task1-1.py
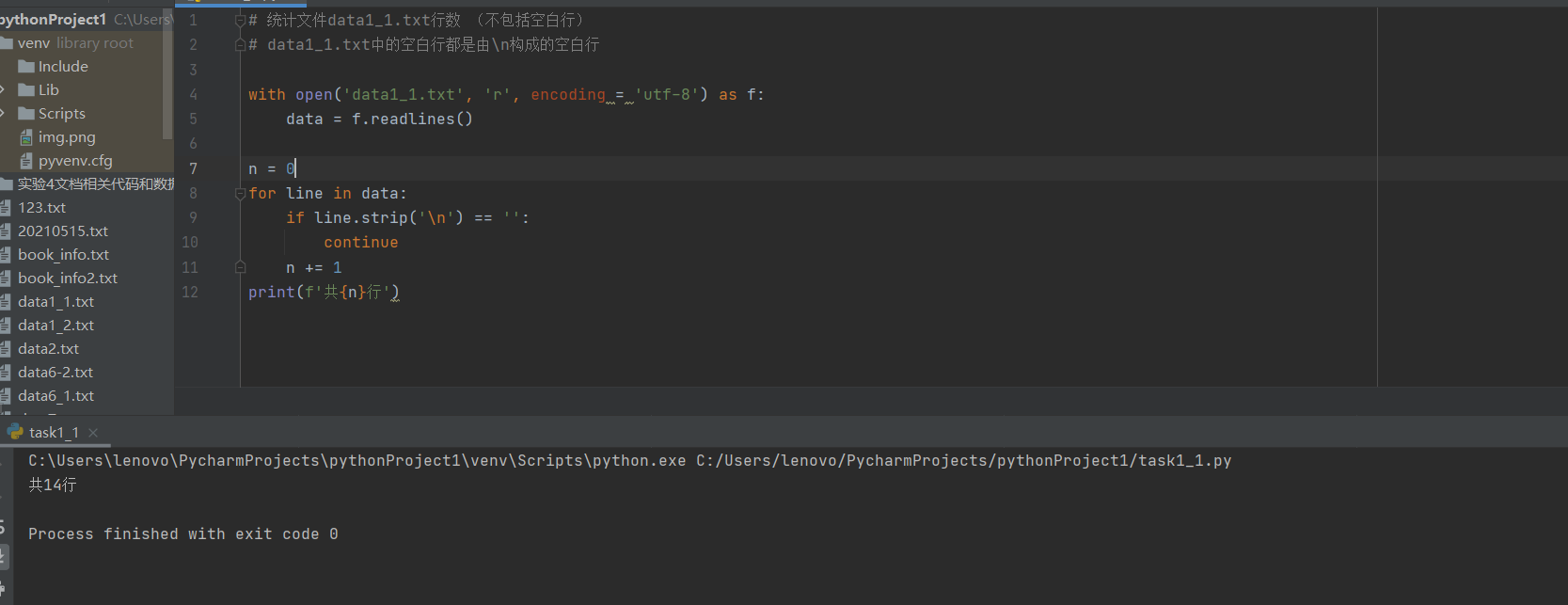
# 统计文件data1_1.txt行数 (不包括空白行) # data1_1.txt中的空白行都是由\n构成的空白行 with open(‘data1_1.txt‘, ‘r‘, encoding = ‘utf-8‘) as f: data = f.readlines() n = 0 for line in data: if line.strip(‘\n‘) == ‘‘: continue n += 1 print(f‘共{n}行‘)
task1-2.py
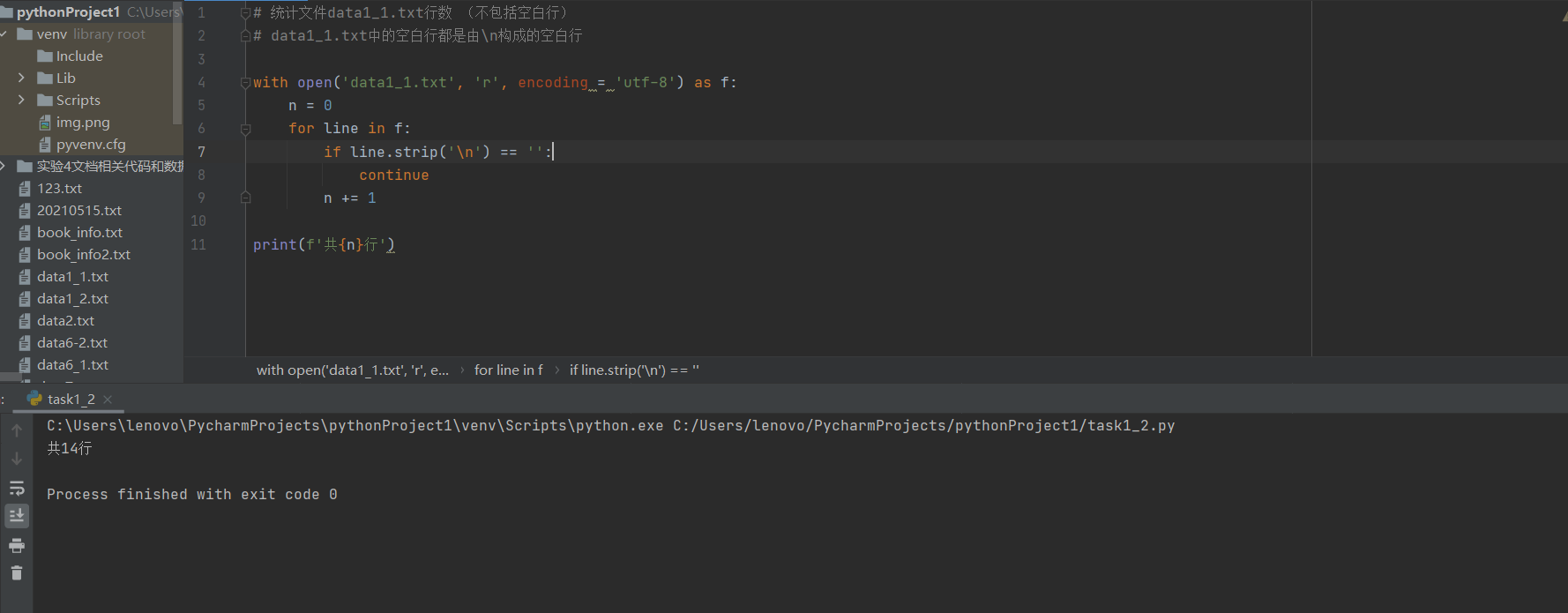
# 统计文件data1_1.txt行数 (不包括空白行) # data1_1.txt中的空白行都是由\n构成的空白行 with open(‘data1_1.txt‘, ‘r‘, encoding = ‘utf-8‘) as f: n = 0 for line in f: if line.strip(‘\n‘) == ‘‘: continue n += 1 print(f‘共{n}行‘)
task1-3.py
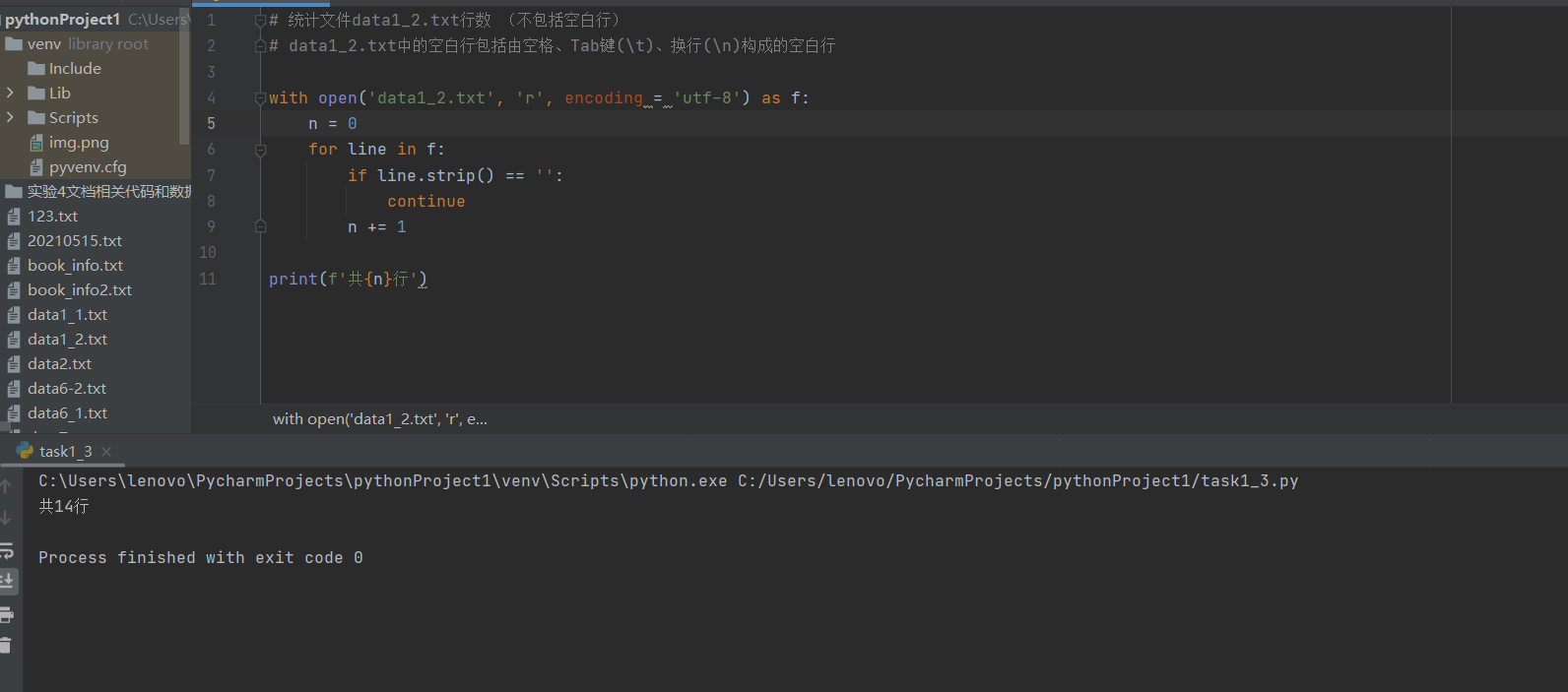
# 统计文件data1_2.txt行数 (不包括空白行) # data1_2.txt中的空白行包括由空格、Tab键(\t)、换行(\n)构成的空白行 with open(‘data1_2.txt‘, ‘r‘, encoding = ‘utf-8‘) as f: n = 0 for line in f: if line.strip() == ‘‘: continue n += 1 print(f‘共{n}行‘)
task1-4.py
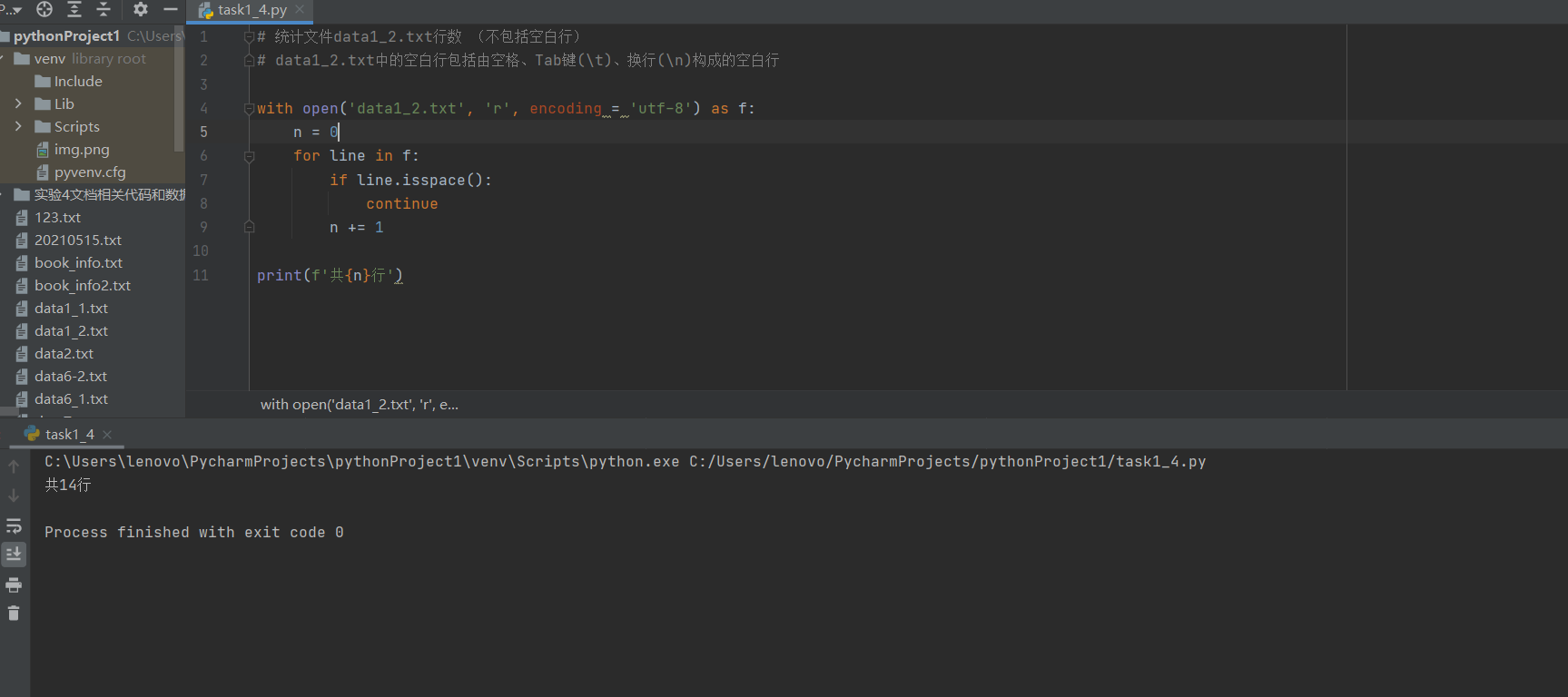
