
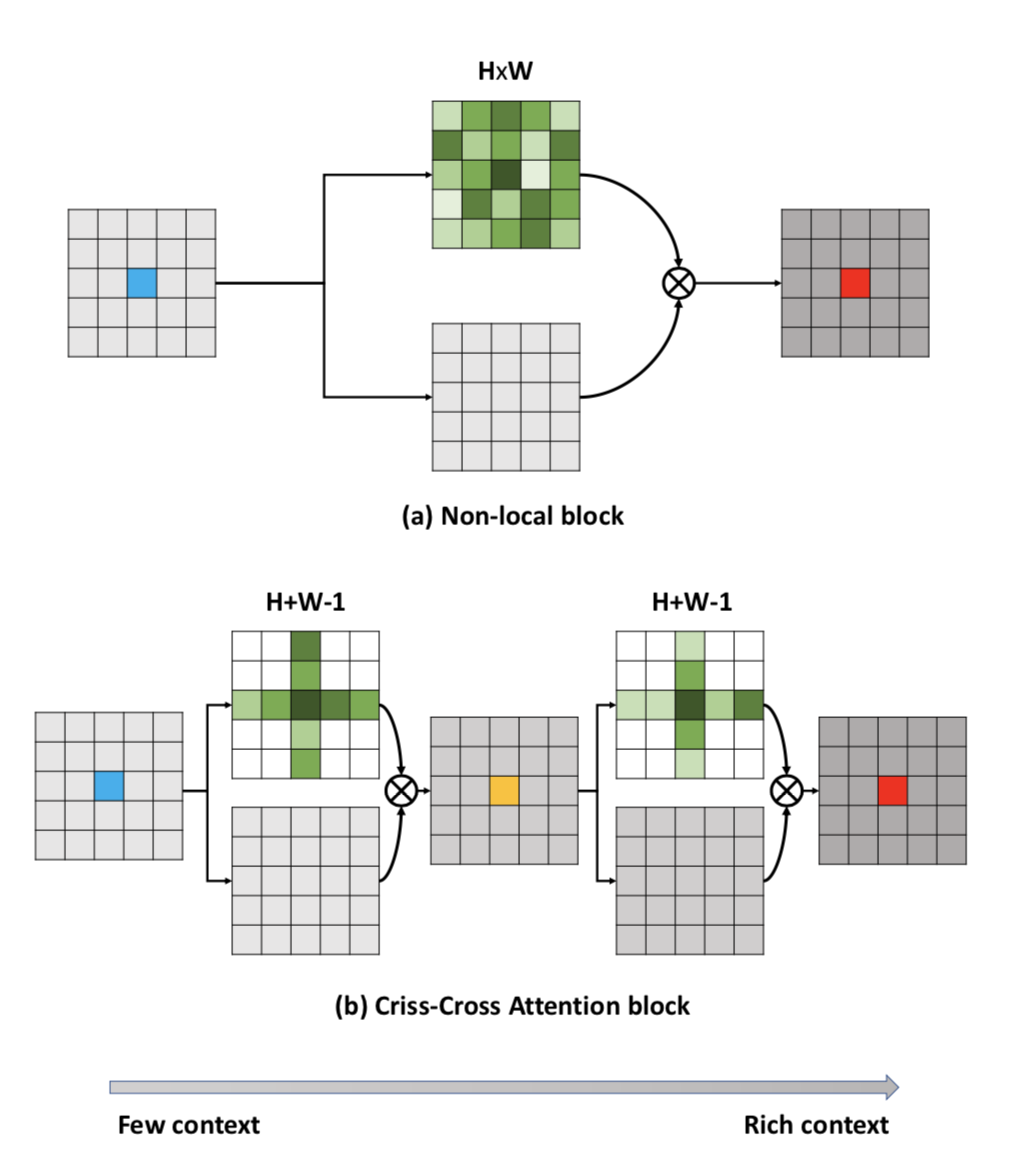
ccnet是对non-local的加速,non-local中每个位置都会计算与全局的关系,ccnet 通过多次计算当前位置与其同行或者同列的feature的关系,逐步propagation到全局。
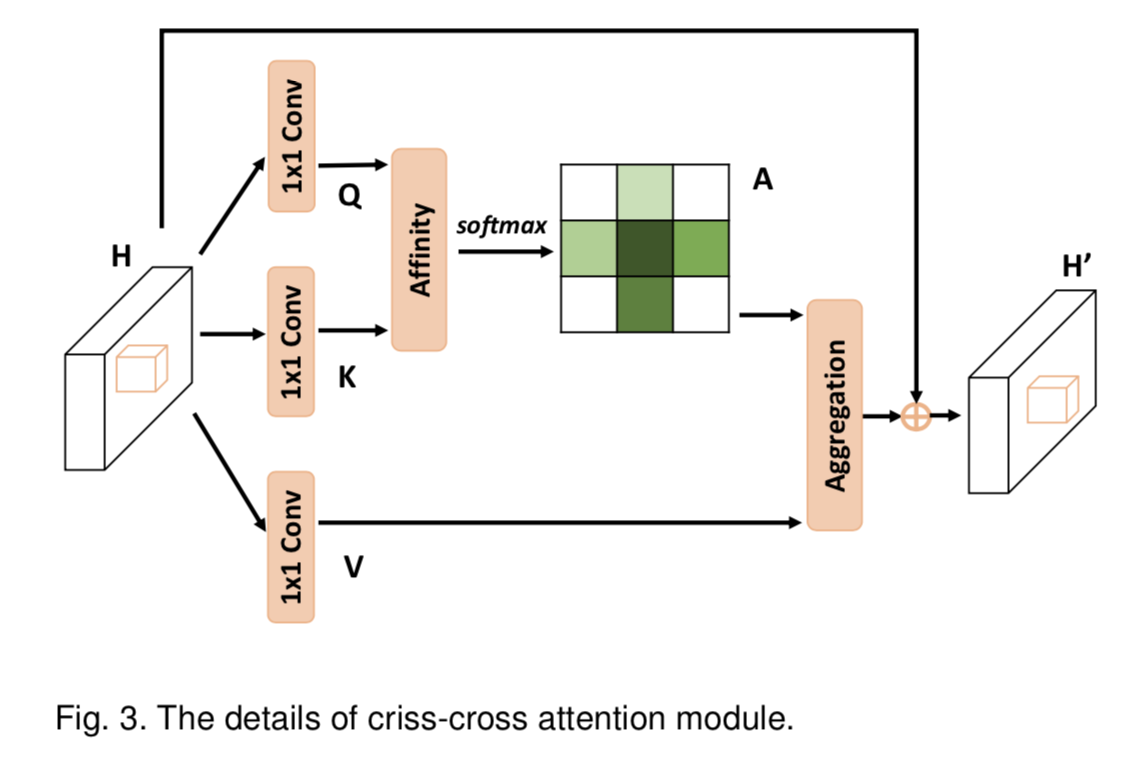
其中criss-cross attention block的结构如下:
多次叠加使用时信息的传递方式:
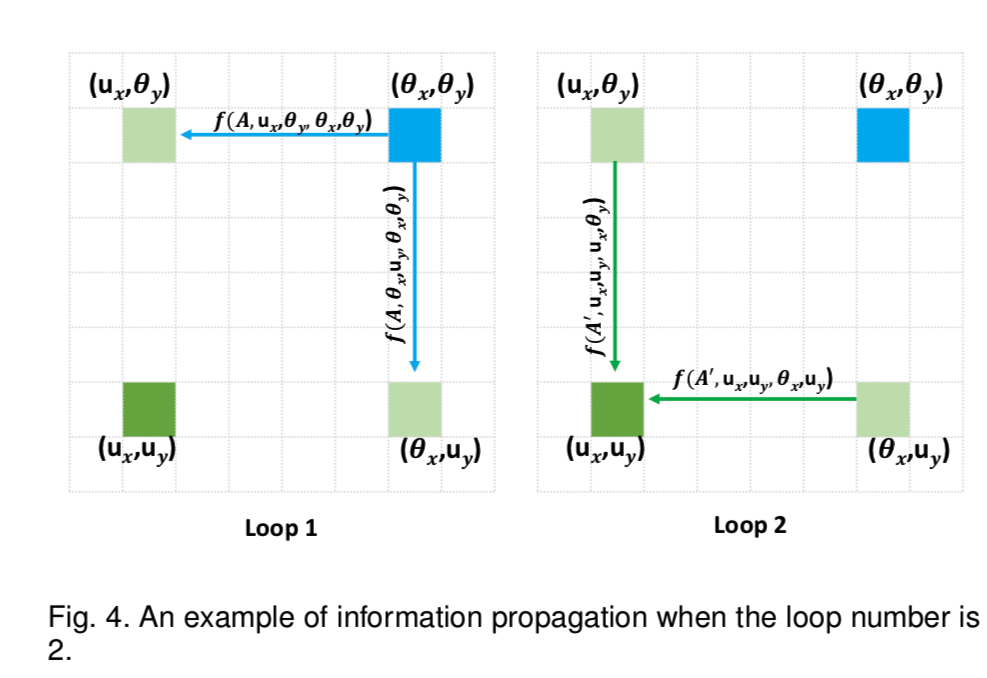
