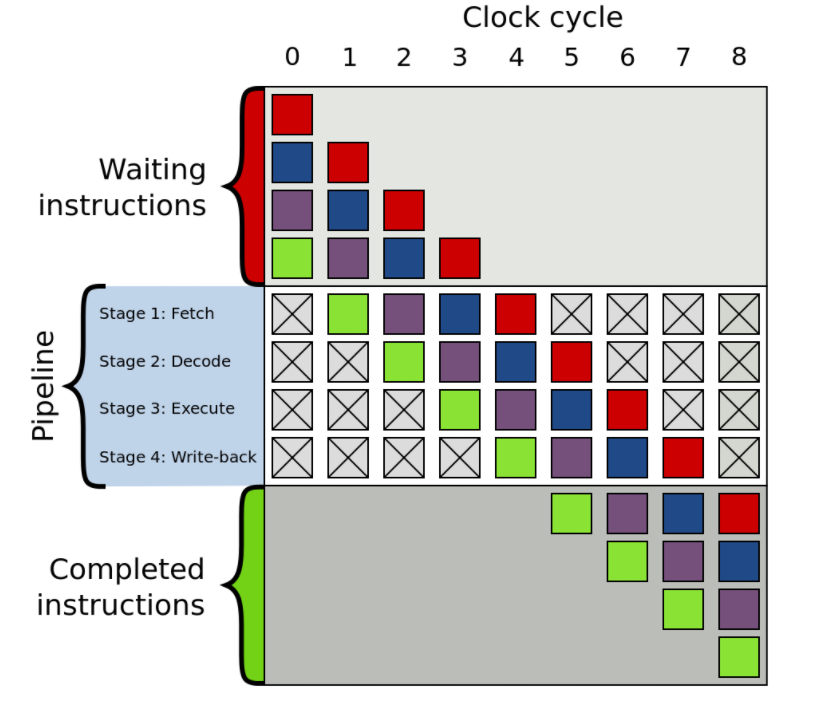
任何一条指令在CPU中的执行都必须经历如下这些步骤:
现代处理器使用流水线架构主要是为了提高程序执行效率,比如在第一条指令进入执行阶段时,第二条指令已经开始译码,第三条指令处于取指阶段……相对于第一条指令完全执行完并写回内存再开始第二条指令的取指,效率提高了很多倍。当然,现代处理器一般流水线深度高达10-31级,对程序执行速度有着显著提高
上述流水线架构对于顺序执行的命令,效果提高显著,但是遇到跳转命令时效率便会急剧下降,对于分支跳转指令,我们在执行完该指令之前是不知道是否发生跳转的,也就是说,我们在分支指令执行完之前,我们无法确定分支指令的下一条指令的地址,所以也就没法把分支指令的下一条命令放入流水线中,只能等待分支指令执行完毕才能开始下一条命令的取指步骤,所以流水线中就会出现气泡(Bubble),这会大大降低流水线的吞吐能力。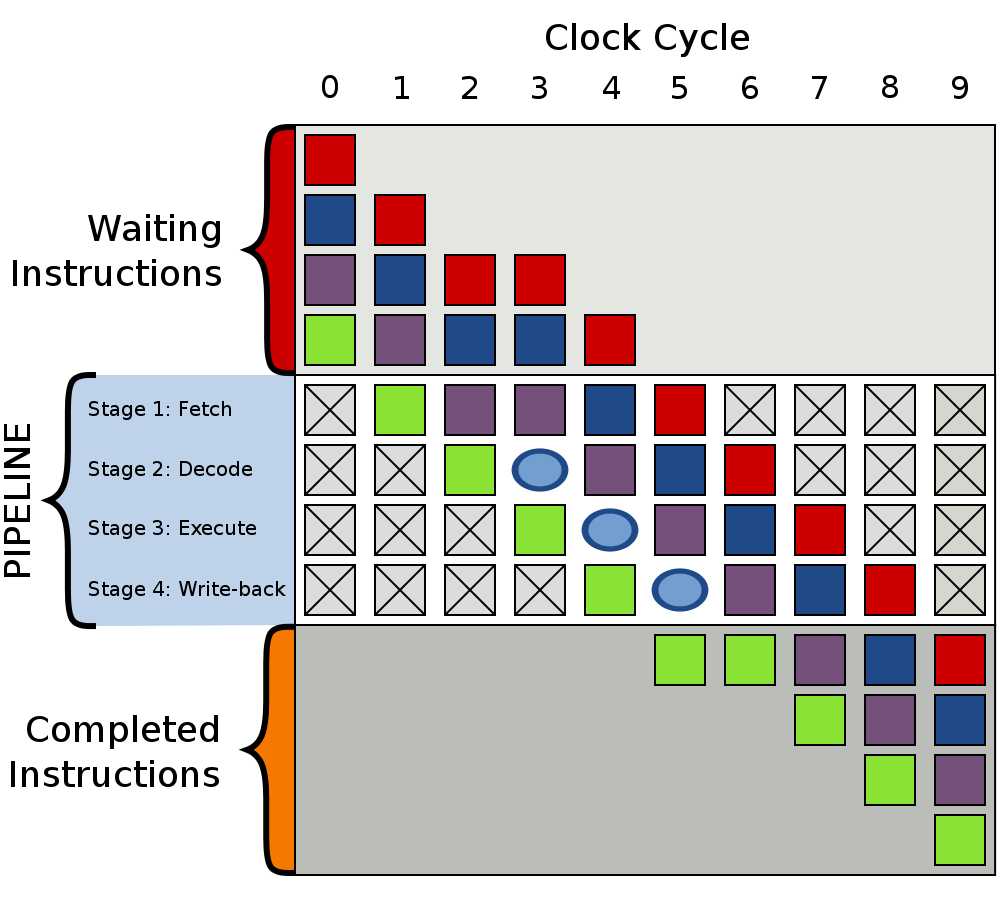
主要有两种方式来实现分支预测:静态和动态。
下面的C++代码经过编译器编译后生成的汇编代码是通过条件控制转移命令实现分支跳转的
for(unsigned c = 0; c < arraySize; ++c){ if(data[c] >= 128){ sum += data[c]; } }
for(unsigned c = 0; c < arraySize; ++c){ int t = (data[c] - 128) >> 31; sum += ~t & data[c]; }
空间开销
首先,由于需要为每一个包含虚函数的类生成一个虚函数表,所以程序的二进制文件大小会相应的增大;其次,对于包含虚函数的类的实例来说,每个实例都包含一个虚函数表指针用于指向对应的虚函数表,所以每个实例的空间占用都增加一个指针大小(32位系统4字节,64位系统8字节)。这些空间开销可能会造成缓存的不友好,在一定程度上影响程序性能。