# 统计文件data1_2.txt行数 (不包括空白行) # data1_2.txt中的空白行包括由空格、Tab键(\t)、换行(\n)构成的空白行 with open(‘data1_2.txt‘, ‘r‘, encoding = ‘utf-8‘) as f: n = 0 for line in f: if line.isspace(): continue n += 1 print(f‘共{n}行‘)
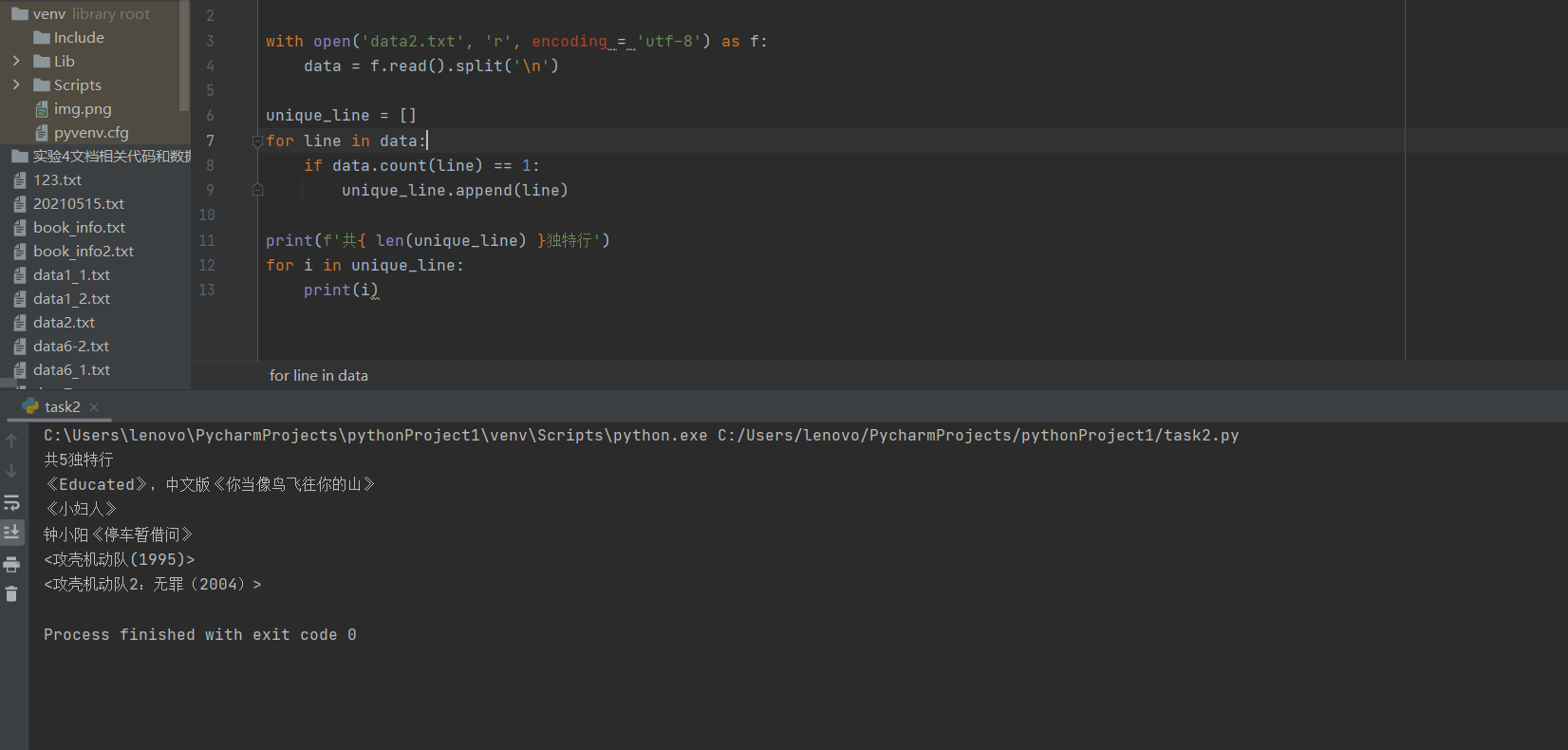
task2.py
# 统计其中只出现过一次的独特行行数,在屏幕上打印输出结果。 with open(‘data2.txt‘, ‘r‘, encoding = ‘utf-8‘) as f: data = f.read().split(‘\n‘) unique_line = [] for line in data: if data.count(line) == 1: unique_line.append(line) print(f‘共{ len(unique_line) }独特行‘) for i