from torch import nn import torch import torch.nn.functional as F class BiLSTM_Attention(nn.Module): def __init__(self,embedding_dim, num_hiddens, num_layers): super(BiLSTM_Attention, self).__init__() # bidirectional设为True即得到双向循环神经网络 self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size=num_hiddens, num_layers=num_layers, batch_first=True, bidirectional=True) # 初始时间步和最终时间步的隐藏状态作为全连接层输入 self.w_omega = nn.Parameter(torch.Tensor( num_hiddens * 2, num_hiddens * 2)) self.u_omega = nn.Parameter(torch.Tensor(num_hiddens * 2, 1)) self.decoder = nn.Linear(2 * num_hiddens, 4) nn.init.uniform_(self.w_omega, -0.1, 0.1) nn.init.uniform_(self.u_omega, -0.1, 0.1) def forward(self, embeddings): # rnn.LSTM只返回最后一层的隐藏层在各时间步的隐藏状态。 # embeddings形状是:(batch_size, seq_len, embedding_size) outputs, _ = self.encoder(embeddings) # output, (h, c) # outputs形状是(batch_size, seq_len, 2 * num_hiddens) # Attention过程 u = torch.tanh(torch.matmul(outputs, self.w_omega)) # u形状是(batch_size, seq_len, 2 * num_hiddens) att = torch.matmul(u, self.u_omega) # att形状是(batch_size, seq_len, 1) att_score = F.softmax(att, dim=1) # att_score形状仍为(batch_size, seq_len, 1) scored_x = outputs * att_score # scored_x形状是(batch_size, seq_len, 2 * num_hiddens) # Attention过程结束 feat = torch.sum(scored_x, dim=1) # 加权求和 # feat形状是(batch_size, 2 * num_hiddens) outs = self.decoder(feat) # out形状是(batch_size, 4) return outs
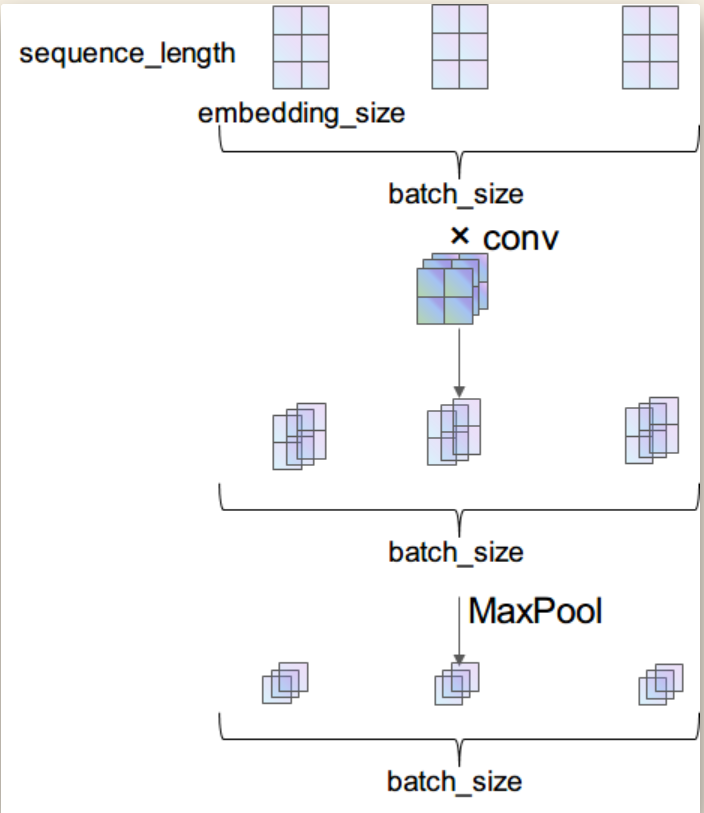
原文:https://www.cnblogs.com/zhangxianrong/p/14682246.html