1.读文本文件生成RDD lines
lines = sc.textFile(‘file:///home/hadoop/word.txt‘)
lines.collect()

2.将一行一行的文本分割成单词 words
words=lines.flatMap(lambda line:line.split())
words.collect()

3.全部转换为小写
words=lines.flatMap(lambda line:line.lower().split())
words.collect()

4.去掉长度小于3的单词
words=lines.flatMap(lambda line:line.split()).filter(lambda line:len(line)>3)
words.collect()

5.去掉停用词
1.准备停用词文本:
lines = sc.textFile(‘file:///home/hadoop/stopwords.txt‘)
stop = lines.flatMap(lambda line : line.split()).collect()
stop
2.去除停用词:
lines=sc.textFile("file:///home/hadoop/word.txt")
words=lines.flatMap(lambda line:line.lower().split()).filter(lambda word:word not in stop)
words
words.collect()

6.转换成键值对 map()
wordskv=words.map(lambda word:(word.lower(),1))
wordskv.collect()

7.统计词频 reduceByKey()
wordskv.reduceByKey(lambda a,b:a+b).collect()

8、按字母顺序排序 sortBy(f)
wordskv=words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[0])
wordskv.collect()

9、按词频排序 sortByKey()
wordskv=words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b)
wordskv.sortByKey().collect()

二、学生课程分数案例

lines.map(lambda line : line.split(‘,‘)[1]).distinct().count()






import numpy as np
np.mean([int(x) for x in meanlist])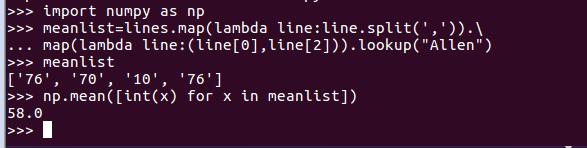
原文:https://www.cnblogs.com/zhongyaohong/p/14672376.html