in unique_line: print(i)
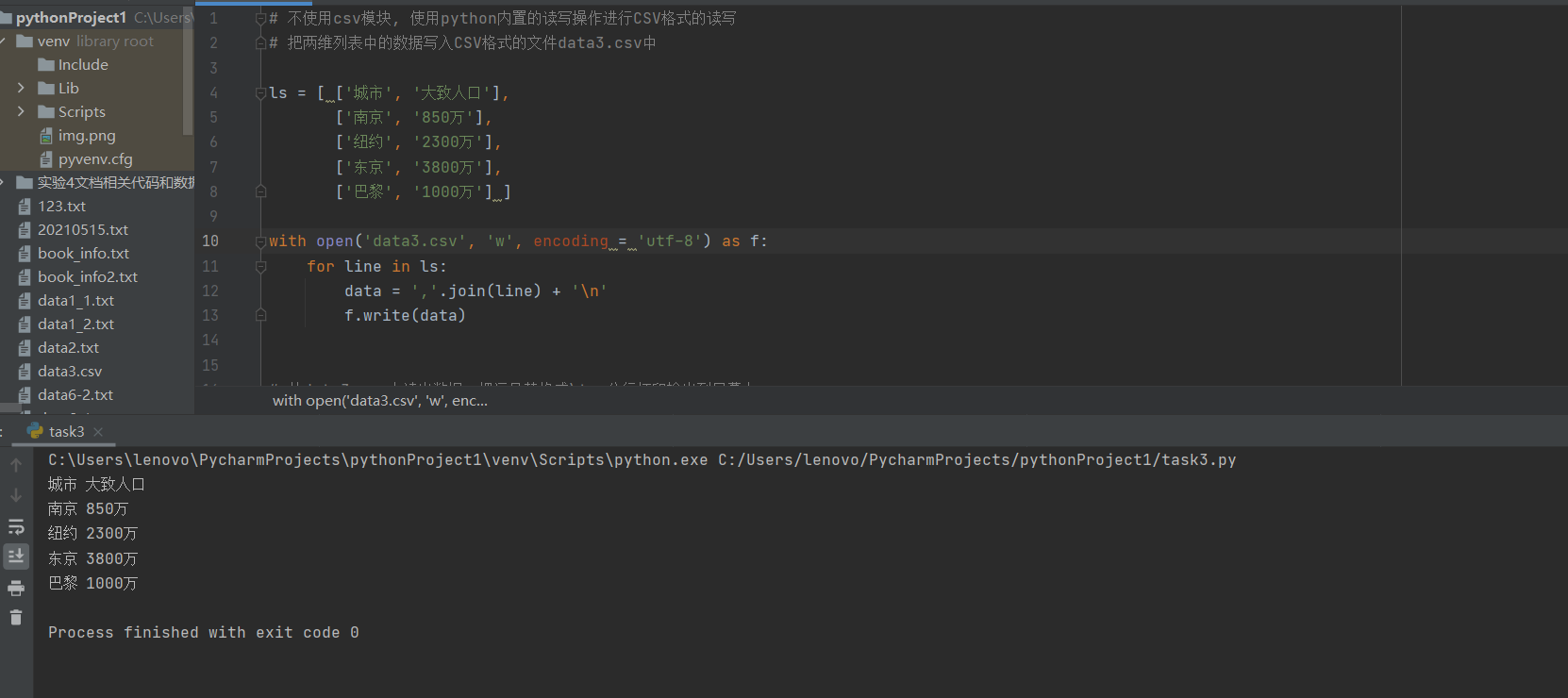
task3.py
# 不使用csv模块, 使用python内置的读写操作进行CSV格式的读写 # 把两维列表中的数据写入CSV格式的文件data3.csv中 ls = [ [‘城市‘, ‘大致人口‘], [‘南京‘, ‘850万‘], [‘纽约‘, ‘2300万‘], [‘东京‘, ‘3800万‘], [‘巴黎‘, ‘1000万‘] ] with open(‘data3.csv‘, ‘w‘, encoding = ‘utf-8‘) as f: for line in ls: data = ‘,‘.join(line) + ‘\n‘ f.write(data) # 从data3.csv中读出数据,把逗号替换成\t, 分行打印输出到屏幕上 with open(‘data3.csv‘, ‘r‘, encoding = ‘utf-8‘) as