1.进入桌面
1 cd C:\Users\Mr_wa\Desktop
2.新建项目
scrapy startproject qsbk
3.新建爬虫
cd qsbk
scrapy genspider qsbk_spider qiushibaike.com
4.修改settings.py
1 ROBOTSTXT_OBEY = False 2 3 DEFAULT_REQUEST_HEADERS = { 4 ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, 5 ‘Accept-Language‘: ‘en‘, 6 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36‘ 7 }
5.书写qsbk_spider.py(start_urls)
1 import scrapy 2 3 4 class QsbkSpiderSpider(scrapy.Spider): 5 name = ‘qsbk_spider‘ 6 allowed_domains = [‘qiushibaike.com‘] 7 start_urls = [‘https://www.qiushibaike.com/text/page/1/‘] 8 9 def parse(self, response): 10 pass
6.根目录新建运行文件start.py
1 from scrapy import cmdline 2 3 cmdline.execute([‘scrapy‘, ‘crawl‘, ‘qsbk_spider‘])
7.爬虫测试(查看response类型)
1 import scrapy 2 3 4 class QsbkSpiderSpider(scrapy.Spider): 5 name = ‘qsbk_spider‘ 6 allowed_domains = [‘qiushibaike.com‘] 7 start_urls = [‘https://www.qiushibaike.com/text/page/1/‘] 8 9 def parse(self, response): 10 print("===================") 11 print(type(response)) 12 print("===================")
8.在start.py中运行结果
=================== <class ‘scrapy.http.response.html.HtmlResponse‘> ===================
8.xpath解析数据
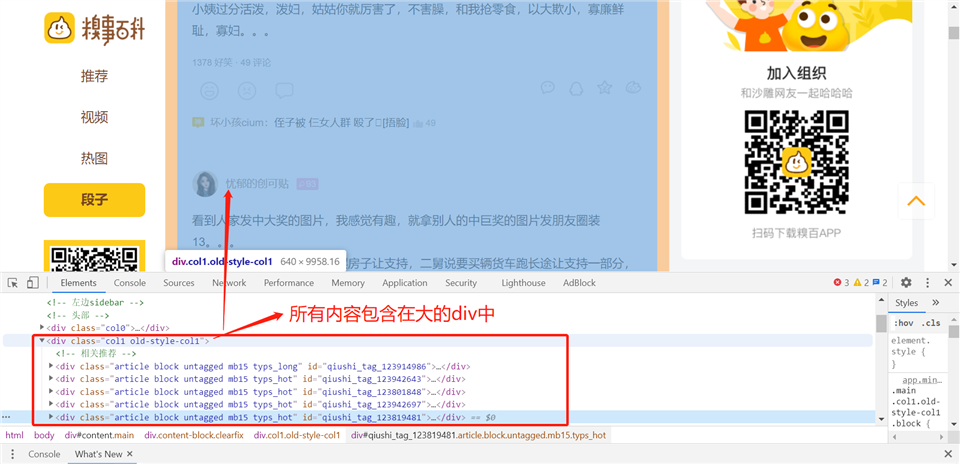
获取作者和段子内容
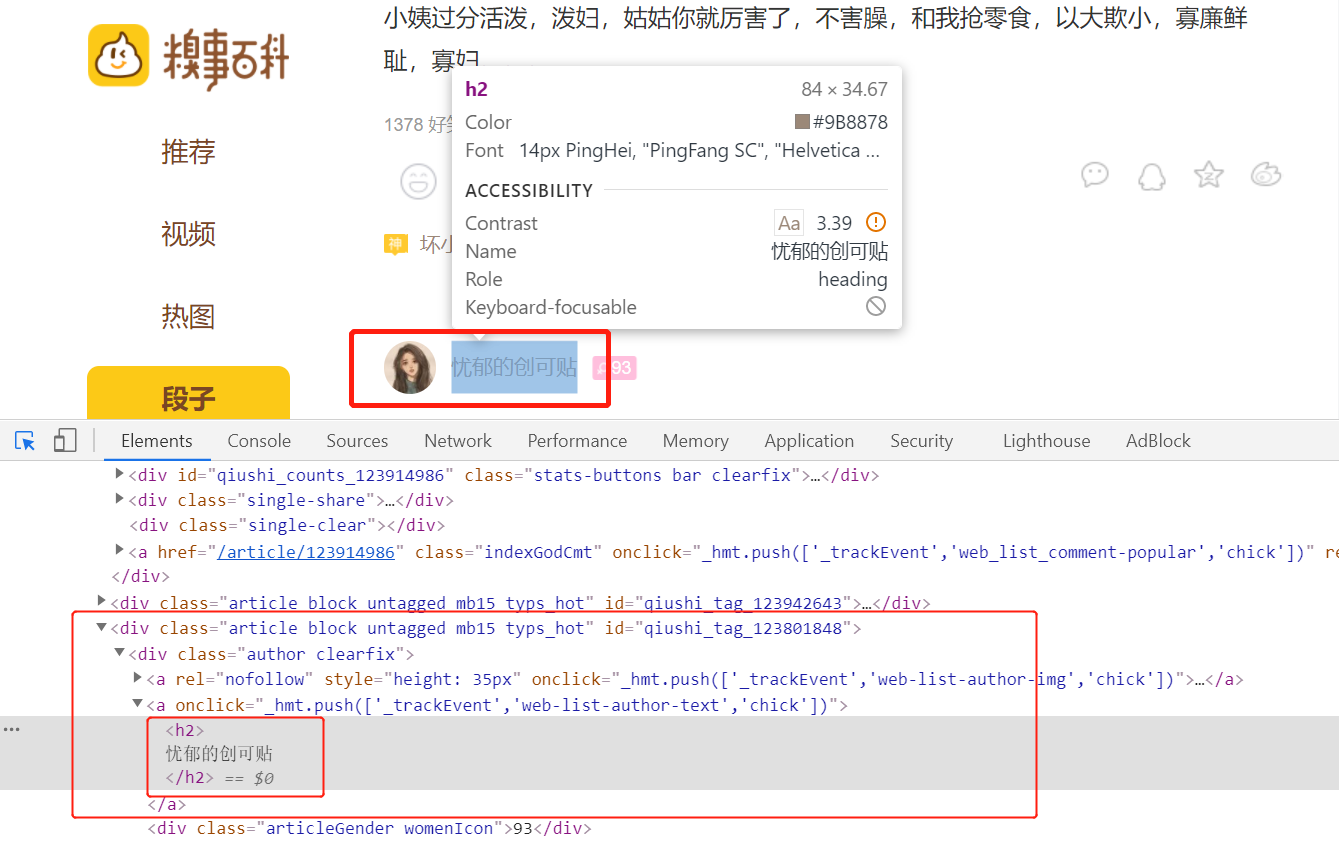
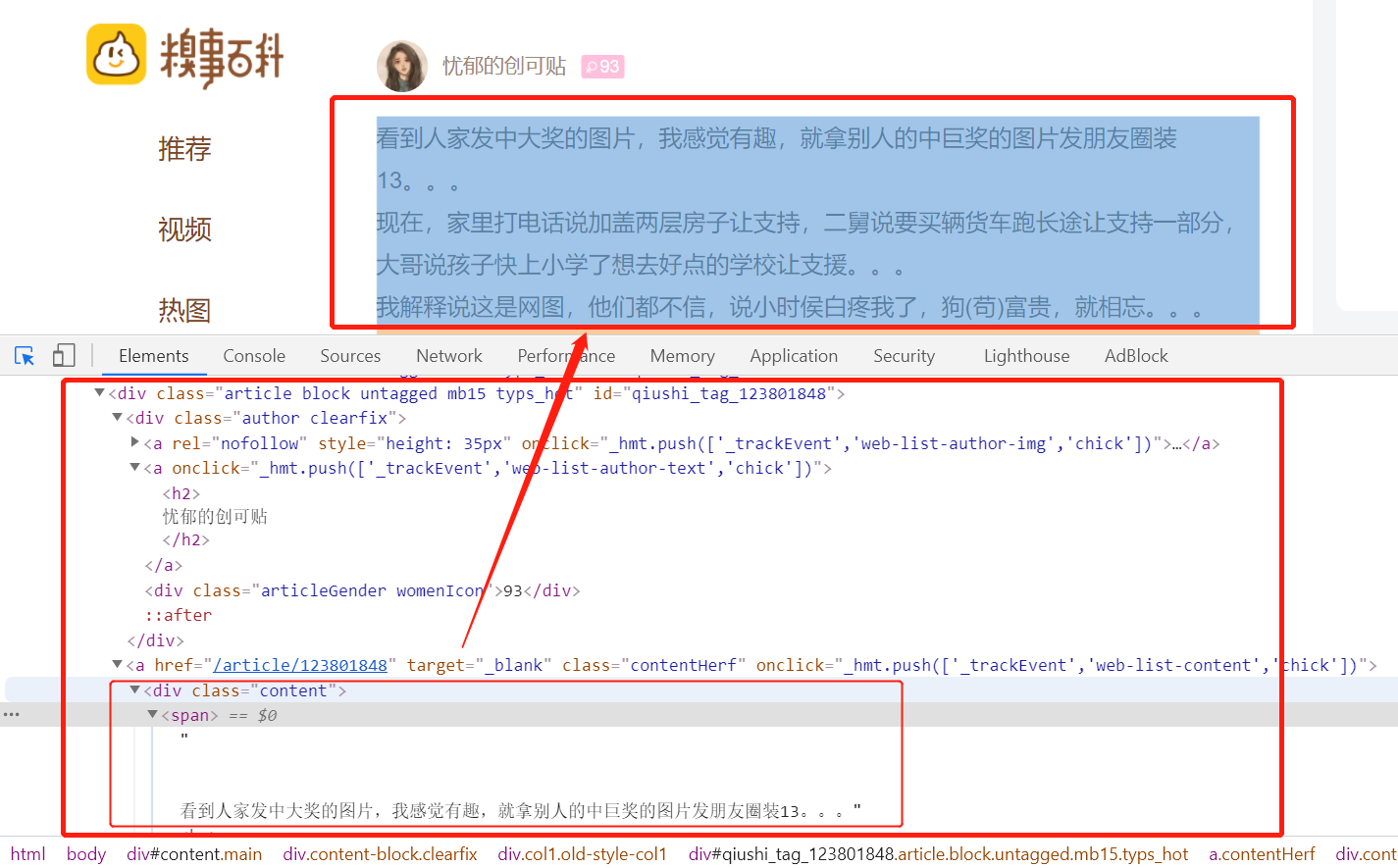
