一.概念
K均值聚类(k-means)是基于样本集合划分的聚类算法。K均值聚类将样本集合划分为k个子集,构成k个类,将n个样本分到k个类中,每个样本到其所属类的中心距离最小,每个样本仅属于一个类,这就是k均值聚类,同时根据一个样本仅属于一个类,也表示了k均值聚类是一种硬聚类算法。
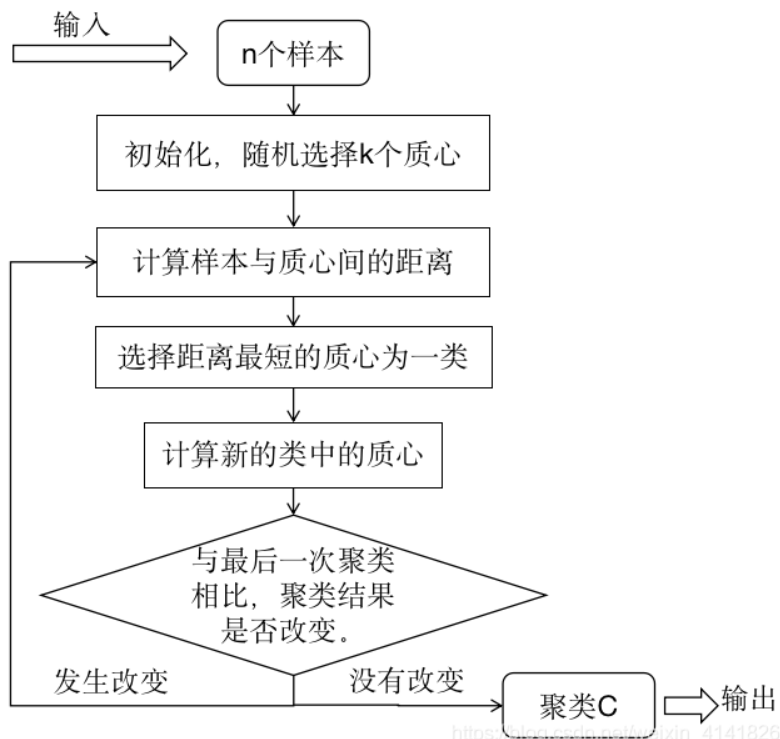
二.大致过程
输入:n个样本的集合
输出:样本集合的聚类
过程:
(1)初始化。随机选择k的样本作为初始聚类的中心。
(2)对样本进行聚类。针对初始化时选择的聚类中心,计算所有样本到每个中心的距离,默认欧式距离,将每个样本聚集到与其最近的中心的类中,构成聚类结果。
(3)计算聚类后的类中心,计算每个类的质心,即每个类中样本的均值,作为新的类中心。
(4)然后重新执行步骤(2)(3),直到聚类结果不再发生改变。
K均值聚类算法的时间复杂度是O(nmk),n表示样本个数,m表示样本维数,k表示类别个数。
三.伪代码
创建k个作为起始质心(通常是随机选择)
当任意一个点的簇分配结果发生改变时
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距离其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
原文:https://www.cnblogs.com/minglogin/p/14632531.html