先有的driver,在driver中创建的sparkcontext。
运行应用程序的main函数,启动一个Driver进程。功能如下:
Driver负责和ClusterManager通信,进行资源的申请、任务的分配和监控等。
Driver(驱动程序):Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责与ClusterManager集群管理器进行通信,进行资源的申请,任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。
spark是粗粒度资源申请,application启动之前首先将所有的资源申请完毕,如果申请不到一直处于等待状态,一直到资源申请到为止。必须一次申请完毕之后,才会执行任务,这样,task执行的时候,task不需要自己申请资源,加快了task的执行效率,task快了,job就快了,job快,application执行就快了。必须最后一个task执行完毕之后,才会释放所有资源。
TaskScheduler.submitTask(taskSet, ...)方法,TaskScheduler本身是个接口,spark里只实现了一个TaskSchedulerImpl。调用TaskSchedulerImpl.submitTask(taskSet, ...)接收DAGScheduler提交来的tasks ,分析stage里Task的类型,生成一个Task描述,即TaskSet。TaskSchedulerImpl.TaskSetManager(taskSet, ...)为tasks创建一个TaskSetManager,添加到任务队列里。TaskSetManager跟踪每个task的执行状况,维护了task的许多具体信息。TaskScheduler下层,用于对接不同的资源管理系统,SchedulerBackend是个接口,实现类是CoarseGrainedSchedulerBackend。通过SchedulerBackend.reviveOffers给driverEndpoint发送ReviveOffer消息。reviveOffers()方法的实现。就是别人直接向SchedulerBackend请求资源, 直接调用了makeOffers()方法,SchedulerBackend把node节点上可用资源交给TaskScheduler,TaskScheduler根据调度策略为排队的任务分配合理的cpu和内存资源,返回一批可执行的任务描述。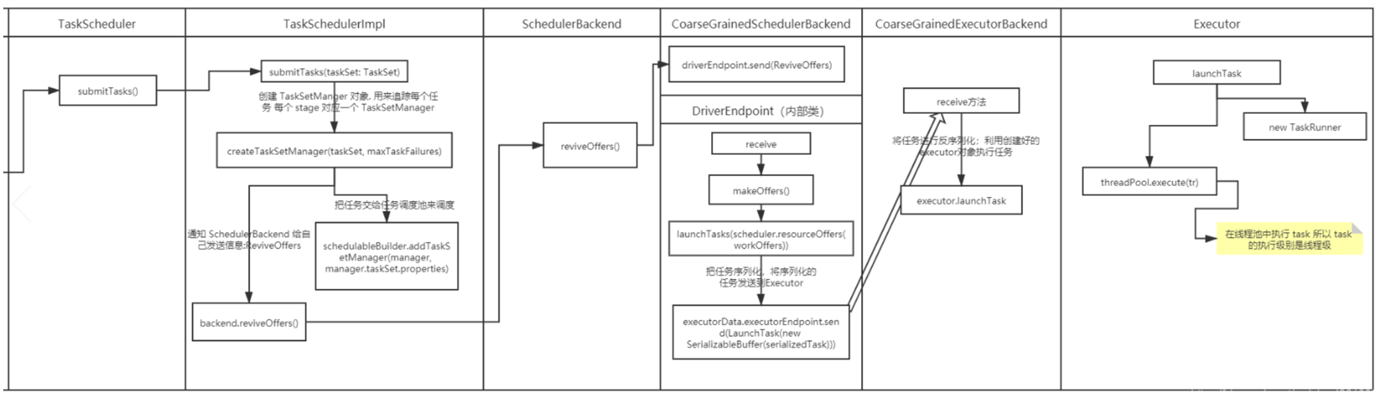
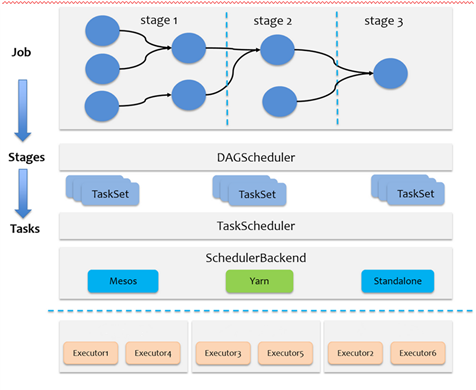
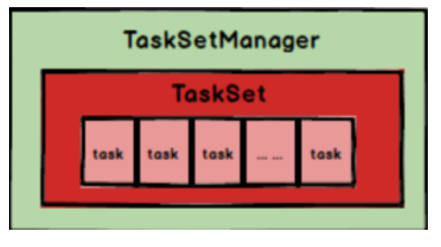
原文:https://www.cnblogs.com/wanpi/p/14616748.html