在原始arxiv数据集中作者经常会在论文的comments或abstract字段中给出具体的代码链接,所以我们需要从这些字段里面找出代码的链接。
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具
import json
import time
在comments字段中抽取pages和figures和个数,首先完成字段读取
json_filename=‘D:/BaiduNetdiskDownload/archive/arxiv-metadata-oai-snapshot.json‘
data = []
with open(json_filename, ‘r‘) as f:
for idx, line in enumerate(f):
d = json.loads(line)
d = {‘abstract‘: d[‘abstract‘], ‘categories‘: d[‘categories‘], ‘comments‘: d[‘comments‘]}
data.append(d)
data = pd.DataFrame(data) #将list变为dataframe格式,方便使用pandas进行分析
# 使用正则表达式匹配,XX pages
data[‘pages‘] = data[‘comments‘].apply(lambda x: re.findall(‘[1-9][0-9]* pages‘, str(x)))
# 筛选出有pages的论文
data = data[data[‘pages‘].apply(len) > 0]
# 由于匹配得到的是一个list,如[‘19 pages‘],需要进行转换
data[‘pages‘] = data[‘pages‘].apply(lambda x: float(x[0].replace(‘ pages‘, ‘‘)))
data[‘pages‘].describe().astype(int)
out[4]: 论文平均的页数为17页,75%的论文在22页以内,最长的论文有11232页。
count 1089180
mean 17
std 22
min 1
25% 8
50% 13
75% 22
max 11232
Name: pages, dtype: int32
# 选择主要类别
data[‘categories‘] = data[‘categories‘].apply(lambda x: x.split(‘ ‘)[0])
data[‘categories‘] = data[‘categories‘].apply(lambda x: x.split(‘.‘)[0])
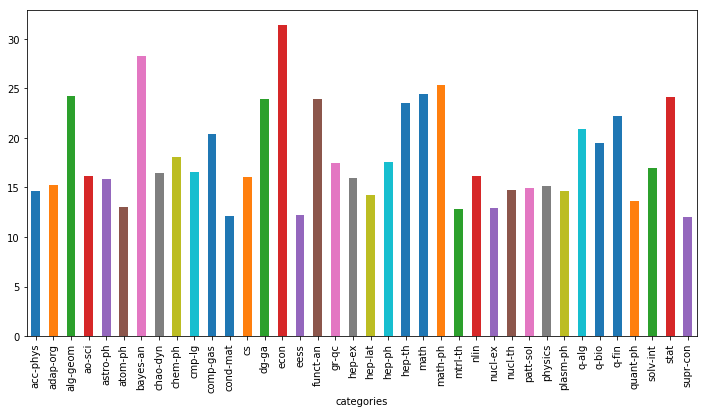
# 每类论文的平均页数
plt.figure(figsize=(12, 6))
data.groupby([‘categories‘])[‘pages‘].mean().plot(kind=‘bar‘)
<matplotlib.axes._subplots.AxesSubplot at 0x154875821d0>
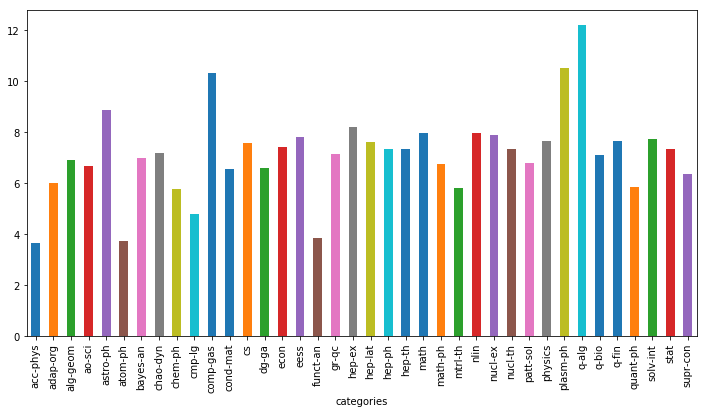
data[‘figures‘] = data[‘comments‘].apply(lambda x: re.findall(‘[1-9][0-9]* figures‘, str(x)))
data = data[data[‘figures‘].apply(len) > 0]
data[‘figures‘] = data[‘figures‘].apply(lambda x: float(x[0].replace(‘ figures‘, ‘‘)))
我们对论文的代码链接进行提取,为了简化任务我们只抽取github链接:
# 筛选包含github的论文
data_with_code = data[
(data.comments.str.contains(‘github‘)==True)|
(data.abstract.str.contains(‘github‘)==True)
]
data_with_code[‘text‘] = data_with_code[‘abstract‘].fillna(‘‘) + data_with_code[‘comments‘].fillna(‘‘)
# 使用正则表达式匹配论文
pattern = ‘[a-zA-z]+://github[^\s]*‘
data_with_code[‘code_flag‘] = data_with_code[‘text‘].str.findall(pattern).apply(len)
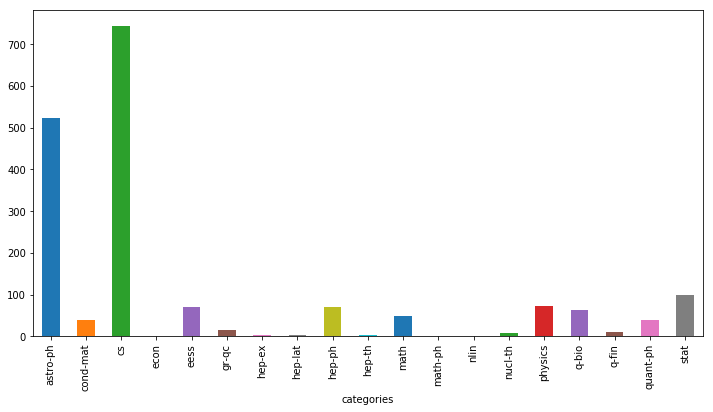
并对论文按照类别进行绘图:
data_with_code = data_with_code[data_with_code[‘code_flag‘] == 1]
plt.figure(figsize=(12, 6))
data_with_code.groupby([‘categories‘])[‘code_flag‘].count().plot(kind=‘bar‘)
<matplotlib.axes._subplots.AxesSubplot at 0x154a0511c50>
原文:https://www.cnblogs.com/Vincy-BLOG/p/14298345.html