从存储结构上划分
从应用层次来分
划分
Hash索引: 使用的hash表

B-Tree索引(MySQL使用B+Tree)
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。
B+树
B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
B+树的性质
1. B+树的非叶子结点不存储数据信息,存储的是索引。
2. B+树的叶子节点存储数据信息,及指向含这些关键字记录的指针
3. B+ 树中,数据对象的插入和删除仅在叶节点上进行。
为什么不用B-tree
B+树磁盘IO代价更小。因为B+ tree的内部节点不存储关键字的信息,而B树存储。所以在磁盘的一块存储节点的区域可存储B+树的内部节点更多,对应的关键字就更多,从而IO次数就会更少
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
为什么不用hash
为什么不用红黑树
随着数据量的增大,因为红黑树也是一棵二叉树。树的高度增加,时间复杂度大
为什么不用二叉排序树
树结构不均匀,查询复杂度大
区别
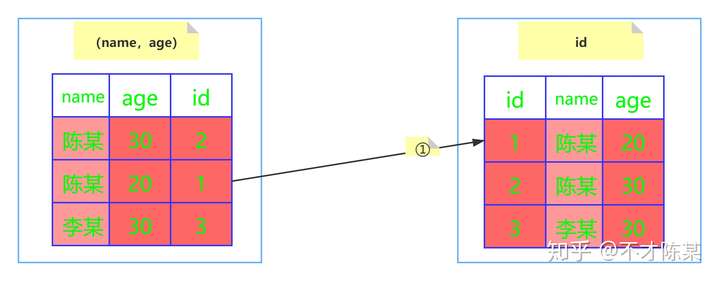
1. 非聚簇索引的叶子节点存储的是主键的值而不是整个数据
2. 对于InnoDB, 查找数据需要通过主键。 所以通过非聚簇索引先获得 主键值, 然后通过主键查找出数据,称为回表
3. 通常情况下, 主键索引(聚簇索引)查询只会查一次,而非主键索引(非聚簇索引)需要回表查询多次。当然,如果是覆盖索引的话,查一次即可
note:MyISAM无论主键索引还是二级索引都是非聚簇索引,而InnoDB的主键索引是聚簇索引,二级索引是非聚簇索引。我们自己建的索引基本都是非聚簇索引。
覆盖索引
参考blog
https://www.cnblogs.com/happyflyingpig/p/7662881.html
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
select * from table_name where name = "djh" and age > 12 and idcard = 123456;
eg:上面这个sql语句中 idcard就没有用到如果按照(name, age, idcard)建立索引。但是如果按照(name, idcard, age)就可以命中索引
select count(distinct city) / count(*) from city_demo;
select * from table_name where name = "陈%" and age = 20;
参考blog
https://zhuanlan.zhihu.com/p/121084592
通过explain,如以下例子:
EXPLAIN SELECT * FROM employees.titles WHERE emp_no=‘10001‘ AND title=‘Senior Engineer‘ AND from_date=‘1986-06-26‘;
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
插入连续数据

插入非连续数据

CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
ALTER TABLE table_name ADD INDEX index_name (column_list);
CREATE INDEX index_name ON table_name (column_list);
通常通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改。 这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O。 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
基于一个范围的检索,一般查询返回结果集小于表中记录数的30%。
基于非唯一性索引的检索。
SELECT * FROM `user` WHERE DATE(create_time) = ‘2020-09-03‘;
SELECT * FROM `user` WHERE age - 1 = 20;
SELECT * FROM `user` WHERE `name` = ‘张三‘ OR height = ‘175‘;
如果 or前后连接的是一个索引字段那么索引不会失效
SELECT * FROM `user` WHERE `name` LIKE ‘%冰‘;
% 放在匹配字段前索引就会失效
参考文章
https://www.nowcoder.com/discuss/639644?channel=-1&source_id=profile_follow_post_nctrack
https://www.cnblogs.com/bypp/p/7755307.html (对于B+树的索引查询)
原文:https://www.cnblogs.com/jiahaodaicoder/p/14664644.html