蓝色位置的信息第一次loop的时候被传递给浅绿色的位置,第二次loop的时候这些信息传递给了深绿色位置。
由于每个点只关注与(H+W-1)个点的关系,所以计算量会少。
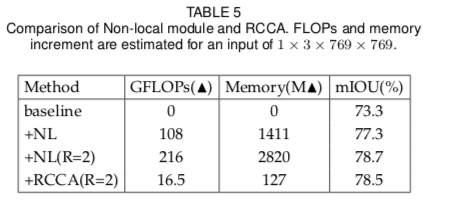
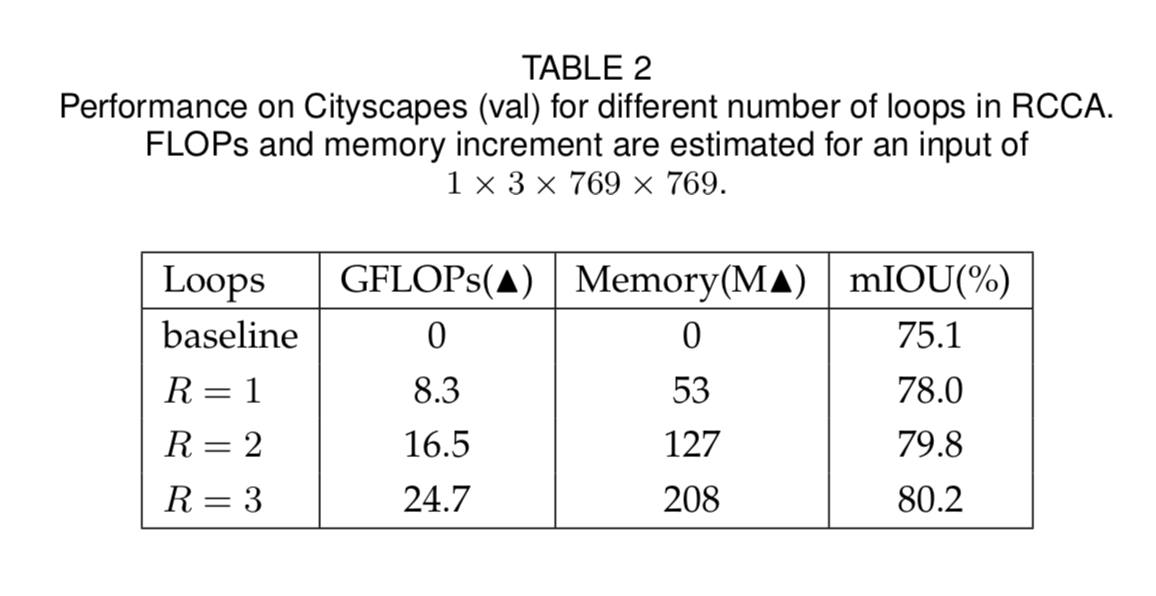
另外叠加criss-cross attention次数越多,效果越好
ccnet的实现如下
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).cuda().repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CrissCrossAttention(nn.Module):
# Criss-Cross Attention Module
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
return self.gamma*(out_H + out_W) + x
原文:https://www.cnblogs.com/treeaxx/p/14432029.html