本文代码来自于官方示例。
此例演示的是配置客户端的传输Transport。
类例中的配置主要用于说明其作用,不适用于生产环境。
默认的传输就够用了。
package main
import (
"github.com/elastic/go-elasticsearch/v8"
)
func main() {
cfg := elasticsearch.Config{
Addresses: []string{"http://localhost:9200"},
Transport: &http.Transport{
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Millisecond,
DialContext: (&net.Dialer{Timeout: time.Nanosecond}).DialContext,
TLSClientConfig: &tls.Config{
MinVersion: tls.VersionTLS11,
},
},
}
es, err := elasticsearch.NewClient(cfg)
if err != nil {
panic(err)
}
resp, err := es.Info()
if err != nil {
panic(err)
}
fmt.Println(resp)
// => panic: dial tcp: i/o timeout
}
自定义传输用于读取或操作请求和响应,自定义日志记录,将自定义 header 传递给请求等。
CountingTransport将自定义 header 添加到请求,记录有关请求和响应的信息,并统计请求次数。
由于它实现了http.RoundTripper接口,因此可以将其作为自定义 HTTP 传输实现传递给客户端。
type CountingTransport struct {
count uint64
}
// RoundTrip 发送一个请求,返回一个响应
func (t *CountingTransport) RoundTrip(req *http.Request) (*http.Response, error) {
var buf bytes.Buffer
atomic.AddUint64(&t.count, 1)
req.Header.Set("Accept", "application/yaml")
req.Header.Set("X-Request-ID", "foo-123")
res, err := http.DefaultTransport.RoundTrip(req)
buf.WriteString(strings.Repeat("-", 80) + "\n")
fmt.Fprintf(&buf, "%s %s", req.Method, req.URL.String())
if err != nil {
fmt.Fprintf(&buf, "ERROR: %s\n", err)
} else {
fmt.Fprintf(&buf, "[%s] %s\n", res.Status, res.Header.Get("Content-Type"))
}
buf.WriteTo(os.Stdout)
return res, err
}
func main() {
var wg sync.WaitGroup
// 创建一个自定义传输
tp := new(CountingTransport)
// 将自定义传输放到客户端配置中
es, _ := elasticsearch.NewClient(elasticsearch.Config{Transport: tp})
for i := 0; i < 25; i++ {
wg.Add(1)
go func() {
defer wg.Done()
es.Info()
}()
}
wg.Wait()
fmt.Println(strings.Repeat("=", 80))
fmt.Printf("%80s\n", fmt.Sprintf("Total Requests: %d", atomic.LoadUint64(&tp.count)))
}
默认日志有以下四种:
func main() {
log.SetFlags(0)
var es *elasticsearch.Client
es, _ = elasticsearch.NewClient(elasticsearch.Config{
Logger: &estransport.TextLogger{Output: os.Stdout},
})
run(es, "Text")
es, _ = elasticsearch.NewClient(elasticsearch.Config{
Logger: &estransport.ColorLogger{Output: os.Stdout},
})
run(es, "Color")
es, _ = elasticsearch.NewClient(elasticsearch.Config{
Logger: &estransport.ColorLogger{
Output: os.Stdout,
EnableRequestBody: true,
EnableResponseBody: true,
},
})
run(es, "Request/Response body")
es, _ = elasticsearch.NewClient(elasticsearch.Config{
Logger: &estransport.CurlLogger{
Output: os.Stdout,
EnableRequestBody: true,
EnableResponseBody: true,
},
})
run(es, "Curl")