时间开销
虚函数的时间开销主要是增加了一次内存寻址,通过虚函数表指针找到虚函数表,虽对程序性能有一些影响,但是影响并不大。
上述虚函数表面上的开销其实是微不足道的,真正影响虚函数性能的是隐藏在背后的,不被人轻易察觉的,只有对计算机体系结构有一定理解才能探寻出藏在背后的“性能杀手”。
首先我们先看调用虚函数时,在汇编层生成了什么代码:
... movq (%rax), %rax movq (%rax), %rax movq -24(%rbp), %rdx movq %rdx, %rdi call *%rax ...
上述汇编代码最重要的就是第6行,在AT&T格式汇编中,这是一个间接调用,意义是从%rax指明的地址处读取跳转的目标位置。这也是虚函数调用与普通成员函数的区别所在,普通函数调用是一个直接调用。直接调用与间接调用的区别就是跳转地址是否确定,直接调用的跳转地址是编译器确定的,而间接调用是运行到该指令时从寄存器中取出地址然后跳转。
有了分支预测器和CPU指令流水线的基本知识,我们可以发现对于直接调用而言,是不存在分支跳转的,因为跳转地址是编译器确定的,CPU直接去跳转地址取后面的指令即可,不存在分支预测,这样可以保证CPU流水线不被打断。而对于间接寻址,由于跳转地址不确定,所以此处会有多个分支可能,这个时候需要分支预测器进行预测,如果分支预测失败,则会导致流水线冲刷,重新进行取指、译码等操作,对程序性能有很大的影响。网上有部分文章中说对于虚函数这种间接跳转会直接导致流水线冲刷,这种说法明显是自相矛盾的,如果间接跳转必定会导致流水线冲刷,那把这些指令放进流水线的意义何在呢?其实查阅资料就可以知道,Intel和AMD的CPU中存在两级自适应预测器用于预测间接跳转,此预测器可以预测多分支跳转。
原文:http://irootlee.com/juicer_vtable/
原文:https://www.cnblogs.com/hxl-learning-space/p/14735368.html