f: data = f.read() print(data.replace(‘,‘, ‘\t‘), end = ‘‘)
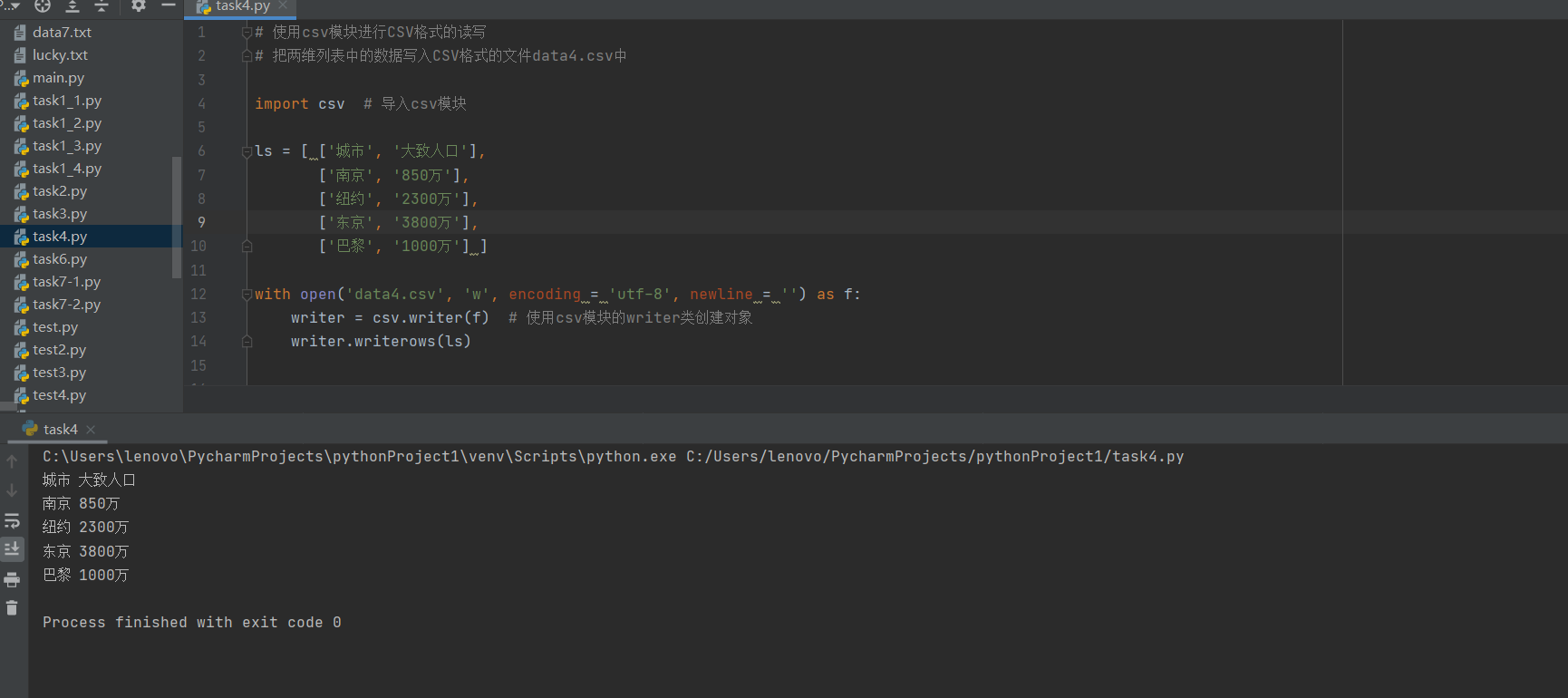
task4.py
# 使用csv模块进行CSV格式的读写 # 把两维列表中的数据写入CSV格式的文件data4.csv中 import csv # 导入csv模块 ls = [ [‘城市‘, ‘大致人口‘], [‘南京‘, ‘850万‘], [‘纽约‘, ‘2300万‘], [‘东京‘, ‘3800万‘], [‘巴黎‘, ‘1000万‘] ] with open(‘data4.csv‘, ‘w‘, encoding = ‘utf-8‘, newline = ‘‘) as f: writer = csv.writer(f) # 使用csv模块的writer类创建对象 writer.writerows(ls) # 从data4.csv中读出数据,把逗号替换成\t, 分行打印输出到屏幕上 