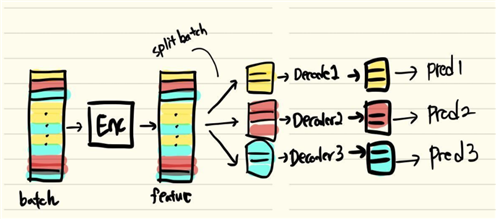
一个多分支输出网络(一个Encoder,多个Decoder)
我们期望每个分支的损失L_i分别对各自的参数进行优化,而共享参数部分采用各分支损失之和Sum(L_i)进行优化。
params = list(Encoder.parameters()) + list(Decoder1.parameters()) + list(Decoder2.parameters()) + list(Decoder3.parameters())
optim = torch.optim.Adadelta(params, learning_rate)
encoder_output = Encoder(input)
optim.zero_grad()
loss_1, loss_2, loss_3 = 0, 0, 0
# split batch
if encoder_output[1_batch_ind].shape[0] != 0:
output1 = Decoder1(encoder_output[1_batch_ind])
loss_1 = loss_fn(output1, ground_truth[1_batch_ind])
if encoder_output[2_batch_ind].shape[0] != 0:
output2 = Decoder2(encoder_output[2_batch_ind])
loss_2 = loss_fn(output2, ground_truth[2_batch_ind])
if encoder_output[3_batch_ind].shape[0] != 0:
output3 = Decoder3(encoder_output[3_batch_ind])
loss_3 = loss_fn(output3, ground_truth[3_batch_ind])
loss = loss_1 + loss_2 + loss_3
loss.backward()
optim.step()
## you can simply do: o1, o2 = mm(input) o = o1 + o2 # loss ## Or you can do l1 = loss(o1, target) l2 = loss2(o2, target2) torch.autograd.backward([l1, l2])
如果想不同的分支采用不同的优化器:
opt1 = optim.Adam(branch_1.parameters(), ...) opt2 = optim.SGD(branch_2.parameters(), ...) ... ... loss = 2*loss_1 + 3 *loss_2 loss.backward() opt1.step() opt2.step()
原文:https://www.cnblogs.com/jiangkejie/p/14635297.html