本文主要针对ThreadPoolExecutor初始化到正常工作时的代码解读,对其他的生命周期先挖个坑,可能以后埋。
1.构造方法
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
所有构造方法都会调用这个构造方法。方法参数包含了ThreadPoolExecutor的7个最重要的参数。
corePoolSize:核心线程数上限。核心线程一旦创建,除非ThreadPoolExecutor准备关闭,不然一直存在。
workQueue:任务队列,如果任务数量太多,核心线程处理不过来,那么任务会先放入任务队列中等待处理。注意!!!队列最好自定义,并且按照项目实际情况设计容量。如果队列容量过大(如LinkedBlockingQueue,默认长度为Integer.MAX_VALUE),那么当任务过大的时候大概率导致OOM。
maximumPoolSize:最大线程数上限。当任务队列放不下,那么将会启动非核心线程执行当前任务或者从队列中取任务。一旦非核心线程没有任务,那么将一段时间后被回收。
keepAliveTime:生存时间,非核心线程在一段生存时间内都没有任务,将被回收。
unit:生存时间的单位,如秒,毫秒。
threadFactroy:生成线程的工厂对象。注意!!!工厂最好自定义,默认的jdk线程工厂不会对线程的三个属性:名字,是否后台线程和权限,做特殊的处理。为了方便服务器以后调优和bug处理,至少要给线程起符合业务场景的名字,帮助后期快速定位问题。
handler:在ThreadPoolExecutor不再接受新的任务,或者没有空闲非核心线程并且任务队列都已满的情况下,对任务执行的拒绝策略。jdk自带四种策略:1)抛异常。2)不抛异常,直接丢掉。3)丢掉队列中最旧的任务。4)谁发布的任务谁自己完成。注意!!!除了非常特殊的业务场景,不要使用任何jdk自带的策略。最好自定义拒绝策略,使用消息队列或者mysql将暂时无法处理的任务保存起来,空闲的时候完成。
2.ctl
ctl显示ThreadPoolExecutor的工作状态和目前的线程数,在后面代码中大量使用。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1;
private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS; private static int runStateOf(int c) { return c & ~CAPACITY; } private static int workerCountOf(int c) { return c & CAPACITY; } private static int ctlOf(int rs, int wc) { return rs | wc; } private static boolean runStateLessThan(int c, int s) { return c < s; } private static boolean runStateAtLeast(int c, int s) { return c >= s; }
ctl可以看作一个32位的二进制数,前三位为ThreadPoolExecutor的工作状态(包含RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED,它们的初始赋值已经将数字都映射到ctl的前三位上了),后29位(COUNT_BITS)为ThreadPoolExecutor目前的线程数量。CAPACITY是一个低29位都是1的二进制数,可以通过与操作从ctl分离出工作状态和线程数量两个信息。
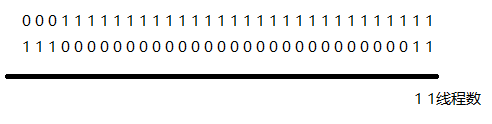
上图workerCountOf(ctl)的示意图。上一个数字是CAPACITY,下一个数字是ctl(RUNNING状态,3个线程),通过与操作可以快速分离出线程数。runStateOf()也类似。
注意,第一位是符号位,只要是RUNNING状态,那么ctl肯定少于(SHUTDOWN及往后的所有状态)。
3.提交任务(execute)
public void execute(Runnable command) { if (command == null) throw new NullPointerException();
//1.试图提交到核心线程 int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); }
//2.提交到队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); }
//3.新建非核心线程 else if (!addWorker(command, false)) reject(command); }
1)试图提交到核心线程。
首先查询ctl当前的线程是否少于核心线程数。如果是,那么试图新建核心线程(addWork(command,true))并执行当前任务。新建核心线程前后再次检查ctl,如果已经核心线程数已经达到上限,那么新建失败。如果新建成功,那么提交任务也成功了。结束方法。如果新建过程失败,那么将进入步骤2。
2)插入队列。
当前线程会重新检查ctl,如果ThreadPoolExecutor还是工作状态(isRunning(c)),那么试图加入到任务队列中。加入队列成功,会再次重新检查ctl。如果ThreadPoolExecutor还在工作,那么检查线程数是否为0,如果是,那么新建非核心线程执行任务(addWork(null,false),jdk自带的Executors.CachePoolExecutor是没有核心线程,需要通过这个方式新建线程)。如果ThreadPoolExecutor不是工作状态了,那么从队列中去除该任务(remove(command)),并且执行拒绝策略。如果加入队列失败,就会进入步骤3。