es, _ = elasticsearch.NewClient(elasticsearch.Config{
Logger: &estransport.JSONLogger{
Output: os.Stdout,
},
})
run(es, "JSON")
}
func run(es *elasticsearch.Client, name string) {
log.Println("███", fmt.Sprintf("\x1b[1m%s\x1b[0m", name), strings.Repeat("█", 75-len(name)))
es.Delete("test", "1")
es.Exists("test", "1")
es.Index(
"test",
strings.NewReader(`{"title": "logging"}`),
es.Index.WithRefresh("true"),
es.Index.WithPretty(),
es.Index.WithFilterPath("result", "_id"),
)
es.Search(es.Search.WithQuery("{FAIL"))
res, err := es.Search(
es.Search.WithIndex("test"),
es.Search.WithBody(strings.NewReader(`{"query": {"match": {"title": "logging"}}}`)),
es.Search.WithSize(1),
es.Search.WithPretty(),
es.Search.WithFilterPath("took", "hits.hits"),
)
s := res.String()
if len(s) <= len("[200 OK] ") {
log.Fatal("Response body is empty")
}
if err != nil {
log.Fatalf("Error: %s", err)
}
log.Println()
}
四种日志的用途:
TextLogger:将请求和响应的基本信息以明文的形式输出ColorLogger:在开发时能在终端将一些信息以不同颜色输出CurlLogger:将信息格式化为可运行的curl命令,当启用EnableResponseBody时会美化输出JSONLogger:将信息以 json 格式输出,适用于生产环境的日志如果要记录请求和响应的 body 内容,需要开启对应的选项:
EnableRequestBody:记录请求体EnableResponseBody:记录响应体根据estransport.Logger接口,实现自定义日志。
日志包使用rs/zerolog。
package main
import (
"github.com/rs/zerolog"
)
// CustomLogger 实现 estransport.Logger 接口
type CustomLogger struct {
zerolog.Logger
}
// LogRoundTrip 打印请求和响应的一些信息
func (l *CustomLogger) LogRoundTrip(
req *http.Request,
res *http.Response,
err error,
start time.Time,
dur time.Duration,
) error {
var (
e *zerolog.Event
nReq int64
nRes int64
)
// 设置日志等级
switch {
case err != nil:
e = l.Error()
case res != nil && res.StatusCode > 0 && res.StatusCode < 300:
e = l.Info()
case res != nil && res.StatusCode > 299 && res.StatusCode < 500:
e = l.Warn()
case res != nil && res.StatusCode > 499:
e = l.Error()
default:
e = l.Error()
}
// 计算请求体和响应体的字节数
if req != nil && req.Body != nil && req.Body != http.NoBody {
nReq, _ = io.Copy(ioutil.Discard, req.Body)
}
if res != nil && res.Body != nil && res.Body != http.NoBody {
nRes, _ = io.Copy(ioutil.Discard, res.Body)
}
// 日志事件
e.Str("method", req.Method).
Int("status_code", res.StatusCode).
Dur("duration", dur).
Int64("req_bytes", nReq).
Int64("res_bytes", nRes).
Msg(req.URL.String())
return nil
}
// RequestBodyEnabled 输出请求体
func (l *CustomLogger) RequestBodyEnabled() bool { return true }
// ResponseBodyEnabled 输出响应体
func (l *CustomLogger) ResponseBodyEnabled() bool { return true }
func main() {
// 设置日志
log := zerolog.New(zerolog.ConsoleWriter{Out: os.Stderr}).
Level(zerolog.InfoLevel).
With().
Timestamp().
