第 2 篇https://arxiv.org/abs/2012.14978
提出了三种方案
元学习以构造不同实体类型的原型
监督对嘈杂的Web数据进行的预训练,以提取与实体相关的通用表示形式
自训练,以利用未标记的域内数据。 还考虑了这些方案的不同组合。
在快速学习设置中,提出的NER方案显着改善或优于常用的基线,该基线是在域标签上微调的基于PLM的线性分类器。
与现有方法相比,我们在few-shot和无训练的设置上都创建了最新的结果。我们将发布代码和经过预训练的模型以进行可重复的研究
为了应对小样本学习的挑战,我们专注于从三个互补的方向提高NER的PLM的泛化能力,如图1所示。而不是通过经典方法来限制使用有限的域内标记token来限制自己
我们创建原型作为不同实体类型的表示,并通过最近邻居标准分配标签
我们使用带有大量噪声标签的网络数据连续地对PLM进行预训练,以提高NER的准确性和鲁棒性;
我们使用未标记的域内令牌通过自我训练来预测其软标签,并结合有限的标记数据执行半监督学习。
为了阐明对少发NER的未来研究,我们的研究建议:(i)嘈杂的有监督的预训练可以显着提高NER的准确性,我们将发布我们的预训练检查点。 (ii)当未标记数据和已标记数据之间的数据量比例很高时,自训练将持续改善few-shot学习。 (iii)原型学习的表现在不同的数据集上有所不同。 当带标签的示例数量少或在zero-shot设置中提供了新的实体类型时,此功能很有用。
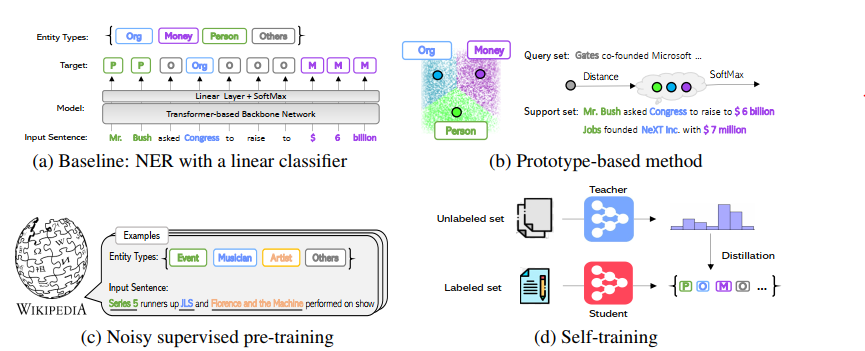
(a)一个典型的NER系统,其中线性分类器建立在诸如BERT / Roberta之类的无监督预训练基于转换器的网络之上。 (b)通过对支持集中属于给定实体类型的所有token的特征进行平均来构造原型集(例如,Person的原型是三个token的平均值:Mr.,Bush和Jobs)。 对于查询集中的token,计算其与不同原型的距离,并训练模型以最大程度地将查询令牌分配给其目标原型。 (c)Wikipedia数据集用于受监督的预训练,其实体类型相关但不同(例如,音乐家和艺术家是下游任务中人员的更细粒度类型)。 每个令牌上的关联类型可能很嘈杂。 (d)自我训练:在一个小型标签数据集上训练的NER系统(教师模型)用于预测大型未标签数据集中句子的软标签。 预测数据集和原始数据集的联合用于训练学生模型。
计算均值向量
预训练可以对许多不同种类的词一视同仁,使用了WiNer,维基百科的类型更加细粒度,有助于防止过拟合。
主要介绍了NER、原型方法、监督预训练、自训练的发展,值得借鉴学习
重要参考文献
LC是第2节中的线性分类器微调方法,即在主干上添加线性分类器,然后直接对目标数据集上的整个模型进行微调; (ii)P表示第3.1节中基于原型的方法; (iii)NSP是指第3.2节中的受噪声监督的预培训; 根据预训练目标,我们提供LC + NSP和P + NSP。 (iv)ST是第3.3节中的自训练方法,它与线性分类器微调结合,表示为LC + ST; (v)LC + NSP + ST
可以学习一下这种各种方法组合搞实验,实际上这篇文章就说了个这个,很简单的思路
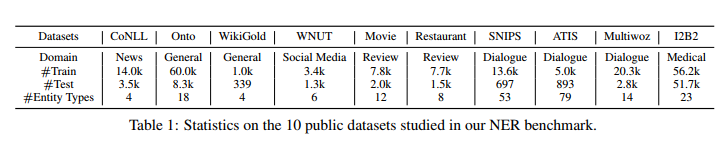
对于每个数据集,我们使用不同比例的训练数据进行三组实验:5-shot,10%和100%。 对于5-shot,我们针对训练集中每种实体类型抽取5个句子,并将每个实验重复10次。对于10%的设置,我们对训练集的10%进行下采样,对于100%的设置,我们将完整的训练集用作标记数据。 我们仅使用5-shot和10%的shot来研究自我训练方法,而将其余的训练集用作未标记的域内语料库。
在计算f1分数时,将单词级别的预测转换为实体级别的预测以进行评估。
当前针对少量NER的SoTA包括:(i)StructShot(Yang和Katiyar,2020年),该方法通过使用抽象标记过渡分布的解码过程扩展了最近邻居分类。 从源数据集OntoNotes训练模型和过渡分布。https://arxiv.org/abs/2010.02405
(ii) L-TapNet+CDT (Hou et al., 2020) 该方法使用标签名称语义构造一个嵌入投影空间,以很好地分离不同的类。 它还包括折叠的依赖关系传输机制,用于将标签依赖关系信息从源域传输到目标域。https://arxiv.org/abs/2006.05702
(iii)SimBERT是在(Yang和Katiyar,2020; Hou等,2020)中报告的简单基准; 它基于预训练的BERT输出的上下文表示,利用最近的邻居分类器,而无需微调一些示例。 StructShot论文中报告的结果使用IO模式而不是BIO模式,因此出于完整性考虑,我们在这两者上均报告了性能。
最近的两篇zero-shot著作:(i) Neighbor-tagging (Wiseman and Stratos, 2019) copies token-level labels
from weighted nearest neighbors; (ii) Examplebased NER (Ziyadi et al., 2020) is the SoTA on
training-free NER, which identifies the starting and
ending tokens of unseen entity types
我们观察到,在无训练的情况下,基于原型的基本方法无法从更多给定的示例中受益。 我们假设这是因为属于同一实体类型的标记不一定彼此靠近,并且经常在表示空间中分开。
Bert论文:https://arxiv.org/abs/1810.04805
[文献记录]Few-Shot Named Entity Recognition: A Comprehensive Study 小样本命名实体识别:全面研究(无代码)
原文:https://www.cnblogs.com/Tony100K/p/14432764.html