def softmax2(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
这是深度学习鱼书上给的代码,当x是二维的时候

是把x转置,然后进行处理的,再往下的代码就很好理解了.
但是为什么要分两种情况处理呢,能不能将两种方式统一一下呢?
我修改之后是这样的
def softmax(x):
temp = np.max(x, axis=1)
temp = temp.reshape(temp.size, 1)
x = x - temp # 溢出对策
temp2 = np.sum(np.exp(x), axis=1)
temp2 = temp2.reshape(temp2.size, 1)
y = np.exp(x) / temp2
return y
的确这个修改后的softmax函数,可以求只有一行的x,或者是多行的x,但是发生了一点变化
对于二维没有变化,正确运行:

对于一维,传参时,会报错:
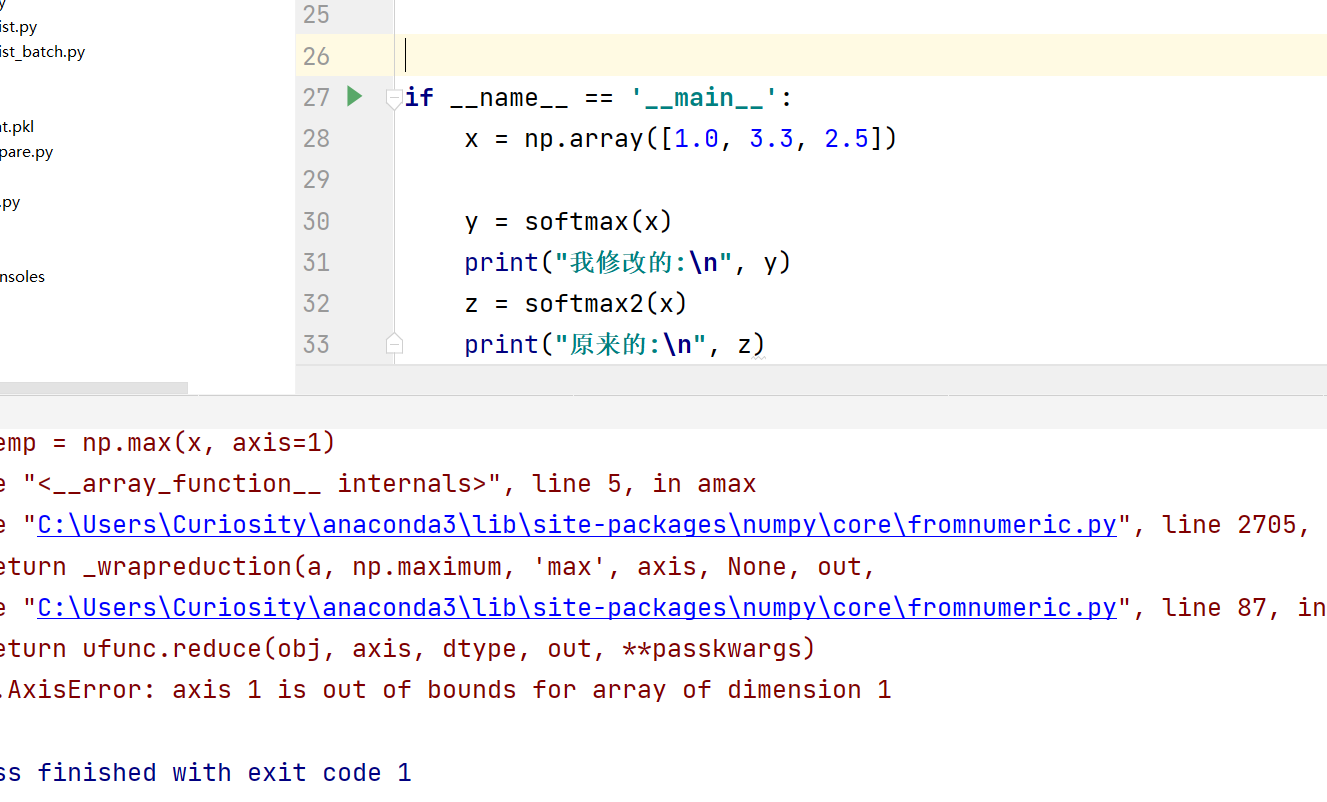
只有当参数修改为二维矩阵时,才能正确运行
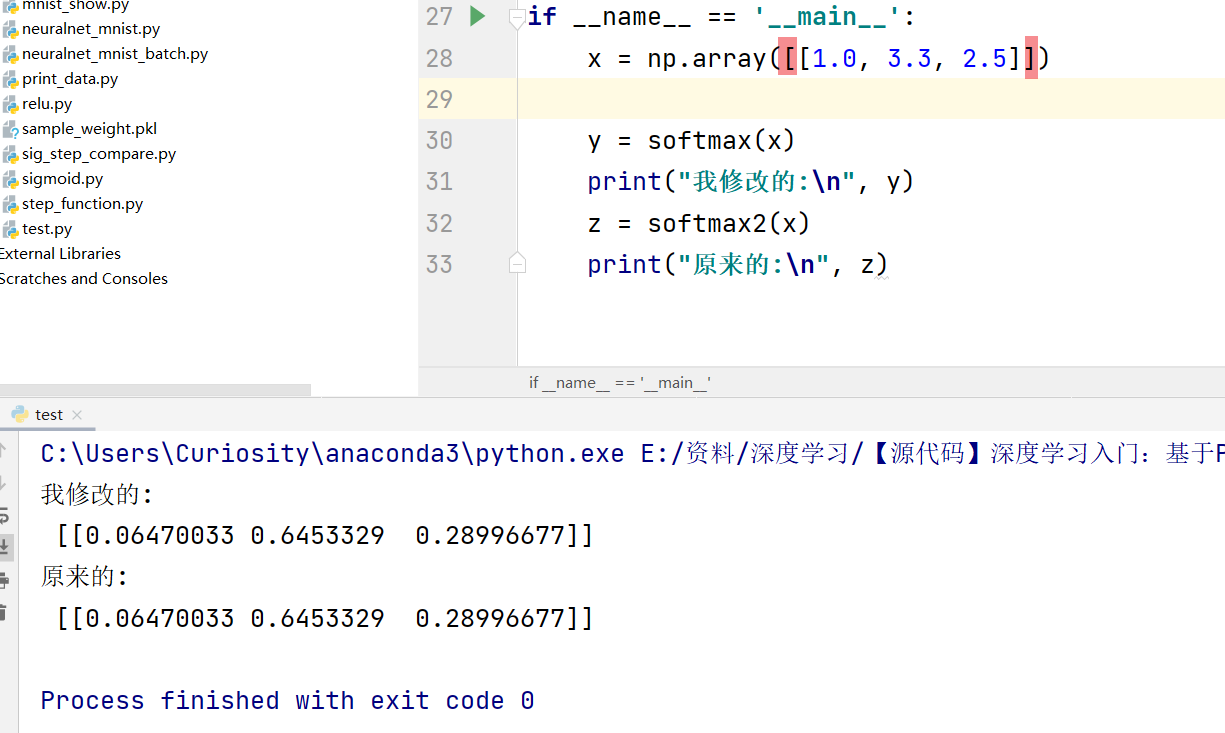
这说明, [1.3,2,5]和[[1.3,2,5]]是不一样的,一个是向量,一个是矩阵,(一个是一维,一个是二维),因此对于一下numpy函数的使用,会有差别.
原文:https://www.cnblogs.com/programmerwang/p/14772552.html