Logger()
// 客户端使用自定义的日志
es, _ := elasticsearch.NewClient(elasticsearch.Config{
Logger: &CustomLogger{log},
})
{
es.Delete("test", "1")
es.Exists("test", "1")
es.Index("test", strings.NewReader(`{"title": "logging"}`), es.Index.WithRefresh("true"))
es.Search(
es.Search.WithQuery("{FAIL"),
)
es.Search(
es.Search.WithIndex("test"),
es.Search.WithBody(strings.NewReader(`{"query": {"match": {"title": "logging"}}}`)),
es.Search.WithSize(1),
)
}
}
结果如图:

此示例有意不使用任何抽象或辅助功能来展示使用 bulk api 的低级机制:准备元数据有效载荷,批量发送有效载荷,检查错误结果并打印报告。
请看代码注释:
package main
import (
"github.com/dustin/go-humanize"
"github.com/elastic/go-elasticsearch/v8"
"github.com/elastic/go-elasticsearch/v8/esapi"
)
type Article struct {
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
Published time.Time `json:"published"`
Author Author `json:"author"`
}
type Author struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
}
var (
_ = fmt.Print
count int
batch int
)
func init() {
flag.IntVar(&count, "count", 1000, "生成的文档数量")
flag.IntVar(&batch, "batch", 255, "每次发送的文档数量")
flag.Parse()
rand.Seed(time.Now().UnixNano())
}
func main() {
log.SetFlags(0)
type bulkResponse struct {
Errors bool `json:"errors"`
Items []struct {
Index struct {
ID string `json:"_id"`
Result string `json:"result"`
Status int `json:"status"`
Error struct {
Type string `json:"type"`
Reason string `json:"reason"`
Cause struct {
Type string `json:"type"`
Reason string `json:"reason"`
} `json:"caused_by"`
} `json:"error"`
} `json:"index"`
} `json:"items"`
}
var (
buf bytes.Buffer
res *esapi.Response
err error
raw map[string]interface{}
blk *bulkResponse
articles []*Article
indexName = "articles"
numItems int
numErrors int
numIndexed int
numBatches int
currBatch int
)
log.Printf(
"\x1b[1mBulk\x1b[0m: documents [%s] batch size [%s]",
humanize.Comma(int64(count)), humanize.Comma(int64(batch)))
log.Println(strings.Repeat("_", 65))
// 创建客户端
es, err := elasticsearch.NewDefaultClient()
if err != nil {
panic(err)
}
// 生成文章
names := []string{"Alice", "John", "Mary"}
for i := 1; i < count+1; i++ {
articles = append(articles, &Article{
ID: i,
Title: strings.Join([]string{"Title", strconv.Itoa(i)}, " "),
Body: "Lorem ipsum dolor sit amet...",
Published: time.Now().Round(time.Second).Local().AddDate(0, 0, i),
Author: Author{
FirstName: names[rand.Intn(len(names))],
LastName: "Smith",
},
})
}
log.Printf("→ Generated %s articles", humanize.Comma(int64(len(articles))))
fmt.Println("→ Sending batch ")
// 重新创建索引
if res, err = es.Indices.Delete([]string{indexName}); err != nil {
log.Fatalf("Cannot delete index: %s", err)
}
res, err = es.Indices.Create(indexName)
if err != nil {
log.Fatalf("Cannot create index: %s", err)
}
if res.IsError() {
log.Fatalf("Cannot create index: %s", res)
}
if count%batch == 0 {
numBatches = count / batch
} else {
numBatches = count/batch + 1
}
start := time.Now().Local()
// 循环收集
for i, a := range articles {
numItems++
currBatch = i / batch
if i == count-1 {
currBatch++
}
// 准备元数据有效载荷
meta := []byte(fmt.Sprintf(`{ "index" : { "_id" : "%d" } }%s`, a.ID, "\n"))
// 准备 data 有效载荷:序列化后的 article
data, err := json.Marshal(a)
if err != nil {
log.Fatalf("Cannot encode article %d: %s", a.ID, err)
}
// 在 data 载荷中添加一个换行符
data = append(data, "\n"...)
