字符串的驻留机制
1.字符串
2.什么叫字符串驻留机制?
举例:
‘‘‘字符串的驻留机制‘‘‘ a=‘Python‘ b="Python" c=‘‘‘Python‘‘‘ print(a,id(a)) print(b,id(b)) print(c,id(c))
执行结果:
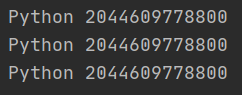
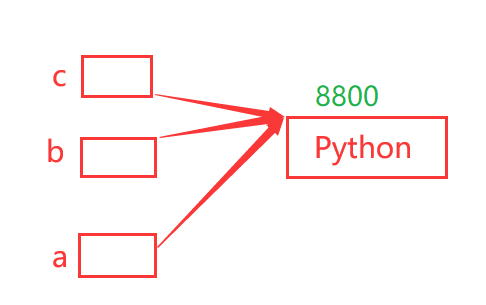
说明:a,b,c三个对象的值和内存地址都相同,即当创建了a后,后面新建与a内容相同的变量时,则不会重新开辟新的内存空间,而是直接把已有的内存地址赋值给b和c变量,如下图
3. 驻留机制的几种情况(交互模式)
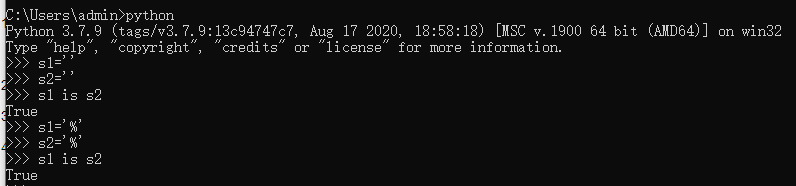
3.1 字符串的长度为0或1时
3.2 符合标识符的字符串(含有数字、字母、下划线是符合标识符的字符串)
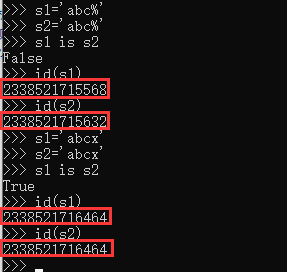
说明:abc%不符合表示字符串,所有各有一个内存地址,abcx符合标识字符串,所以指向的是同一个内存地址
3.3 字符串只在编译时进行驻留,而非运行时

3.4 [-5,256]之间的整数数字

3.5 sys中的intern方法强制2个字符串指向同一个对象
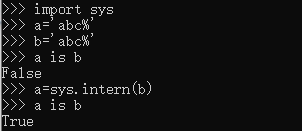
说明:a,b因为不是符合标识符的字符串,所以它们的内存地址是不一样的,在使用intern()方法后,使得b的内存地址被强制改成和a的内存地址一样,所以进行is运算时值是True
3.6 PyCharm对字符串进行了优化处理
举例:(使用PyCharm运行如下代码)
a=‘abc%‘ b=‘abc%‘ print(a is b)
执行结果如下:
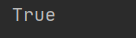
说明:如果使用终端来执行的话,上面代码输出结果是False,但是使用PyCharm运行,则结果是True,表示PyCharm对代码有做一定的优化。
4. 字符串驻留机制的优缺点
5.字符串的常用操作
5.1 字符串的查询操作的方法

举例:
查找变量s=‘hello,hello‘ 中 ‘lo‘ 的位置
‘‘‘字符串的查询操作‘‘‘ s=‘hello,hello‘ print(s.index(‘lo‘)) print(s.find(‘lo‘)) print(s.rindex(‘lo‘)) print(s.rfind(‘lo‘)) ‘‘‘当查询不存在的字符时,index和rindex会报ValueError,find和rfind则返回-1,推荐用find‘‘‘ #print(s.index(‘k‘)) #ValueError: substring not found print(s.find(‘k‘)) #-1 #print(s.rindex(‘k‘)) #ValueError: substring not found print(s.rfind(‘k‘)) #-1
执行结果如下:
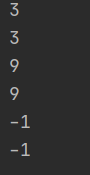
说明:字符串索引图如下:

使用index和find是,‘lo‘ 出现的第一个位置是3,使用rindex和rfind查找最后一个‘lo‘的位置是9,当查找的字符不存在时,使用index和rindex时会报"ValueError",使用find和rfind时则返回-1
5.2 字符串的大小写转换操作的方法

举例:
s=‘hello,Python‘ # a=s.upper() #转成大写之后,产生一个新的字符串对象 # print(a,id(a)) # print(s,id(s))
执行结果:

说明:在对字符串进行大小写转换操作,会产生一个新的字符串对象,原来的字符串不变
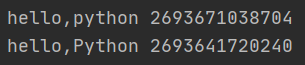
s=‘hello,Python‘ a=s.lower() #转成小写之后,产生一个新的字符串对象 print(a,id(a)) print(s,id(s))
执行结果如下:
s=‘hello,Python‘ a=s.swapcase() #转换之后,产生一个新的字符串对象 print(a,id(a)) print(s,id(s))
执行结果:
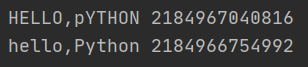
s=‘hello,Python‘ a=s.capitalize() #转换之后,产生一个新的字符串对象 print(a,id(a)) print(s,id(s))
执行结果:
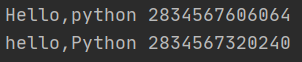
s=‘hello,Python‘ a=s.title() #转换之后,产生一个新的字符串对象 print(a,id(a)) print(s,id(s))
执行结果:

5.3 字符串内容对齐操作的方法

举例:
#居中对齐 s=‘hello,Python‘ print(s.center(20,‘*‘)) #将s居中对齐,其它位置使用*进行填充
执行结果:

#左对齐 s=‘hello,Python‘ print(s.ljust(20,‘*‘)) print(s.ljust(10)) print(s.ljust(20))
执行结果:
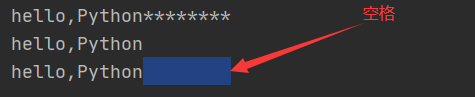
说明:使用ljust()方法进行左对齐操作时,如果设置宽度10小于原字符串宽度12时,则返回原字符串,如果设置宽度20大于原字符串宽度12时,则右边默认使用空格填充
#右对齐 s=‘hello,Python‘ print(s.rjust(20,‘0‘)) print(s.rjust(20)) print(s.rjust(8))
执行结果:
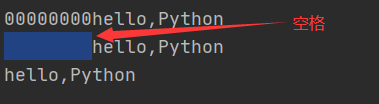
说明:使用rjust()方法进行右对齐操作,当设置宽度20大于原字符串宽度12时,左侧默认使用空格填充,如果设置的宽度8小于原宽度12,则返回原字符串
#右对齐,使用0进行填充 s=‘hello,Python‘ print(s.zfill(20)) print(s.zfill(10)) print(‘-8910‘.zfill(8))
执行结果:
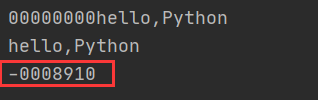
说明:使用zfill()方法进行右对齐时,左侧默认使用0填充,当填充的数据前有符号时,则将0填充至符号之后
5.4 字符串劈分操作的方法
举例:
‘‘‘字符串的劈分(分割)‘‘‘ s=‘hello world python‘ lst=s.split() #当不输入参数时,默认使用空格进行分割,分割后是一个列表 print(lst,type(lst))
执行结果:

说明:s=‘hello world python‘中本身就包含空格,则会默认从空格处进行劈分,会劈分成‘hello‘,‘world‘,‘python‘3个字符串组成的列表
‘‘‘使用指定的劈分符进行劈分‘‘‘ s1=‘hello|world|python‘ print(s1.split(sep=‘|‘)) #使用‘|‘进行劈分 print(s1.split(sep=‘|‘,maxsplit=1)) #使用‘|‘进行劈分,最多劈分1次,劈分之后剩余的子字符串会成为一个字符串
执行结果:

说明:使用split()从右侧使用‘|‘进行劈分时,劈分成3个字符串,当使用参数 maxsplit=1 设置最大劈分次数为1时,剩下的 world|python 会作为一个字符串进行保存
‘‘‘rsplit()从右侧开始劈分‘‘‘ s1=‘hello|world|python‘ print(s1.rsplit(sep=‘|‘)) print(s1.rsplit(sep=‘|‘,maxsplit=1)) #使用‘|‘进行劈分,最多劈分1次,劈分之后剩余的子字符串会成为一个字符串
执行结果:

说明:使用rsplit()从右侧使用‘|‘进行劈分时,和左侧劈分结果一样,都是劈分成3个字符串,当使用参数 maxsplit=1 设置最大劈分次数为1时,剩下的 hello|world 会作为一个字符串进行保存
5.5 判断字符串操作的方法

举例:
‘‘‘判断字符串的操作‘‘‘ #判断字符串是否是合法的标识符 s=‘hello,python‘ print(‘1.‘,s.isidentifier()) #False print(‘2.‘,‘hello‘.isidentifier()) #True print(‘3.‘,‘张三_‘.isidentifier()) #True print(‘4.‘,‘张三_123‘.isidentifier()) #True
执行结果:
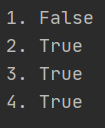
说明:合法标识符是指含有字母、数字和下划线的字符串,s=‘hello,python‘ 中包含逗号,则执行结果为False
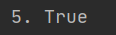
print(‘5.‘,‘\t‘.isspace()) #True
执行结果如下:
#判断字符串是否全部由字母组成 print(‘6.‘,‘abc‘.isalpha()) #True print(‘7.‘,‘张三‘.isalpha()) #True print(‘8.‘,‘abc123‘.isalpha()) #False
执行结果:
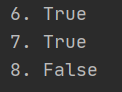
说明:‘abc123‘ 中包含数字,故输出为False
#判断字符串全部由十进制数字组成 print(‘9.‘,‘123‘.isdecimal()) #True print(‘10.‘,‘123四‘.isdecimal()) #False print(‘11‘,‘ⅡⅡⅡⅢ‘.isalpha()) #False
执行结果:
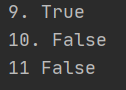
说明:‘四‘ 不是十进制数字,返回False,‘ⅡⅡⅡⅢ‘也不是十进制数字,返回False
#判断字符串是否全部由数字组成 print(‘12.‘,‘123‘.isnumeric()) #True print(‘13.‘,‘123四‘.isnumeric()) #True print(‘14.‘,‘ⅡⅡⅡⅢ‘.isnumeric()) #True
执行结果:
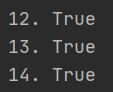
说明:‘四‘ 是数字,返回True,‘ⅡⅡⅡⅢ‘也是数字,返回True
#判断字符串是否全部由字母和数字组成 print(‘15.‘,‘abc1‘.isalnum()) #True print(‘16.‘,‘张三123‘.isalnum()) #True print(‘17.‘,‘abc!‘.isalnum()) #False
执行结果:
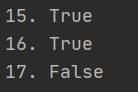
说明:‘张三123‘是由数字和字母组成,‘abc!‘不是由数字和字母组成,则返回False
5.6 字符串操作的其它方法

举例:
‘‘‘字符串的替换‘‘‘ s=‘hello,Python‘ print(s.replace(‘Python‘,‘Java‘)) s1=‘hello,Python,Python,Python‘ print(s1.replace(‘Python‘,‘Java‘,2))
执行结果:
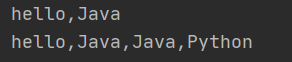
说明:s1.replace(‘Python‘,‘Java‘,2) 中2表示最多替换2次,所以最后一个输出中还有一个Python
lst=[‘hello‘,‘java‘,‘python‘] print(‘|‘.join(lst)) print(‘‘.join(lst)) t=(‘hello‘,‘java‘,‘python‘) print(‘‘.join(t)) print(‘*‘.join(‘Python‘))
执行结果:
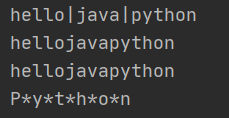
说明:‘*‘.join(‘Python‘) 中将Pyhton当成一个序列,如果想用空连接字符串,则用‘‘即可
原文:https://www.cnblogs.com/wx170119/p/14437943.html