分词的研究主要有以下几个大的方向:
- 多任务:分词和POS Tagging、依存句法分析、命名实体识别组合在一起做联合任务;
- 模型:使用最新的神经网络模型,比如ZEN采用了BERT
- 上下文特征:采用更加丰富的上下文特征(将词嵌入和子嵌入拼接);
- 多准则学习:分词的结果不是固定,根据不同的准则有不同的切分方法;
- 跨领域分词:如何尽量降低一个领域下通过监督学习得到的模型在另一个领域的性能下滑
本文根据个人看法将相关论文进行划分,五星最佳,一星最差。
三星
本文是谷歌的一篇实验味较浓的论文,并且还是一如既往地追求简单且高效,其主要贡献有两点:一是实验,给bilstm引入三项深度学习技术(预训练嵌入、dropout、超参数调参),发现在很多数据集上超过了复杂的模型;二是,提出了一些guidance,通过对错误数据进行分析发现,超纲词对神经网络模型来说仍旧是一个挑战,并且大部分错误都无法通过修改模型来纠正,进一步的提高需要把更多的精力花在探索数据资源上。
1. 模型
模型就是bilstm,输入是每个字的子嵌入和词嵌入的拼接,隐藏层单元256,标注模式采用BIES。
三项深度学习技术为:
- recurrent dropout
- hyperparameters: 使用SGD + momentum(超参数\(\mu = 0.95\)),对梯度进行归一化从而保证最大为单元范数
- pretrained embeddings: 使用wang2vec来训练character embedding和character-bigram embedding,zhou也用了这个方法来训练词向量,同时也是本文主要参考的对象。
2. 实验
数据集是有四个:CTB 6.0、CTB 7.0、UD、SIGHAN 2005。
实验结果为:
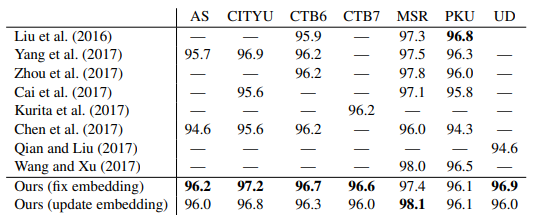
错误分析发现:三分之一是标注不一致导致,三分之二是超纲词。所以改模型基本没有很大的提升了,作者建议后面多花点心思在数据上。
3. 文章的一些其他知识点
神经网络用于学习嵌入和分词:
- Pei et al., 2014: Maxmargin tensor neural network for chinese word segmentation.
- Ma and Hinrichs, 2015: Accurate linear-time chinese word segmentation via embedding matching
- Zhang et al., 2016a: Transition-based neural word segmentation
- Liu et al., 2016: Exploring segment representations for neural segmentation models
- Cai et al., 2017: Fast and accurate neural word segmentation for chinese
- Wang and Xu, 2017: Convolutional neural network with word embeddings for chinese word segmentation
中文分词综述
原文:https://www.cnblogs.com/YoungF/p/14352170.html