1 import scrapy 2 3 4 class QsbkSpiderSpider(scrapy.Spider): 5 name = ‘qsbk_spider‘ 6 allowed_domains = [‘qiushibaike.com‘] 7 start_urls = [‘https://www.qiushibaike.com/text/page/1/‘] 8 9 def parse(self, response): 10 # content_list : SelectorList 11 content_list = response.xpath("//div[@class=‘col1 old-style-col1‘]/div") 12 # content : selector 13 for content in content_list: 14 author = content.xpath(".//h2/text()").get().strip() 15 text = content.xpath(".//div[@class=‘content‘]//text()").getall() 16 text = "".join(text).strip() 17 duanzi = {‘author‘: author, ‘content‘: text} 18 print(duanzi)

9.存储数据
在item.py中定义数据保存的类型,(而不是上面的字典 duanzi = {‘author‘: author, ‘content‘: text})
1 import scrapy 2 3 4 class QsbkItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 author = scrapy.Field() 8 text = scrapy.Field()
qsbk_spider.py
import scrapy from ..items import QsbkItem class QsbkSpiderSpider(scrapy.Spider): name = ‘qsbk_spider‘ allowed_domains = [‘qiushibaike.com‘] start_urls = [‘https://www.qiushibaike.com/text/page/1/‘] def parse(self, response): # content_list : SelectorList content_list = response.xpath("//div[@class=‘col1 old-style-col1‘]/div") # content : selector for content in content_list: author = content.xpath(".//h2/text()").get().strip() text = content.xpath(".//div[@class=‘content‘]//text()").getall() text = "".join(text).strip() item = QsbkItem(author=author, content=text) yield item
settings.py 取消注释
ITEM_PIPELINES = { ‘qsbk.pipelines.QsbkPipeline‘: 300, }
pipelines.py 保存数据
# Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter import json class QsbkPipeline: def process_item(self, item, spider): with open(‘qsbk.json‘, ‘a‘, encoding=‘utf-8‘) as f: f.write(json.dumps(dict(item), ensure_ascii=False)) return item
保存为json
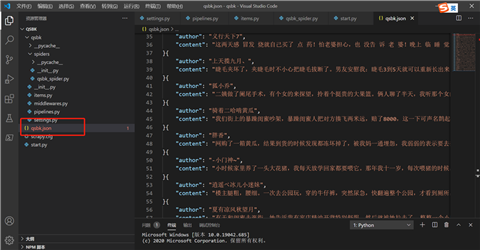
爬取多页,并保存为csv格式
qsbk_spider.py
import scrapy from ..items import QsbkItem class QsbkSpiderSpider(scrapy.Spider): name = ‘qsbk_spider‘ allowed_domains = [‘qiushibaike.com‘] start_urls = [‘https://www.qiushibaike.com/text/page/1/‘] def parse(self, response): # content_list : SelectorList content_list = response.xpath("//div[@class=‘col1 old-style-col1‘]/div") # content : selector for content in content_list: author = content.xpath(".//h2/text()").get().strip() text = content.xpath(".//div[@class=‘content‘]//text()").getall() text = "".join(text).strip() item = QsbkItem(author=author, content=text) yield item next_url = response.xpath("//ul[@class=‘pagination‘]/li[last()]/a/@href").get() if next_url: next_url = ‘https://www.qiushibaike.com‘ + next_url yield scrapy.Request(next_url, callback=self.parse)
pipelines.py
# Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter import csv class QsbkPipeline: def process_item(self, item, spider): with open(‘qsbk.csv‘, ‘a‘, encoding=‘utf-8‘, newline="") as f: writer = csv.writer(f) writer.writerow([item["author"], item["content"]]) return item
原文:https://www.cnblogs.com/waterr/p/14229612.html