// 将载荷添加到 buf 中
buf.Grow(len(meta) + len(data))
buf.Write(meta)
buf.Write(data)
// 达到阈值时,使用 buf 中的数据(请求体)执行 Bulk() 请求
if i > 0 && i%batch == 0 || i == count-1 {
fmt.Printf("[%d/%d] ", currBatch, numBatches)
// 每 batch(本例中是255)个为一组发送
res, err = es.Bulk(bytes.NewReader(buf.Bytes()), es.Bulk.WithIndex(indexName))
if err != nil {
log.Fatalf("Failur indexing batch %d: %s", currBatch, err)
}
// 如果整个请求失败,打印错误并标记所有文档都失败
if res.IsError() {
numErrors += numItems
if err := json.NewDecoder(res.Body).Decode(&raw); err != nil {
log.Fatalf("Failure to parse response body: %s", err)
} else {
log.Printf(" Error: [%d] %s: %s",
res.StatusCode,
raw["error"].(map[string]interface{})["type"],
raw["error"].(map[string]interface{})["reason"],
)
}
} else { // 一个成功的响应也可能因为一些特殊文档包含一些错误
if err := json.NewDecoder(res.Body).Decode(&blk); err != nil {
log.Fatalf("Failure to parse response body: %s", err)
} else {
for _, d := range blk.Items {
// 对件何状态码大于 201 的请求进行处理
if d.Index.Status > 201 {
numErrors++
log.Printf(" Error: [%d]: %s: %s: %s: %s",
d.Index.Status,
d.Index.Error.Type,
d.Index.Error.Reason,
d.Index.Error.Cause.Type,
d.Index.Error.Cause.Reason,
)
} else {
// 如果状态码小于等于 201,对成功的计数器 numIndexed 加 1
numIndexed++
}
}
}
}
// 关闭响应体,防止达到 Goroutines 或文件句柄限制
res.Body.Close()
// 重置 buf 和 items 计数器
buf.Reset()
numItems = 0
}
}
// 报告结果:索引成功的文档的数量,错误的数量,耗时,索引速度
fmt.Println()
log.Println(strings.Repeat("▔", 65))
dur := time.Since(start)
if numErrors > 0 {
log.Fatalf(
"Indexed [%s] documents with [%s] errors in %s (%s docs/sec)",
humanize.Comma(int64(numIndexed)),
humanize.Comma(int64(numErrors)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(numIndexed))),
)
} else {
log.Printf(
"Successfuly indexed [%s] documents in %s (%s docs/sec)",
humanize.Comma(int64(numIndexed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(numIndexed))),
)
}
}
count和batch为可选参数,在执行时可以自定义:
? go run main.go -count=100000 -batch=25000
Bulk: documents [100,000] batch size [25,000]
▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
→ Generated 100,000 articles
→ Sending batch
[1/4] [2/4] [3/4] [4/4]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Successfuly indexed [100,000] documents in 2.79s (35,842 docs/sec)
此例演示使用esutil.BulkIndexer帮助程序来索引文档。
package main
import (
"github.com/dustin/go-humanize"
"github.com/cenkalti/backoff/v4"
"github.com/elastic/go-elasticsearch/v8"
"github.com/elastic/go-elasticsearch/v8/esapi"
"github.com/elastic/go-elasticsearch/v8/esutil"
)
type Article struct {
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
Published time.Time `json:"published"`
