语音识别,大体可分为“传统”识别方式与“端到端”识别方式,其主要差异就体现在声学模型上。
“传统”方式的声学模型一般采用隐马尔可夫模型(HMM),而“端到端”方式一般采用深度神经网络(DNN)
related doc:
https://sites.google.com/site/dpovey/kaldi-lectures
Kaldi架构如所示,最上面是外部的工具,包括用于线性代数库BLAS/LAPACK和我们前面介绍过的OpenFst。中间是Kaldi的库,包括HMM和GMM等代码,下面是编译出来的可执行程序,最下面则是一下脚本,用于实现语音识别的不同步骤(比如特征提取,比如训练单因子模型等等)。
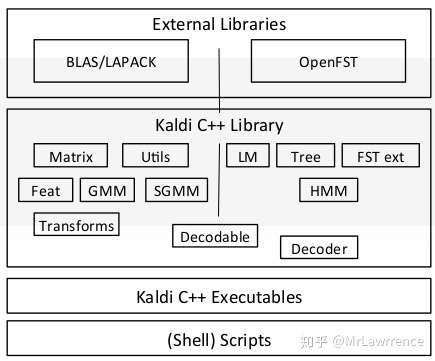
图:Kaldi架构
对应大部分Kaldi的用户来说,我们只需要使用脚本和配置文件就可以完成语音识别系统的训练和预测了。
in my opinion Kaldi requires solid knowledge about speech recognition and ASR systems in general.
kaldi - main Kaldi directory which contains:
egs – example scripts allowing you to quickly build ASR systems for over 30 popular speech corpora (documentation is attached for each project)以使用的数据库的名字命名。在下一级目录中以s开头的文件是语音识别,以v开头的是声纹识别,一般v1就是使用i-vector的方法来进行声纹识别
misc – additional tools and supplies, not needed for proper Kaldi functionality,src – Kaldi source code,tools – useful components and external tools,windows – tools for running Kaldi using Windows.The most important directory for you is obviously egs. Here you will create your own ASR system
kaldi主要用脚本来驱动,每个recipe下会有很多脚本。local目录下的脚本通常是与这个example相关,不能移植到别的例子,通常是数据处理等“一次性”的脚本。而util下的脚本是通用的一些工具。steps是训练的步骤,最重要的脚本。
WER(Word Error Rate)是字错误率,是一个衡量语音识别系统的准确程度的度量。其计算公式是WER=(I+D+S)/NWER=(I+D+S)/N,其中I代表被插入的单词个数,D代表被删除的单词个数,S代表被替换的单词个数。也就是说把识别出来的结果中,多认的,少认的,认错的全都加起来,除以总单词数。这个数字当然是越低越好。
原文:https://www.cnblogs.com/ai-ldj/p/14614474.html