with open(‘data4.csv‘, ‘r‘, encoding = ‘utf-8‘) as f: reader = csv.reader(f) # 使用csv模块的reader类创建对象 for line in reader: print(‘\t‘.join(line))
task5-1.py
task5-2.py
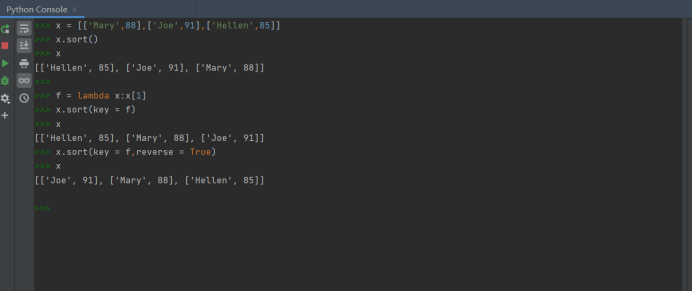
task6.py
with open(‘data6_1.txt‘,‘r‘,encoding=‘utf-8‘) as f: with open(‘data6-2.txt ‘,‘w‘,encoding=‘utf-8‘) as m: a = f.readlines() list1 = [] for line in a: b = line.strip(‘\n‘).split(‘\t‘) list1.append(b) c = lambda list1:list1[2] list1.sort(key = c,reverse = True) for i in list1: m.write(‘ ‘.join(i)+‘\n‘)
print(i)
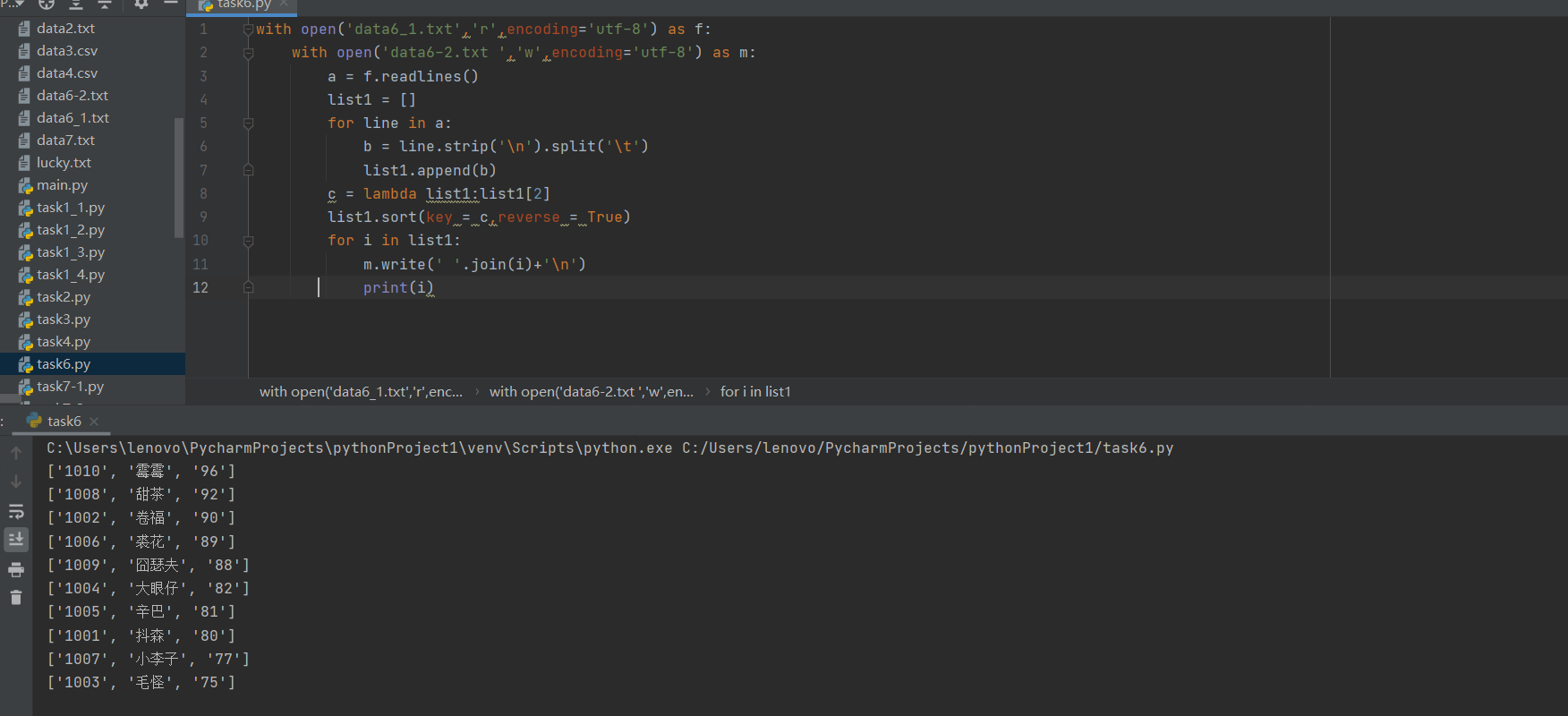

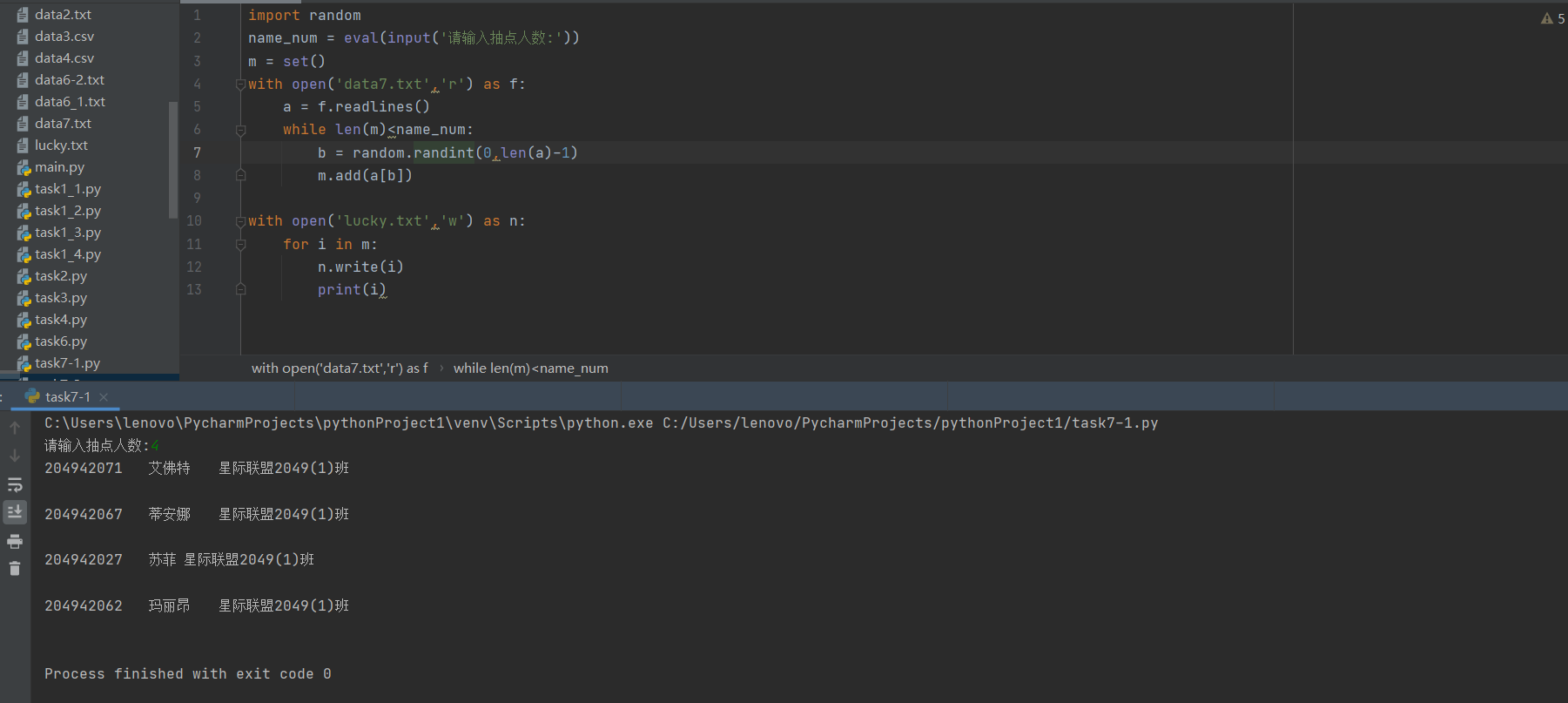
task7-1.py
import random name_num = eval(input(‘请输入抽点人数:‘)) m = set() with open(‘data7.txt‘,‘r‘) as f: a = f.readlines() while len(m)<name_num: b = random.randint(0,len(a)-1) m.add(a[b]) with open(‘lucky.txt‘,‘w‘) as n: for i in m: n.write(i) print(i)