Author Author `json:"author"`
}
type Author struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
}
var (
indexName string
numWorkers int
flushBytes int
numItems int
)
func init() {
flag.StringVar(&indexName, "index", "test-bulk-example", "索引名称")
flag.IntVar(&numWorkers, "workers", runtime.NumCPU(), "工作进程数量")
flag.IntVar(&flushBytes, "flush", 5e+6, "以字节为单位的清除阈值")
flag.IntVar(&numItems, "count", 10000, "生成的文档数量")
flag.Parse()
rand.Seed(time.Now().UnixNano())
}
func main() {
log.SetFlags(0)
var (
articles []*Article
countSuccessful uint64
res *esapi.Response
err error
)
log.Printf(
"\x1b[1mBulkIndexer\x1b[0m: documents [%s] workers [%d] flush [%s]",
humanize.Comma(int64(numItems)), numWorkers, humanize.Bytes(uint64(flushBytes)))
log.Println(strings.Repeat("▁", 65))
// 使用第三方包来实现回退功能
retryBackoff := backoff.NewExponentialBackOff()
// 创建客户端。如果想使用最佳性能,请考虑使用第三方 http 包,benchmarks 示例中有写
es, err := elasticsearch.NewClient(elasticsearch.Config{
// 429 太多请求
RetryOnStatus: []int{502, 503, 504, 429},
// 配置回退函数
RetryBackoff: func(attempt int) time.Duration {
if attempt == 1 {
retryBackoff.Reset()
}
return retryBackoff.NextBackOff()
},
// 最多重试 5 次
MaxRetries: 5,
})
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
// 创建批量索引器。要使用最佳性能,考虑使用第三方 json 包,benchmarks 示例中有写
bi, err := esutil.NewBulkIndexer(esutil.BulkIndexerConfig{
Index: indexName, // 默认索引名
Client: es, // es 客户端
NumWorkers: numWorkers, // 工作进程数量
FlushBytes: int(flushBytes), // 清除上限
FlushInterval: 30 * time.Second, // 定期清除间隔
})
if err != nil {
log.Fatalf("Error creating the indexer: %s", err)
}
// 生成文章
names := []string{"Alice", "John", "Mary"}
for i := 1; i <= numItems; i++ {
articles = append(articles, &Article{
ID: i,
Title: strings.Join([]string{"Title", strconv.Itoa(i)}, " "),
Body: "Lorem ipsum dolor sit amet...",
Published: time.Now().Round(time.Second).UTC().AddDate(0, 0, i),
Author: Author{
FirstName: names[rand.Intn(len(names))],
LastName: "Smith",
},
})
}
log.Printf("→ Generated %s articles", humanize.Comma(int64(len(articles))))
// 重新创建索引
if res, err = es.Indices.Delete([]string{indexName}, es.Indices.Delete.WithIgnoreUnavailable(true)); err != nil || res.IsError() {
log.Fatalf("Cannot delete index: %s", err)
}
res.Body.Close()
res, err = es.Indices.Create(indexName)
if err != nil {
log.Fatalf("Cannot create index: %s", err)
}
if res.IsError() {
log.Fatalf("Cannot create index: %s", res)
}
res.Body.Close()
start := time.Now().UTC()
// 循环收集
for _, a := range articles {
// 准备 data:序列化的 article
data, err := json.Marshal(a)
if err != nil {
log.Fatalf("Cannot encode article %d: %s", a.ID, err)
