88‘, <type ‘str‘>) #前面输出的是字节型,这是print函数的原因。 print(str2) #结果是:鍝煎搱 #这里python解释器用的编码是utf8,但cmd用的是gbk。按utf8输出,用gbk解释。 uutf = str2.decode(‘utf8‘) #str2本来就是字节型的,因此只能进行decode解码。 print(uutf, type(uutf)) #结果是:(u‘\u54fc\u54c8‘, <type ‘unicode‘>) #前面输出的是字节型,这是print函数的原因。 print(uutf) #结果是:哼哈 x = 1 print(x, type(x)) #结果是:(1, <type ‘int‘>) y = 1.1 print(y, type(y)) #结果是:(1.1, <type ‘float‘>)
示例2:
str1 = ‘hengha‘ print(str1, type(str1)) #结果是:hengha <class ‘str‘> #python3.x将字符串处理为str类型,即字符串型。 str2 = ‘哼哈‘ print(str2, type(str2)) #结果是:哼哈 <class ‘str‘> #python3.x将字符串处理为str类型,即字符串型(unicode编码)。 print(str2) #结果是:哼哈 uutf=str2.encode(‘utf8‘) #str2本来就是字符串型的,因此只能进行encode编码。 print(uutf,type(uutf)) #结果是:b‘\xe5\x93\xbc\xe5\x93\x88‘ <class ‘bytes‘> print(uutf) #结果是:b‘\xe5\x93\xbc\xe5\x93\x88‘ x = 1 print(x,type(x)) #结果是:1 <class ‘int‘> y=1.1 print(y,type(y)) #结果是:1.1 <class ‘float‘>
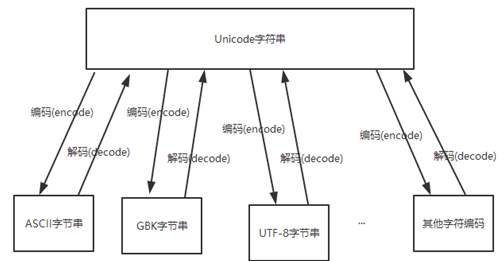
>>> hh = ‘hello 中国‘
>>> hh.encode(‘utf-8‘) #将‘hello 中国‘从unicode编码成utf-8
b‘hello \xe4\xb8\xad\xe5\x9b\xbd‘
>>> hh.encode(‘gbk‘) #将‘hello 中国‘从unicode编码成gbk
b‘hello \xd6\xd0\xb9\xfa‘
>>> hh.encode(‘ascii‘) #将‘hello 中国‘从unicode编码成ascii,但ascii不支持中文,因此出现异常
Traceback (most recent call last):
File "<pyshell#54>", line 1, in <module>
hh.encode(‘ascii‘)
UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 6-7: ordinal not in range(128)
>>> b‘hello \xe4\xb8\xad\xe5\x9b\xbd‘.decode(‘utf-8‘) #将其解码成Unicode,解码时告诉解码器自身是utf-8
‘hello 中国‘
>>> b‘hello \xe4\xb8\xad\xe5\x9b\xbd‘.decode(‘gbk‘) #将其解码成Unicode,解码时告诉解码器自身是gbk,但其并不是gbk而是utf-8,因此出现异常
Traceback (most recent call last):
File "<pyshell#58>", line 1, in <module>
b‘hello \xe4\xb8\xad\xe5\x9b\xbd‘.decode(‘gbk‘)
UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xad in position 8: illegal multibyte sequence
原文:https://www.cnblogs.com/maiblogs/p/14790911.html