3)新建非核心线程。
无法加入队列,那么试图新建非核心线程来完成当前任务,如果失败了,那么执行拒绝策略。
3.addWorker
reject()和offer()是拒绝策略和队列自带的方法,因此不做讲述。addWorker则是重点。
Worker是ThreadPoolExecutor的工作单元。
private final class Worker extends AbstractQueuedSynchronizer implements Runnable { private static final long serialVersionUID = 6138294804551838833L; //持有的线程 final Thread thread; //持有的任务 Runnable firstTask; //完成的任务数 volatile long completedTasks; Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); } public void run() { runWorker(this); } //省略AQS体系的代码,详情以后在解析 .... }
Worker具有线程和任务,并使用线程执行当前持有的任务。同时由于Worker继承AbstractQueuedSynchronizer类,因此它的方法实现都是基于AQS体系(AQS体系会在下一篇博客中提出),也可以认为它是一个锁。
接下来回到addWorker()方法中。方法分为两部分,分别是判断是否可以生成Worker和生成Worker。首先看第一部分:
private boolean addWorker(Runnable firstTask, boolean core) { retry:
//1.外循环,判断线程池当前的工作状态 for (;;) { int c = ctl.get(); int rs = runStateOf(c); //2.看似复杂的条件判断 if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; //3.试图修改ctl中的当前线程数 for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); if (runStateOf(c) != rs) continue retry; } }
步骤:
1)每次试图新建Worker(新建的过程会有多次,只要线程池一直在工作,那么就会一直重试新建,知道线程池工作被shutdown)都会重新检查ctl中的线程池工作状态。如果线程池的工作状态发生变化,跳到步骤2。否则跳到步骤3。
2)看上去很复杂的条件判断,这里可以给出两种更好理解的方式。
2.1)经过调整后,意义不变的判断条件: (rs > SHUTDOWN) || (rs == SHUTDOWN && firstTask != null) || (rs == SHUTDOWN && workQueue.isEmpty())
2.2)如果线程池处于TIDY,TERMINATED,无法创建任何新Worker。如果是处于SHUTDOWN状态,那么当且仅当,任务队列还有任务以及addWorker()时不带有任何任务时(即仅仅是创建新Worker用来解决任务队列中没有完成的任务,不可以处理新任务),才可以新建Worker。
3)试图修改ctl的当前线程数。判断新建Worker后,线程数是否会超过ctl所能记录的最大线程数(2 ^ 29),然后根据core(addWorker方法参数,true代表这次创建的Worker持有核心线程。反之为非核心线程)判断当前线程数是否超过了核心线程上限或者非核心线程上限。如果超过了,那么直接退出方法。否则,使用CAS修改ctl中过的新建线程数,并结束第一部分的代码。如果CAS修改失败(其他线程速度更快),检查ctl的状态是否有变化。没有的话重复步骤3,否则跳到步骤1。
第二部分:
boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try {
//1.新建Worker对象 w = new Worker(firstTask); final Thread t = w.thread; if (t != null) {
//2.将Worker对象加入到自己的workers中 final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) throw new IllegalThreadStateException(); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); }
//3.工人开始工作 if (workerAdded) { t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
步骤:
1)新建Worker。新Worker会从线程工厂中获取线程。
2)将Worker对象加入到自己的workers中。workers是一个HashSet,用来存放所有的Worker。为了保证同步,使用了ThreadPoolExecutor的lock进行锁定。再加入workers前,需要确保Worker还没有开始工作。
3)Worker开始工作。上面知道,Worker即可以看作线程,也可以看作锁。因此它的run()相当地有趣。我将在下一篇文章中详解AQS体系,看看Worker和ReentrantLock之间的异同。
至此,提交任务的部分都讲完了。如果有时间,我会补充ThreadPoolExecutor的其他方法的,有缘再见!
原文:https://www.cnblogs.com/sergeantFat/p/14518052.html