}
// 添加 item 到 BulkIndexer
err = bi.Add(
context.Background(),
esutil.BulkIndexerItem{
// Action 字段配置要执行的操作(索引、创建、删除、更新)
Action: "index",
// DocumentID 是文档 ID(可选)
DocumentID: strconv.Itoa(a.ID),
// Body 是 有效载荷的 io.Reader
Body: bytes.NewReader(data),
// OnSuccess 在每一个成功的操作后调用
OnSuccess: func(c context.Context, bii esutil.BulkIndexerItem, biri esutil.BulkIndexerResponseItem) {
atomic.AddUint64(&countSuccessful, 1)
},
// OnFailure 在每一个失败的操作后调用
OnFailure: func(c context.Context, bii esutil.BulkIndexerItem, biri esutil.BulkIndexerResponseItem, e error) {
if err != nil {
log.Printf("ERROR: %s", err)
} else {
log.Printf("ERROR: %s: %s", biri.Error.Type, biri.Error.Reason)
}
},
},
)
if err != nil {
log.Fatalf("Unexpected error: %s", err)
}
}
// 关闭索引器
if err := bi.Close(context.Background()); err != nil {
log.Fatalf("Unexpected error: %s", err)
}
biStats := bi.Stats()
// 报告结果:索引成功的文档的数量,错误的数量,耗时,索引速度
log.Println(strings.Repeat("▔", 65))
dur := time.Since(start)
if biStats.NumFailed > 0 {
log.Fatalf(
"Indexed [%s] documents with [%s] errors in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
humanize.Comma(int64(biStats.NumFailed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
} else {
log.Printf(
"Sucessfuly indexed [%s] documents in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
}
}
四个可选参数,见init()函数:
? bulk go run indexer.go --workers=8 --count=100000 --flush=1000000
BulkIndexer: documents [100,000] workers [8] flush [1.0 MB]
▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
→ Generated 100,000 articles
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Sucessfuly indexed [100,000] documents in 1.584s (63,131 docs/sec)
本示例中演示了如何使用 helper 方法和第三方 json 库。
tidwall/gjsongithub.com/tidwall/gjson库允许在不将有效载荷转换为数据结构的前提下轻松访问属性。
package main
import (
"github.com/elastic/go-elasticsearch/v8"
"github.com/fatih/color"
"github.com/tidwall/gjson"
)
var (
faint = color.New(color.Faint)
bold = color.New(color.Bold)
)
func init() {
log.SetFlags(0)
}
func main() {
es, err := elasticsearch.NewDefaultClient()
if err != nil {
log.Fatalf("Error creating client: %s", err)
}
res, err := es.Cluster.Stats(es.Cluster.Stats.WithHuman())
if err != nil {
log.Fatalf("Error getting response: %s", err)
}
defer res.Body.Close()
json := read(res.Body)
fmt.Println(strings.Repeat("-", 50))
faint.Print("cluster ")
// 获取集群名
bold.Print(gjson.Get(json, "cluster_name"))
faint.Print(" status=")
// 获取集群健康状态
status := gjson.Get(json, "status")
switch status.Str {
case "green":
bold.Add(color.FgHiGreen).Print(status)
case "yellow":
bold.Add(color.FgHiYellow).Print(status)