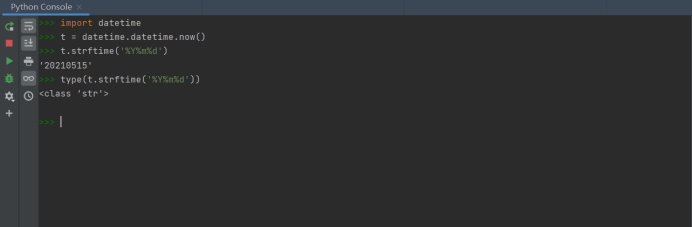
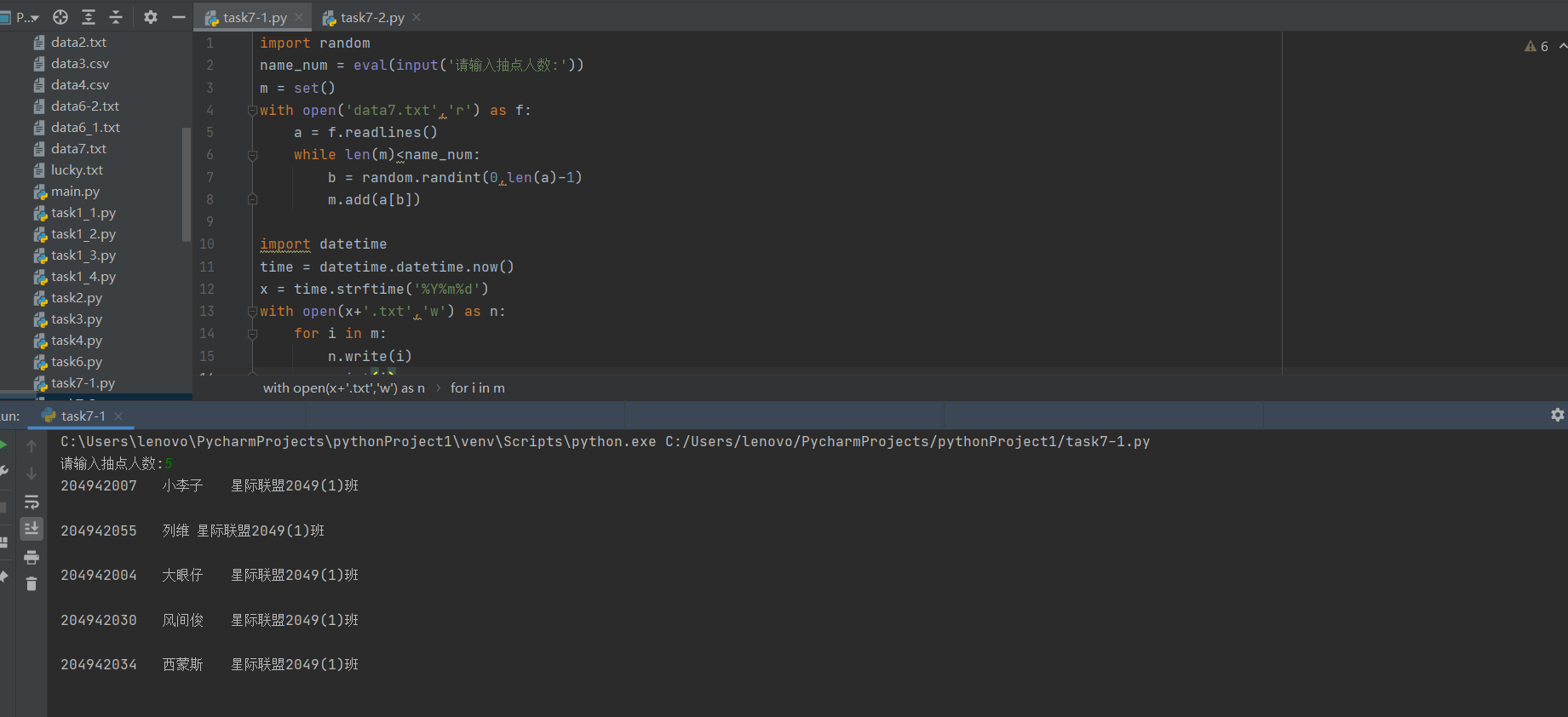
task7-2.py
import random name_num = eval(input(‘请输入抽点人数:‘)) m = set() with open(‘data7.txt‘,‘r‘) as f: a = f.readlines() while len(m)<name_num: b = random.randint(0,len(a)-1) m.add(a[b]) import datetime time = datetime.datetime.now() x = time.strftime(‘%Y%m%d‘) with open(x+‘.txt‘,‘w‘) as n: for i in m: n.write(i) print(i)
原文:https://www.cnblogs.com/fh123123/p/14772786.html