参数详解:
subset:检测重复的数据范围。默认为数据集的所有列,可指定特定数据列;
keep: 标记哪个重复数据,默认为‘first’。1.‘first’:标记重复数据第一次出现为True;‘last’:标记重复数据最后一次出现为True;False:标记所有重复数据为True。
import pandas as pd #构造数据(数据集来自pandas官网
df = pd.DataFrame({ ‘brand‘: [‘Yum Yum‘, ‘Yum Yum‘, ‘Indomie‘, ‘Indomie‘, ‘Indomie‘], ‘style‘: [‘cup‘, ‘cup‘, ‘cup‘, ‘pack‘, ‘pack‘], ‘rating‘: [4, 4, 3.5, 15, 5] })
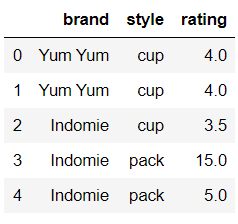
#1 df.duplicated(keep=‘first‘) #2 df.duplicated(keep=‘last‘) #3 df.duplicated(keep=False)



#检测brand列的重复情况 df.duplicated(subset=[‘brand‘])

参数详解:
subset:见上;
keep:见上;
inplace:默认为False,是否返回一个copy;
ignore_index:默认为False,是否重新构建索引。
df.drop_duplicates()
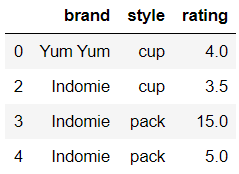
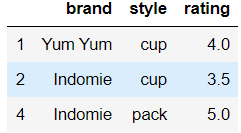
df.drop_duplicates(subset=[‘brand‘, ‘style‘], keep=‘last‘)
pandas常用操作详解——pandas的去重操作df.duplicated()与df.drop_duplicates()
原文:https://www.cnblogs.com/mmmmiles/p/14681914.html