case "red":
bold.Add(color.FgHiRed).Print(status)
default:
bold.Add(color.FgHiRed, color.Underline).Print(status)
}
fmt.Println("\n" + strings.Repeat("-", 50))
stats := []string{
"indices.count",
"indices.docs.count",
"indices.store.size",
"nodes.count.total",
"nodes.os.mem.used_percent",
"nodes.process.cpu.percent",
"nodes.jvm.versions.#.version",
"nodes.jvm.mem.heap_used",
"nodes.jvm.mem.heap_max",
"nodes.fs.free",
}
var maxWidth int
for _, item := range stats {
if len(item) > maxWidth {
maxWidth = len(item)
}
}
for _, item := range stats {
pad := maxWidth - len(item)
fmt.Print(strings.Repeat(" ", pad))
faint.Printf("%s |", item)
// 从 json 动态获取状态
fmt.Printf(" %s\n", gjson.Get(json, item))
}
fmt.Println()
}
func read(r io.Reader) string {
var b bytes.Buffer
b.ReadFrom(r)
return b.String()
}
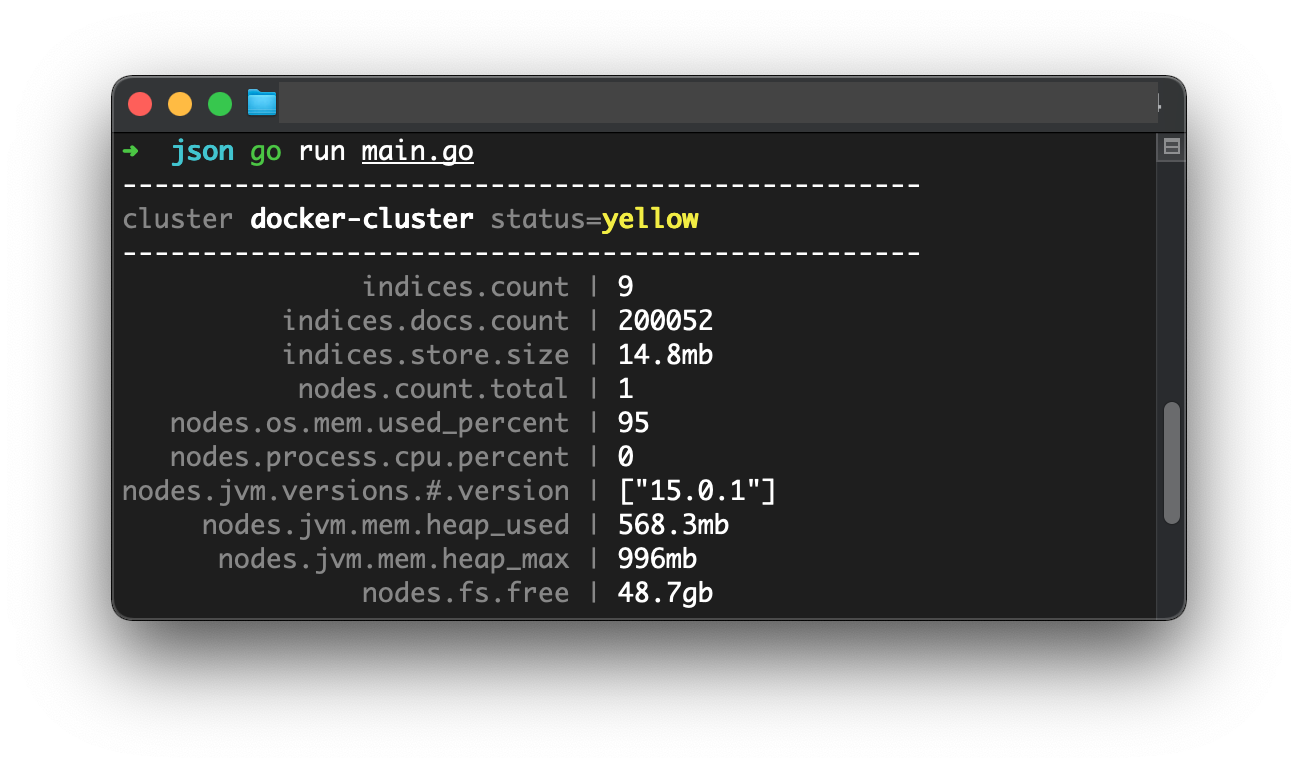
go run main.go
mailru/easyjsonmailru/easyjson可以用提供的结构体生成编码和解码的代码。
示例项目结构不适合在此处展示,故另写一篇文章,请参阅:Elasticsearch 的 easyjson 示例
JSONReaderesutil.JSONReader()方法将 struct、map 或任何其他可序列化对象转换为封装在 reader 中的 JSON,然后将其传递给WithBody()方法:
type Document struct{ Title string }
doc := Document{Title: "Test"}
es.Search(es.Search.WithBody(esutil.NewJSONReader(&doc)))
完整示例:
package main
import (
"github.com/elastic/go-elasticsearch/v8"
"github.com/elastic/go-elasticsearch/v8/esapi"
"github.com/elastic/go-elasticsearch/v8/esutil"
)
func init() {
log.SetFlags(0)
}
func main() {
var (
res *esapi.Response
err error
)
es, err := elasticsearch.NewDefaultClient()
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
doc := struct {
Title string `json:"title"`
}{Title: "Test"}
res, err = es.Index("test", esutil.NewJSONReader(&doc), es.Index.WithRefresh("true"))
if err != nil {
log.Fatalf("Error getting response: %s", err)
}
log.Println(res)
query := map[string]interface{}{
"query": map[string]interface{}{
"match": map[string]interface{}{
"title": "test",
},
},
}
res, err = es.Search(
es.Search.WithIndex("test"),
es.Search.WithBody(esutil.NewJSONReader(&query)),
es.Search.WithPretty(),
)
if err != nil {
log.Fatalf("Error getting response: %s", err)
}
log.Println(res)
}
运行结果:
[201 Created] {"_index":"test","_type":"_doc","_id":"4l7aG3kBuWpKCVVn78cc","_version":1,"result":"created","forced_refresh":true,"_shards":{"total":2,"successful":1,"failed":0},"_seq_no":28,"_primary_term":4}
[200 OK] {
"took" : 18,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.3671236,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "4l7aG3kBuWpKCVVn78cc",
"_score" : 2.3671236,
"_source" : {
"title" : "Test"
}
}
]
}
}
原文:https://www.cnblogs.com/thepoy/p/14717479.html